Command Palette
Search for a command to run...
Qwen-Image-2.0-RL Technischer Bericht
Qwen-Image-2.0-RL Technischer Bericht
Zusammenfassung
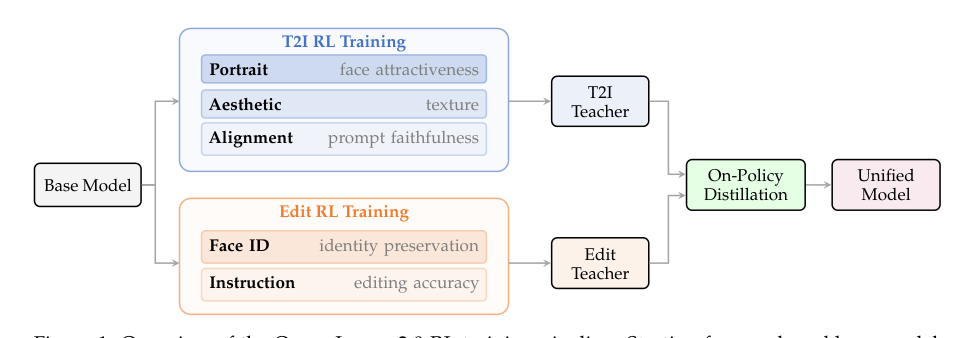
Wir präsentieren Qwen-Image-2.0-RL, eine Post-Training-Pipeline, die Reinforcement Learning from Human Feedback (RLHF) und On-Policy Distillation (OPD) einsetzt, um sowohl die visuelle Qualität als auch die Fähigkeit zur Befehlsbefolgung des Qwen-Image-2.0-Diffusionsmodells zu verbessern. Um zuverlässige Belohnungssignale bereitzustellen, konstruieren wir aufgabenspezifische zusammengesetzte Belohnungsmodelle, indem wir Vision-Language-Modelle mit einem punktweisen Bewertungsparadigma und Chain-of-Thought-Reasoning feinabstimmen. Für die Text-zu-Bild-Generierung decken die Belohnungsmodelle die Dimensionen Ausrichtung, Ästhetik und Porträttreue ab. Für Bildbearbeitungsaufgaben adressiert das Belohnungssystem die Genauigkeit der Befehlsbefolgung und die Bewahrung der Gesichtsidentität. Aufbauend auf diesem Belohnungssystem entwickeln wir ein skalierbares GRPO-basiertes RL-Trainingsframework, das eine hybride Classifier-Free Guidance (CFG)-Strategie zur Bewahrung vortrainierten Wissens, eine Prompt-Kuration durch Intra-Group Reward Range Filtering und eine kategorieweise Kalibrierung der Belohnungsgewichte integriert. Um die aufgabenspezialisierten RL-Policies für T2I und Bearbeitung zusammenzuführen, schlagen wir On-Policy Distillation als finale Trainingsstufe vor, die mehrere Lehrer durch Trajektorien-Level Velocity Matching in einem einzigen Schülermodell konsolidiert. Umfangreiche Evaluierungen zeigen, dass Qwen-Image-2.0-RL einen Gesamtscore von 57,84 auf Qwen-Image-Bench erreicht (+2,61 gegenüber dem Basismodell), Elo-Bewertungen von 1193 in der Text-zu-Bild-Arena (+78) und 1349 in der Bildbearbeitungs-Arena (+93), was konsistente Verbesserungen in ästhetischer Qualität, Prompt-Treue und Bearbeitungsgenauigkeit belegt.
One-sentence Summary
The authors propose Qwen-Image-2.0-RL, a post-training pipeline that applies reinforcement learning from human feedback (RLHF) with composite reward models fine-tuned via pointwise scoring and chain-of-thought reasoning and on-policy distillation through trajectory-level velocity matching, unifying text-to-image and image editing improvements and achieving a +2.61 overall score on Qwen-Image-Bench and Elo ratings of 1193 for text-to-image and 1349 for image editing.
