Command Palette
Search for a command to run...
Neurale Zertifikatspreisfindung für kombinatorische Optimierungsprobleme
Neurale Zertifikatspreisfindung für kombinatorische Optimierungsprobleme
Jingyi Chen Xinyuan Zhang Xinwu Qian
Zusammenfassung
Kombinatorische Optimierungsprobleme (CO) sind schwierig, weil die zertifizierbare diskrete Struktur eine exponentielle Suche erzwingt. Man muss über die Menge exponentiell vieler Kandidaten suchen, um Optimalität zu zertifizieren, jedoch kann die strukturelle Zulässigkeit eines Pfades, Packens oder einer Überdeckung in polynomieller Zeit überprüft werden, sobald sie bereitgestellt wird. In dieser Studie führen wir Neural Certificate Pricing (NCP) ein, das diese Asymmetrie unter einem unüberwachten Lernrahmen ausnutzt. Ein neuronales Netzwerk wird trainiert, um zertifikatsbezogene duale Preise vorherzusagen, während eine strukturierte Wiederherstellungsschicht das induzierte primale Marginal konstruiert. NCP kann als amortisierte Separation betrachtet werden: Anstatt verletzte Ungleichungen aufzuzählen, lernt es die residualen Preise, durch die deren aggregierter Effekt in die Wiederherstellung eingeht. Wenn die Zertifikatskonsistenzbedingung erfüllt ist, ist das wiederhergestellte Marginal global zulässig, und eine lokale Theorie zeigt, dass Fehler erster Ordnung im vorhergesagten Preis nur einen Verlust zweiter Ordnung im Zielfunktionswert verursachen. Über drei Klassen von CO-Problemen hinweg übertrifft NCP entweder moderne neuronale Baselines mit großem Abstand oder erreicht sie bei einem Bruchteil der Rechenzeit und zeigt eine stärkere Generalisierung außerhalb der Verteilung.
One-sentence Summary
Researchers at Rice University introduce Neural Certificate Pricing (NCP), an unsupervised learning framework that predicts certificate-level dual prices and uses a structured recovery layer to amortize separation for combinatorial optimization, achieving global feasibility under a certificate-consistency condition and first-order error robustness, either outperforming state-of-the-art neural baselines by large margins or matching them at a fraction of the computation time across three problem classes, and showing stronger out-of-distribution generalization.
Key Contributions
- Neural Certificate Pricing (NCP) trains a neural network to predict certificate-level dual prices and uses a structured recovery layer to produce a feasible primal marginal in an unsupervised manner; the process is an amortized separation that learns residual prices whose aggregate effect enters recovery without enumerating violated inequalities.
- A local stability result proves that, under a certificate-consistency condition, the recovery is smooth and first-order errors in the predicted prices lead to only second-order degradation in the primal objective value near a primal-realizing point.
- Across three combinatorial optimization problem classes, NCP outperforms state-of-the-art neural baselines by large margins or matches them at a fraction of the computation time, and demonstrates stronger out-of-distribution generalization.
Introduction
Combinatorial optimization on graphs underpins decision-making in networked systems, where local choices must satisfy global coupling constraints, creating an exponential search space. Classical solvers rely on structured search, while recent learning-based methods predict solution components such as scores, policies, or relaxed marginals, leaving the certification of global validity to a separate downstream decoding or repair step. This separation overlooks the inherent asymmetry that a candidate solution can be verified efficiently even when finding it is hard. The authors introduce neural certificate pricing (NCP), an unsupervised framework that learns to generate pricing signals for a certificate-conditioned recovery layer. By representing discrete objects in a marginal space that isolates local consistency, certificate-induced structure, and retained coupling constraints, NCP uses the pricing signal to directly recover a certificate-consistent primal marginal, allowing training to optimize the original objective without requiring labeled solutions and transforming certification from a post-hoc check into an integral solution mechanism.
