Command Palette
Search for a command to run...
Zur Nichtlinearität der Lernratenskalierung beim Training großer Sprachmodelle
Zur Nichtlinearität der Lernratenskalierung beim Training großer Sprachmodelle
Zaiwen Yang Huaqing Zhang Jing Xu Jingzhao Zhang
Zusammenfassung
Lernratentransfer kann die Kosten für das Training großer Sprachmodelle senken: Anstatt die Lernrate im Zielmaßstab zu durchsuchen, extrapolieren Praktiker aus kleineren Experimenten. Bestehende Ansätze gehen oft davon aus, dass die optimale Lernrate einem log-linearen Skalierungsgesetz in Bezug auf Datengröße und Modellgröße folgt. Wir überprüfen und bewerten dieses Skalierungsgesetz sorgfältig. In unserer empirischen Studie mit GPT-2-ähnlichen Modellen von 22M bis 707M Parametern, die auf 5B bis 100B Token trainiert wurden, entwickelt die optimale Lernrate bei größeren Skalen eine Aufwärtskrümmung, was zu ungenauer Extrapolation führt. Wir stellen fest, dass diese Krümmung weitgehend verschwindet, wenn die Lernrate durch die effektive Lernrate (die Schrittweite im normalisierten Gewichtsraum) ersetzt wird und wenn die Datenextrapolation D anstelle der Modellgrößenextrapolation N verwendet wird. Anschließend erklären wir die Nichtlinearität in der Skalierung: Die Gewichtsnorm konvergiert langsamer zum Gleichgewicht, wenn die optimale Lernrate klein ist, was eine größere Schrittweite erfordert, um die Übergangsphase zu verkürzen. Experimente mit AdamH, das die effektive Lernrate direkt steuert, stützen diese Erklärung zusätzlich.
One-sentence Summary
Researchers from Tsinghua University and Shanghai Qi Zhi Institute find that the optimal learning rate for GPT-2-style models (22M to 707M parameters) trained on 5B to 100B tokens develops nonlinear upward curvature at larger scales, leading to inaccurate extrapolation, but this curvature largely disappears when using an effective learning rate—the step size in normalized weight space—and extrapolating on data D rather than model size N, which they explain by slower weight-norm convergence at small learning rates, with AdamH experiments further supporting this explanation.
Key Contributions
- The paper reveals that optimal learning rate scaling laws exhibit upward curvature at larger scales in GPT-2-style models (22M–707M parameters, 5B–100B tokens), leading to systematic underprediction when extrapolating from smaller runs.
- Two changes substantially improve learning-rate transfer: parameterizing by the effective learning rate (step size in normalized weight space) and extrapolating along the data axis, the latter incurring only 2% extra training compute relative to using the true optimal rate.
- A mechanistic explanation for this curvature is provided: under AdamW, weight-norm dynamics converge more slowly when the optimal learning rate is small, requiring a larger effective step to reduce the transient phase, and AdamH experiments that directly control the effective learning rate further support this interpretation.
Introduction
Efficiently training large language models hinges on well-tuned learning rates, but grid search at the target scale is prohibitively expensive, making hyperparameter transfer from small-scale runs essential. Prior work includes maximal update parameterization (μP), which stabilizes the optimal learning rate under width scaling but can break when weight norms drift and does not cover data-size transfer, while other approaches fit log‑linear scaling laws relating the optimal learning rate to model size and data size. Those power‑law fits, however, have not been rigorously evaluated for extrapolation accuracy or fitting cost. The authors systematically study learning‑rate transfer across model and data scales, showing that log‑linear extrapolation underpredicts the optimal learning rate at larger scales due to an upward curvature, whereas the effective learning rate—the per‑step change in normalized weight direction—displays more linear scaling. They demonstrate that fitting scaling laws along the data axis yields far more accurate predictions than fitting along the model axis, and they offer a mechanistic explanation based on AdamW weight‑norm dynamics, validated by an optimizer that directly controls the effective learning rate.
Method
The authors investigate the scaling behavior of learning rates in large language models, focusing on the relationship between the optimal learning rate, dataset size D, and model size N. They define the optimal learning rate η∗(D,N) as the value that minimizes the target loss L after training on D tokens with a model of scale N: η∗(D,N):=ηargminL(wT(η;D,N)). Previous works assume a log-linear scaling law for this optimal learning rate: logη∗(D,N)=alogD+blogN+c, implying a power law relationship η∗(D,N)∝DaNb.
To better understand the optimization dynamics, the authors introduce the concept of the effective learning rate. Since modern architectures like Transformers are often scale-invariant with respect to their weights due to normalization layers, the loss remains unchanged under weight rescaling. Consequently, optimization dynamics depend primarily on the direction of the weights. The effective learning rate is defined as the step size in the normalized parameter space: ηeff(t)=∥w^t+1−w^t∥2, where w^t=wt/∥wt∥2 is the normalized weight vector. Because the effective learning rate varies slowly during training when the learning rate is fixed, it can be approximated by its average over the training process. The optimal effective learning rate ηeff∗(D,N) is then defined as the average effective learning rate induced by the optimal learning rate η∗(D,N).