Key Contributions
- A VLM-based composite reward system is constructed for both text-to-image and image editing tasks by fine-tuning vision-language models with pointwise scoring and chain-of-thought reasoning, covering aesthetic quality, prompt adherence, portrait fidelity, instruction-following, and visual consistency.
- A scalable GRPO-based RL training framework is developed with a hybrid CFG strategy that applies guidance during rollout sampling only, prompt curation via intra-group reward range filtering, and per-category reward weight calibration to stabilize large-scale flow matching model training.
- On-policy distillation is proposed to unify task-specialized RL teachers into a single deployment model through trajectory-level velocity matching, eliminating reward model dependency and cross-task conflicts; the resulting Qwen-Image-2.0-RL surpasses a mixed RL baseline and achieves a 57.84 overall score on Qwen-Image-Bench (+2.61) with Elo ratings of 1193 in the T2I arena (+78) and 1349 in the image edit arena (+93).
Introduction
The authors tackle the gap between diffusion models’ impressive generation capabilities and human aesthetic preferences, a gap left by supervised denoising objectives that do not capture nuanced qualities like composition, texture, or prompt faithfulness. While reinforcement learning from human feedback (RLHF) offers a path to alignment, applying it to diffusion models presents three key challenges: designing reliable, task‑aware reward signals that span text‑to‑image and image editing tasks; scaling RLHF to full‑parameter training with multiple rewards; and consolidating task‑specialized policies into a single model without quality loss. The authors address these through a unified post‑training pipeline built on a chain‑of‑thought‑enabled VLM reward suite, a scalable GRPO‑based RL framework with hybrid classifier‑free guidance and prompt‑reward balancing, and an on‑policy distillation method that merges specialized teachers via trajectory‑level velocity matching, eliminating reward model dependency at deployment.
Dataset
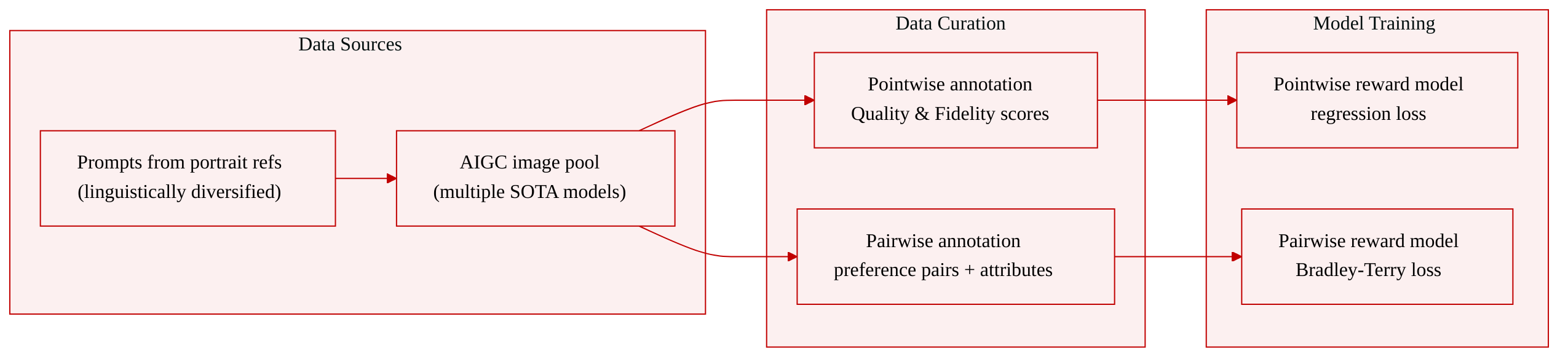
The authors construct two annotated datasets to compare reward model training paradigms, deliberately sharing the same evaluation focus (aesthetic quality and visual texture) while differing only in annotation format. Both datasets draw images from a common pool of state-of-the-art AIGC models, generated from prompts that originate from high-quality portrait reference images and are linguistically diversified to go beyond the training distribution.
Dataset composition and sources
- All images come from a single pool of AIGC-generated outputs, ensuring the comparison isolates the effect of the training paradigm rather than data distribution.
- Prompts are randomly sampled from high-quality portrait reference images and rewritten to increase linguistic variety.