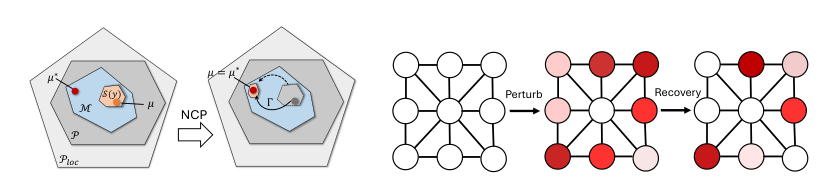
Method
The authors propose Neural Certificate Pricing (NCP), a framework that solves combinatorial optimization problems over graph-based structures by learning a cost perturbation that tightens a tractable certificate-conditioned recovery. The starting point is the free-energy formulation p⋆(G)=minμ∈MGFG(μ) over the exact marginal polytope MG, where FG(μ)=⟨c,μ⟩−τHM(μ). Direct optimization over MG is intractable, and typical relaxations PG (local constraints plus a set of explicit global coupling constraints AGμ≤bG) are often loose. The key insight is that while characterizing the full polytope is hard, certifying that a particular marginal vector μ belongs to MG can be much easier if one has a structural certificate y∈YG that induces a tractable recovery set SG(y)⊆Ploc(G). For many combinatorial problems, such certificates are naturally available: node potentials induce an acyclic order for routing, reduced-cost structures restrict assignments to local subproblems, and conflict or clique covers simplify packing constraints. When explicit coupling constraints are absent, SG(y)⊆MG holds directly; otherwise, dual prices λ≥0 for AGμ≤bG are used together with y to maintain feasibility.
NCP augments this certificate mechanism with a learned cost perturbation Γ∈R∣E∣, which plays the role of a residual pricing signal that can tighten the recovery beyond what is achievable by Lagrange multipliers alone. For a fixed certificate y, dual variables λ, and perturbation Γ, the primal recovery map is defined as
QG(Γ,y,λ)=argμ∈SG(y)min{FG(μ)+⟨Γ+AG⊤λ,μ⟩}.When SG(y) is contained in MG, every recovered μ^ yields a valid primal bound FG(μ^) for the original problem. The perturbation Γ acts as a substitute for the prices of valid inequalities that are omitted from the tractable recovery set. Proposition 3.2 formalizes this: if a certificate y covers an optimizer μ∗ and the omitted inequalities are BGμ≤dG, then setting Γ∗=BG⊤z∗ (where z∗ are the KKT multipliers for those constraints) guarantees μ∗∈QG(Γ∗,y,λ∗). Thus, learning a suitable Γ can in principle recover the exact optimum.
To ensure that the output of the recovery map is a feasible marginal, the framework requires a certificate consistency condition. Let CG be a certificate readout map that extracts a certificate from a marginal vector. A pair (y,λ) is called a consistent certificate at perturbation Γ if
y=CG(μ^),AGμ^≤bG,λ≥0,λ⊤(AGμ^−bG)=0,where μ^=QG(Γ,y,λ). Proposition 3.3 shows that under consistency, μ^∈MG and the recovered point satisfies a shifted optimality condition FG(μ^)−FG(ν)≤⟨Γ,ν−μ^⟩ for any ν∈SG(y)∩PG. This turns the search for a good perturbation into an equilibrium-constrained problem: find Γ,y,λ that minimize FG(μ) subject to y=CG(μ), μ∈QG(Γ,y,λ), and the KKT complementarity 0≤λ⊥bG−AGμ≥0. This oracle characterization (OC) is a bi-level program; any feasible solution provides a primal bound because μ is a valid marginal.
NCP amortizes this search across instances by training a neural network Γθ(G) to predict the perturbation directly from the instance G. For a given θ, the forward pass solves the consistency system via a damped projected fixed-point iteration. Starting from an initial certificate guess z0=(y0,λ0), the update is
μt+1=QG(Γθ(G),yt,λt),zˉt+1=(CG(μt+1),Dρ(λt,μt+1)),zt+1=(1−α)zt+αzˉt+1,where Dρ(λ,μ)=ΠR+mG[λ+ρ(AGμ−bG)] is a projected dual ascent step, ρ>0 is a step size, and α∈(0,1] is a damping factor that stabilizes convergence without changing fixed points. At convergence, the recovered marginal is μθ(G)=QG(Γθ(G),y⋆,λ⋆), and the unsupervised training loss is simply
LNCP(θ)=EG∼D[FG(μθ(G))],evaluated under the unperturbed objective FG (the perturbation is used only within recovery and consistency). Gradients are computed by implicit differentiation through the certificate-consistency fixed point, circumventing the need to backpropagate through many iterations.