The authors explain the nonlinear scaling of the standard learning rate by analyzing the implicit effective learning rate schedule. They observe that the optimal effective learning rate extrapolates more reliably than the standard learning rate for large training horizons. This is because the effective learning rate, rather than the standard learning rate, governs the optimization dynamics due to scale-invariance.
When training with Adam without weight decay, the effective learning rate decays over time. For sufficiently large learning rates, the accumulated step size converges to the same trajectory regardless of the initial learning rate, leading to similar validation losses. However, when using AdamW, the equilibrium of weight norms plays a crucial role. The time required for the weight norm to reach equilibrium creates two distinct regimes for the effective learning rate.
As shown in the figure below:
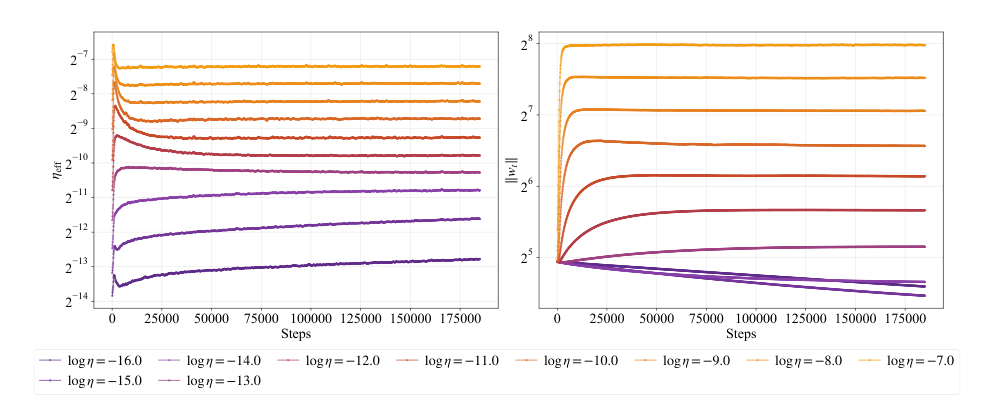
The effective learning rate exhibits two asymptotic regimes under AdamW. In the equilibrium regime, where the training time is much larger than the decay time (2ηλ)−1, the effective learning rate is proportional to the square root of the learning rate (ηeff∝η). In the pre-equilibrium regime, where the training time is much smaller than the decay time, the effective learning rate is directly proportional to the learning rate (ηeff∝η). Smaller learning rates relax more slowly toward equilibrium, remaining in the pre-equilibrium regime. As the training horizon grows, the optimal learning rate decreases, pushing the training from the equilibrium regime into the pre-equilibrium regime, which explains the upward curvature in the scaling law.
To address the irregularity in the standard learning rate scaling, the authors propose AdamH, an optimizer that explicitly controls the effective learning rate. Instead of letting the effective learning rate emerge implicitly from optimizer dynamics, AdamH normalizes both the weight and the update to a fixed norm.
Refer to the framework diagram:
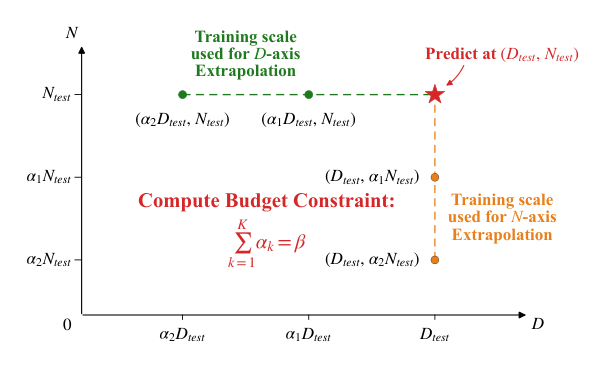
The diagram illustrates the compute-constrained extrapolation strategy used to evaluate scaling laws. The D-axis extrapolation uses reduced data with the full model, while the N-axis extrapolation uses smaller models with full data, both under a fixed compute budget. This framework allows the authors to test the extrapolation reliability of different learning rate definitions.
Under AdamH, the scaling analysis recovers a clean log-linear relationship logηeff∗∝logD.
As shown in the figure below:
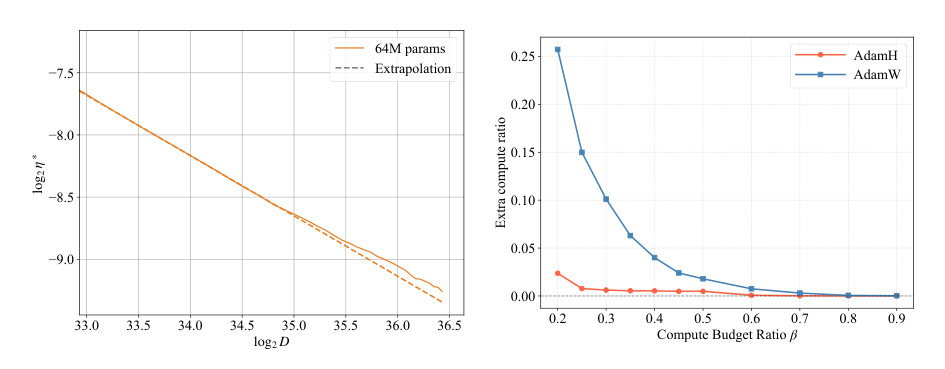
AdamH exhibits a clear scaling relationship with a high Pearson coefficient. Furthermore, when comparing the extra compute ratio for a target model and dataset size, AdamH achieves a much smaller extra compute ratio than AdamW at small compute-budget ratios. This indicates that AdamH follows a more linear scaling law, making it more suitable for compute-constrained extrapolation.