- No explicit dataset sizes are reported in this excerpt; the focus is on annotation structure and training use.
Pointwise subset
- Each image is independently scored by human annotators on a 5-point Likert scale along two dimensions: Quality (clarity, lighting, color balance, stylistic coherence, material texture) and Fidelity (structural correctness, physical consistency, absence of AI artifacts).
- The resulting dataset provides absolute scores per image, used to train a reward model with a pointwise regression loss (the model outputs a discrete score distribution and the reward is the expectation).
Pairwise subset
- Image pairs are generated from the same prompt and presented side by side for preference judgment.
- Annotation follows a strict priority hierarchy: image-text consistency > structural distortion > texture quality > aesthetic appeal. When both images are free of distortions and consistent with the prompt, the comparison effectively reduces to texture quality and aesthetic appeal.
- Each pair is further labeled with auxiliary attributes: sample validity, presence of text distortion, and presence of human figure distortion, supporting fine-grained analysis.
- The resulting dataset provides preference pairs, used to train a reward model with the Bradley-Terry pairwise ranking loss.
How the data is used
- Both subsets are used to fine-tune the same VLM architecture as reward models, one with pairwise loss and the other with pointwise regression.
- The pointwise-trained reward model consistently yields better visual quality and fewer artifacts in downstream RL-based image generation, leading the authors to adopt the pointwise paradigm for all VLM-based reward models in the final system.
Processing details
- No cropping strategy or additional image preprocessing is mentioned.
- Metadata construction: pointwise data stores per-image Quality and Fidelity scores; pairwise data stores preference labels and the auxiliary attributes listed above.
Method
The authors leverage a comprehensive reinforcement learning framework to align diffusion models with human preferences, centered around a robust reward modeling system and a specialized training pipeline.
Reward Modeling To capture human preferences, the authors construct task-specific composite reward models. They investigate two training paradigms for fine-tuning Vision-Language Models (VLMs) as reward scorers: pairwise ranking and pointwise regression. In the pairwise approach, the model minimizes a Bradley-Terry ranking loss on preferred versus non-preferred image pairs. Conversely, the pointwise paradigm trains the model to regress directly to absolute human-annotated scores. The authors determine that pointwise training provides a richer supervisory signal, resulting in generated images with consistently better visual quality, finer texture detail, and fewer artifacts compared to the pairwise approach.

Training Pipeline and Hybrid CFG Strategy The training process extends Group Relative Policy Optimization (GRPO) to flow matching models. A critical architectural decision involves the application of Classifier-Free Guidance (CFG). The authors systematically evaluate three strategies: applying CFG in both rollout and training, removing it from both stages, or employing a hybrid approach. Applying CFG during training leads to severe instability and image collapse, while omitting it entirely causes the model to lose stylization capabilities and world knowledge. Consequently, the authors adopt a hybrid strategy where CFG is utilized exclusively during the rollout phase to generate high-quality candidates for reward evaluation, while the policy optimization objective remains CFG-free to maintain stable gradient updates.

The pipeline incorporates an asynchronous reward mechanism to decouple scoring from training, effectively hiding network latency. The group-relative advantage is calculated via weighted summation with per-prompt-group normalization: A(x0(i),c)=∑k=1Kwk⋅σkRk(x0(i),c)−μk This ensures the composite reward is invariant to absolute scale differences across reward models. Task-specific optimizations include restricting training signals to high-noise timesteps to prevent reward hacking and curating prompts that exhibit sufficient reward variance to ensure meaningful policy improvement.
On-Policy Distillation To address the limitation that RL optimization produces task-specialized policies (e.g., separate models for Text-to-Image generation and image editing), the authors introduce On-Policy Distillation (OPD). This method unifies multiple task-specialized teacher models into a single student model via trajectory-level velocity matching. The student model generates a full denoising trajectory and is trained to match the velocity predictions of the task-appropriate teacher at each step: LOPD=Ec,x[1:N]∼πθ(⋅∣c)[∑n=1N∥vθ(xtn,tn,c)−vθ∗(xtn,tn,c)∥2] This decomposed strategy avoids the optimization conflicts inherent in jointly training on mixed tasks (Mix-RL). The resulting unified model achieves superior prompt adherence, aesthetic quality, and identity preservation compared to both the pre-trained base model and the Mix-RL baseline.