The theoretical analysis justifies this learning scheme by revealing a favorable local structure. At a regular OC solution where strict complementarity holds for the explicit coupling constraints and the implicit function theorem applies, the bi-level problem locally reduces to an unconstrained smooth minimization of ΦG(Γ)=FG(μ^G(zΓ,Γ)), where zΓ is the implicit solution of the consistency equalities. Theorem 4.1 shows that stationary points of ΦG coincide with KKT stationary points of the local equality-constrained OC. Moreover, Theorem 4.2 establishes second-order value stability: around a stationary perturbation, a mismatch of order ε in Γ causes only an O(ε2) change in the objective. Corollary 4.3 decomposes the suboptimality gap relative to the true optimum p⋆(G) into a structural certificate gap Δcert and a local optimization residual. If the certificate family is compatible with the underlying discrete structure and the network learns a Γ within a neighborhood of a stationary point, the residual term is O(ε2), and when the conditions of Proposition 3.2 are met, the certificate gap vanishes as well. This analysis explains why NCP can recover near-optimal primal bounds: the training objective concentrates on a smooth landscape where approximate consistency translates into small value errors.
Experiment
Across three combinatorial optimization problems (maximum independent set, generalized assignment, and elementary shortest path) evaluated under out-of-distribution conditions, NCP demonstrates robustness to changing objectives and scaling to larger instances while maintaining efficiency comparable to single-pass methods. Ablation studies confirm that the structure certificate and learned perturbation are essential, and learning shifts the primal gap below the canonical Lagrangian bound. The reduced objective exhibits second-order stability near stationary perturbations, aligning with theoretical predictions and supporting stable optimization.
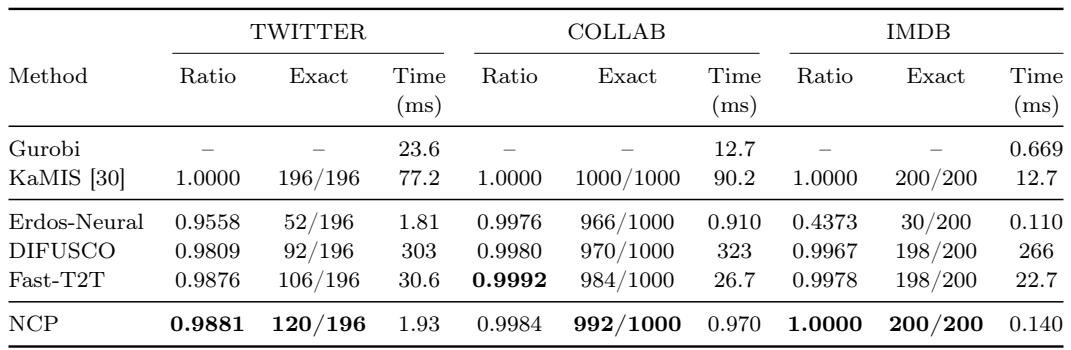
On unweighted maximum independent set benchmarks, NCP achieves near-optimal ratios and solves most instances exactly while keeping inference time close to the fastest single-pass methods. In contrast to other neural baselines, NCP remains robust across all three graphs, most notably on IMDB where it matches the exact solver KaMIS with perfect score and far lower latency than diffusion or iterative approaches. NCP recovered the exact solution on all 200 IMDB instances, equaling KaMIS, whereas Erdos-Neural solved only 30 and Fast-T2T solved 198. On TWITTER, NCP obtained a ratio of 0.9881 and exact count of 120/196 in 1.93 ms, outperforming Erdos-Neural, DIFUSCO, and Fast-T2T while being over 150× faster than DIFUSCO.
