Command Palette
Search for a command to run...
MOSS: Text-to-Spoken-Dialoggenerierung
Datum
Größe
8.4 MB
Tags
Lizenz
Apache 2.0
GitHub
Paper-URL
1. Einführung in das Tutorial

Dieses Tutorial verwendet eine einzelne RTX 5090-Karte als Ressource.
2. Projektbeispiele
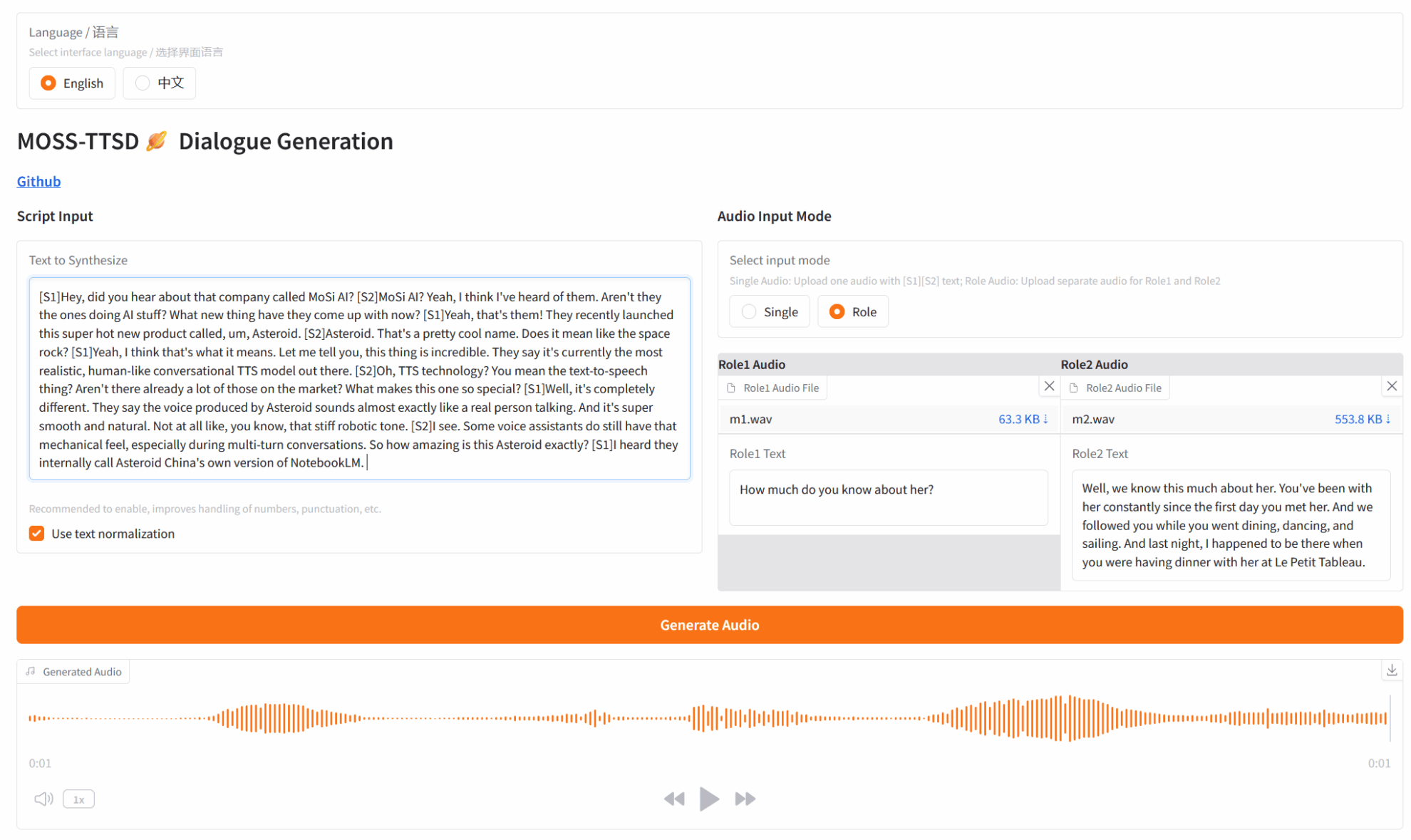