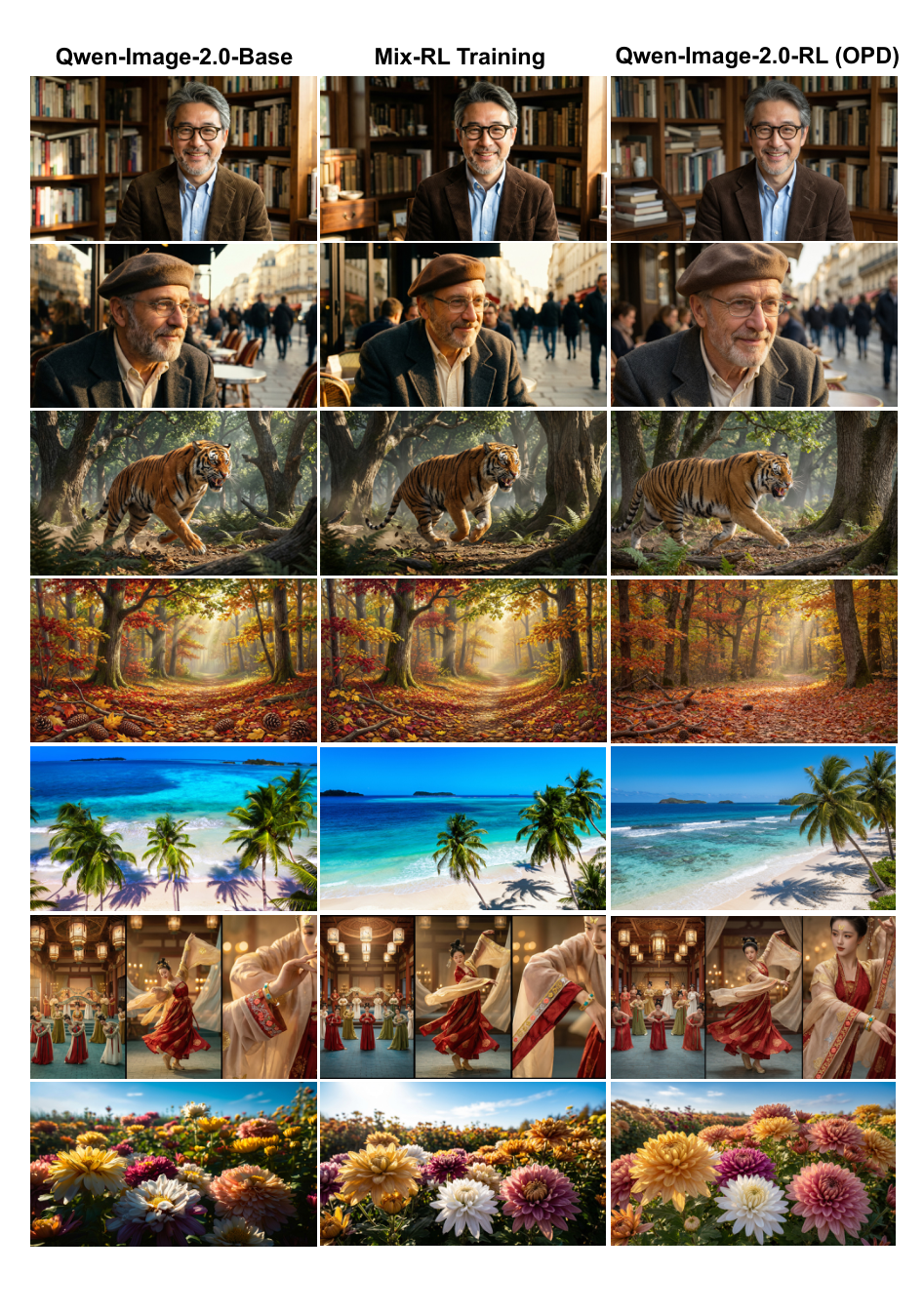
For image editing tasks, the framework integrates a dedicated model-based face identity consistency scorer alongside VLM-based instruction-following rewards. This ensures that fine-grained identity features are preserved during complex edits, such as style transfer or attribute modification, allowing the model to accurately execute instructions while maintaining the subject's original characteristics.