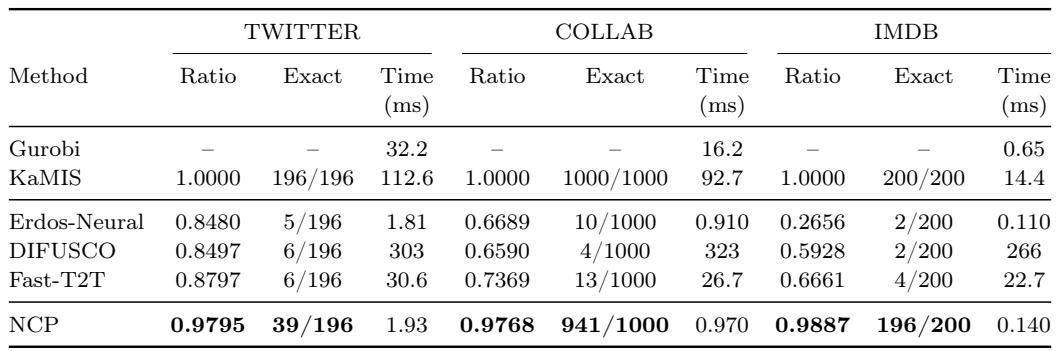
On the weighted maximum independent set task, NCP maintains an approximation ratio above 0.97 across all three benchmarks and recovers the exact solution in the majority of instances. Neural baselines Erdos-Neural, DIFUSCO, and Fast-T2T experience sharp performance drops on the larger graphs COLLAB and IMDB, while NCP remains robust and delivers inference in sub-millisecond to low-millisecond times. NCP achieves ratios of 0.9795 (TWITTER), 0.9768 (COLLAB), and 0.9887 (IMDB) and exactly solves 39/196, 941/1000, and 196/200 instances, respectively. On COLLAB and IMDB, Erdos-Neural drops to a ratio of 0.67 and 0.27, DIFUSCO to 0.66 and 0.59, and Fast-T2T to 0.74 and 0.67, showing the vulnerability of these methods to weighted objectives. NCP's inference time stays under 2 ms on TWITTER, under 1 ms on COLLAB, and 0.14 ms on IMDB, combining high solution quality with single-pass-like speed.
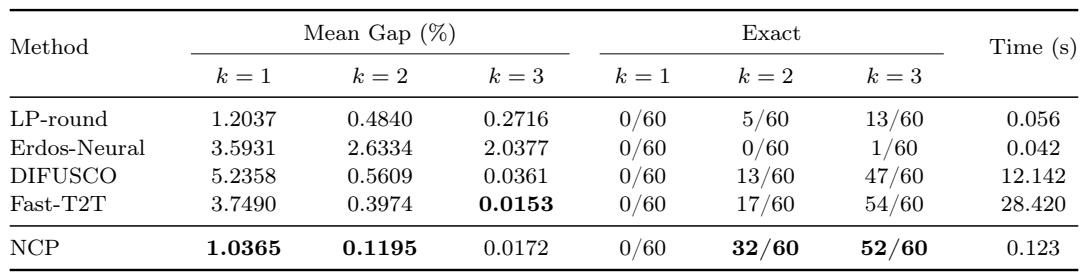
NCP achieves the lowest mean optimality gap for top-1 and top-2 masks on the GAP benchmark, outperforming the LP-round baseline. For top-3 masks, its gap is nearly equal to the best competitor while cutting runtime by more than two orders of magnitude. The method also solves more instances exactly at k=2 than other neural approaches, indicating that its learned certificate produces a compact candidate set with near-optimal LP solutions. NCP attains the best mean gap for k=1 and k=2, and for k=3 its gap is almost identical to Fast-T2T while running over 200 times faster. At k=2, NCP exactly solves 32 of 60 instances, compared to 17 for Fast-T2T and 13 for DIFUSCO. NCP consistently improves over LP-round for all k, demonstrating the value of its learned certificate.
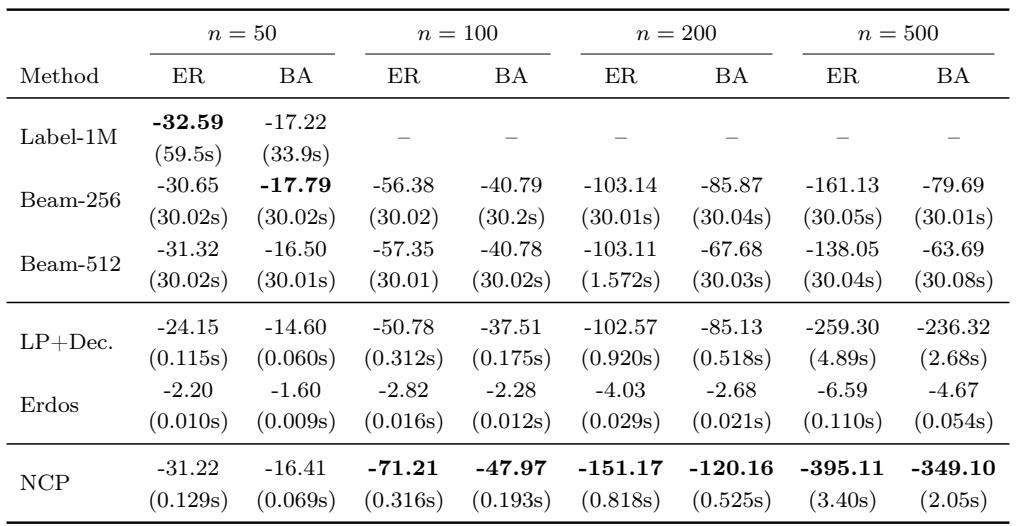
On ER and BA graphs, NCP reaches path costs close to the intensive labeling method at small sizes and consistently outperforms LP+Dec. and beam search baselines as graph size grows. Its runtime stays within a few seconds, making it far faster than labeling and beam search, both of which require tens of seconds per instance. The performance gap widens with larger graphs, reflecting the scalability of the learned certificate structure. At n=50, NCP's cost is only slightly behind Label-1M (e.g., -31.22 vs. -32.59 on ER) while cutting inference time from tens of seconds to under 0.13 seconds. On larger graphs where labeling is unavailable, NCP consistently achieves the best path costs among all scalable methods, substantially beating LP+Dec. and beam search. The advantage over LP+Dec. becomes much more pronounced as graph size increases: at n=500 on ER, NCP attains a cost of -395.11 while LP+Dec. reaches only -259.30.