Experiment
The study evaluates log-linear scaling laws for optimal learning rates and effective learning rates across varying model sizes and data budgets using GPT-2 models. While the nominal learning rate exhibits systematic curvature, the effective learning rate follows a more linear log-log relationship, particularly when scaling with data rather than model size, yielding more reliable extrapolation. This nonlinearity stems from a regime transition in AdamW's dynamics, and the excess compute cost due to extrapolation error scales linearly with prediction inaccuracy. Overall, predicting the optimal effective learning rate along the data axis provides the most accurate and compute-efficient scaling predictions.
Fitting the effective learning rate along the data dimension gives consistently better extrapolation than fitting the raw learning rate. Across budget ratios from 13% to 21%, the D-dimensional effective learning rate setup yields validation loss gaps under 6×10^{-4} and extra compute ratios below 1.3%, while the raw learning rate produces loss gaps an order of magnitude higher and extra compute ratios up to 17%. Even N-dimensional effective learning rate fitting at 20.64% budget underperforms its D-dimensional counterpart, highlighting the value of parameterizing the data axis with the effective learning rate. D-dimensional effective learning rate fitting keeps the validation loss gap between 4.1 and 5.1 ×10^{-4}, while raw learning rate fitting inflates the gap to 33–66 ×10^{-4}. The extra compute ratio is minimized by D-dimensional effective learning rate fitting at every budget ratio, requiring only 1.0–1.3% more compute, compared to 8.7–17% for the raw learning rate.
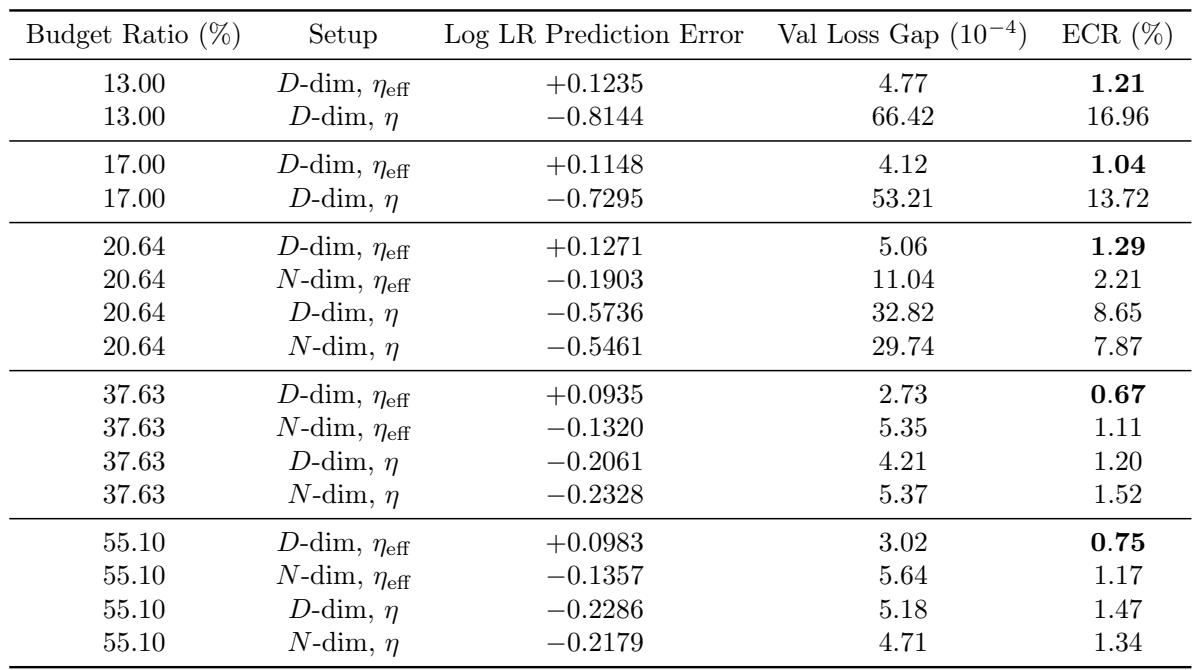
Fitting an effective learning rate along the data dimension (D‑dimensional) consistently improves extrapolation compared to using a raw learning rate or an N‑dimensional effective learning rate. Across multiple budget ratios, the D‑dimensional parameterization yields validation loss gaps that are an order of magnitude smaller and requires only slightly more compute, while the raw learning rate incurs substantially larger loss gaps and extra compute overhead. These results highlight that parameterizing the data axis with an effective learning rate is crucial for accurate and efficient scaling-law extrapolation.