Experiment
The evaluation spans automated quality metrics and human preference arenas. RL training consistently improves Qwen-Image-2.0 across all dimensions, with the largest boosts in creative generation, real-world fidelity, 3D modeling, and photorealism. The image editing arena also shows substantial gains, confirming the effectiveness of the editing-specific RL training.
Reinforcement learning training lifts Qwen-Image-2.0's overall score on Qwen-Image-Bench from 55.23 to 57.84, with consistent gains across all five evaluation pillars. The largest improvements appear in Creative Generation and Real-world Fidelity, making the RL-trained model the strongest performer among all compared systems. Creative Generation benefits the most from RL, gaining 6.72 points and highlighting enhanced imaginative capabilities. Real-world Fidelity rises by 4.29 points, reflecting better structural consistency and fine detail rendering.
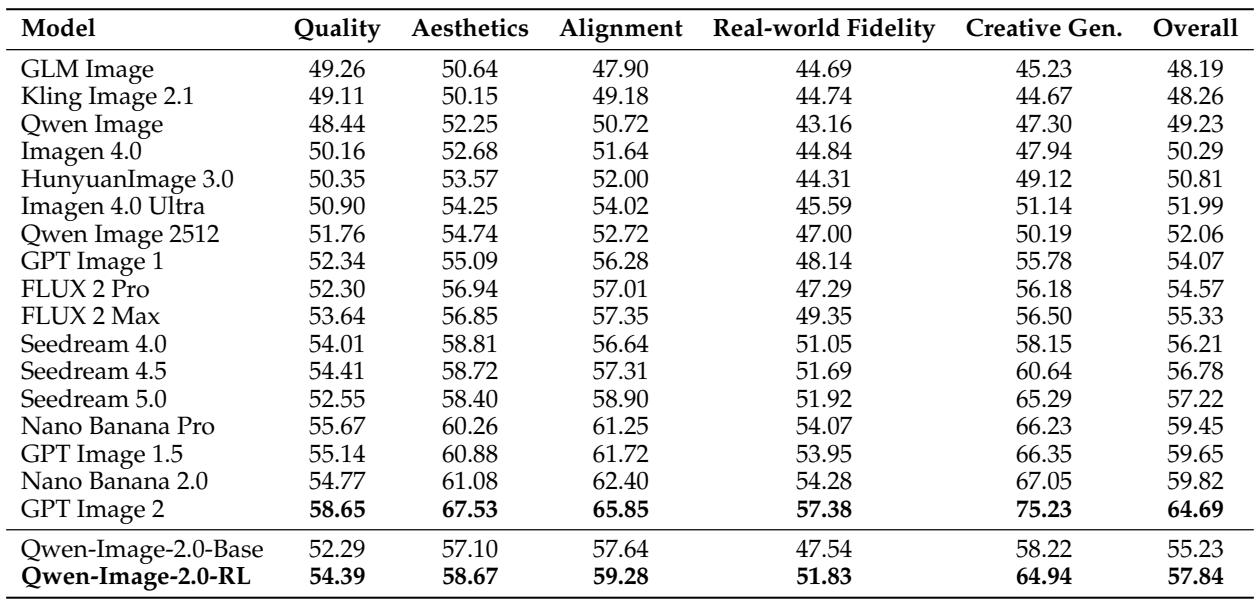
Reinforcement learning training improves Qwen-Image-2.0's overall performance on Qwen-Image-Bench, yielding consistent gains across all evaluation pillars. The largest improvements occur in Creative Generation and Real-world Fidelity, making the RL-trained model the strongest performer among compared systems. These gains reflect enhanced imaginative capabilities, better structural consistency, and finer detail rendering.