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
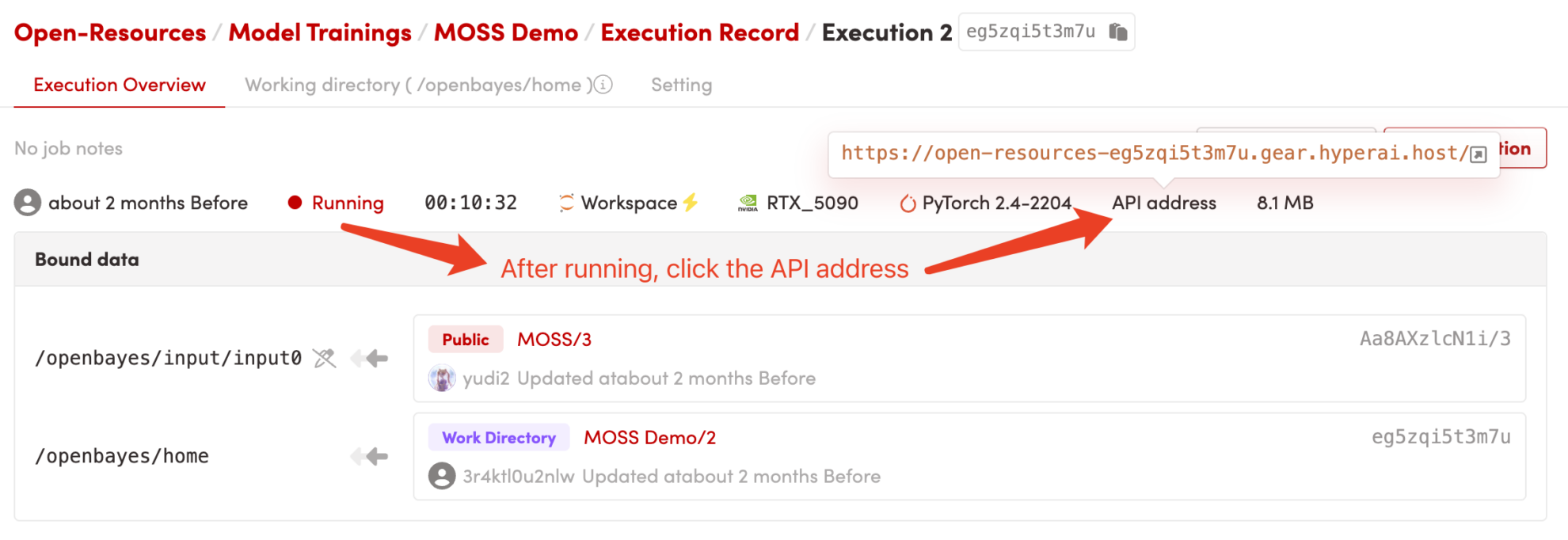
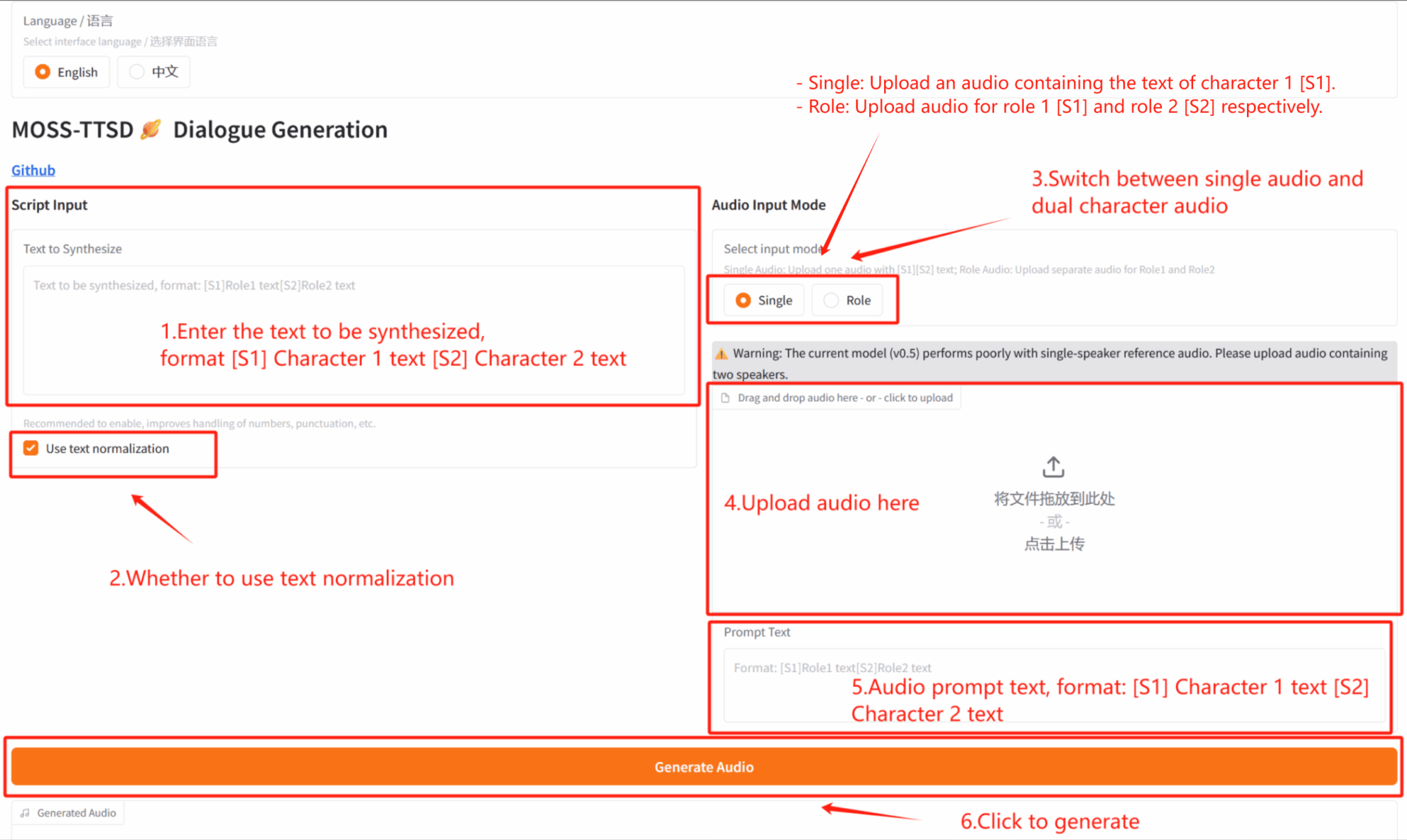
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite. Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
*In diesem Tutorial können Sie im „Audioeingabemodus“ zwischen der Audiogenerierung für einen Einzelspieler (Single) und der Audiogenerierung für Dialoge für zwei Spieler (Rolle) wählen.
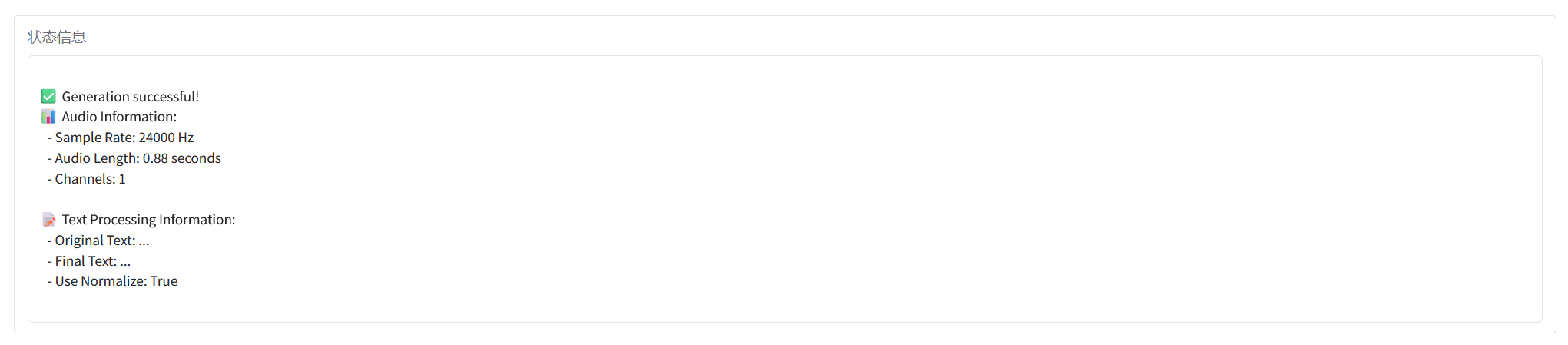
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{moss2025ttsd,
title={Text to Spoken Dialogue Generation},
author={OpenMOSS Team},
year={2025}
}KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.