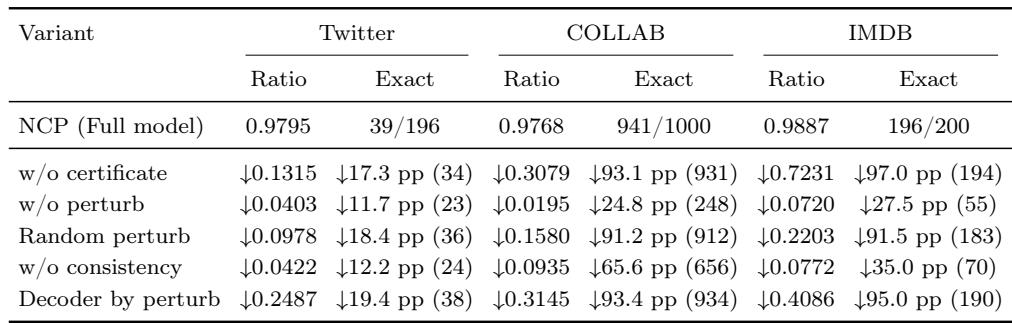
Ablation of the NCP components on weighted maximum independent set shows that the structure certificate is essential: removing it results in the largest performance drop on IMDB and COLLAB, with ratio decreases up to 0.724 and nearly all exact solutions lost. Recovering the primal directly from the perturbation (Decoder by perturb) causes the highest ratio degradation on Twitter and competitive with certificate removal on COLLAB, confirming that the primal signal is reconstructed through the learned mapping, not from Γ alone. Learned certificate perturbations outperform random perturbations, and removing the consistency loss significantly degrades exact solve counts, highlighting the importance of certificate consistency. Removing the structure certificate slashes the ratio by 0.724 on IMDB and 0.308 on COLLAB, with exact solves dropping from 196 to 2 and from 941 to 10, respectively. Decoding directly from Γ degrades the ratio by 0.249 on Twitter and 0.409 on IMDB, causing the largest ratio loss on Twitter and reducing exact solves from 196 to 6 on IMDB. Randomizing the perturbation reduces exact solves by 912 on COLLAB and 183 on IMDB, underperforming the learned certificate perturbation and demonstrating that structured perturbations are crucial. Removing the perturbation entirely (w/o perturb) causes milder degradation (exact drop of 248 on COLLAB) than random perturbation, but still hurts performance, underscoring the need for a learned adaptation. Ablating certificate consistency leads to exact solve drops of 656 on COLLAB and 70 on IMDB, far worse than removing the perturbation, indicating that consistency guides effective primal recovery.
The evaluation spans maximum independent set (unweighted and weighted), the GAP benchmark, and path planning on synthetic graphs, validating NCP's solution quality and speed against exact solvers and neural baselines. NCP consistently achieves near-optimal results, often matching exact solvers while maintaining single-pass-like inference, and it remains robust on larger and weighted instances where other learning-based methods degrade sharply. The learned structure certificate is essential for performance, with ablations confirming that removing it or bypassing the primal recovery drastically reduces accuracy, while consistency loss further stabilizes learning. Overall, NCP delivers a compelling combination of accuracy, speed, and scalability across diverse combinatorial optimization tasks.