Command Palette
Search for a command to run...
Tiefes Verstärkungslernen-verbesserte ereignisgesteuerte datengetriebene prädiktive Regelung für einen 3D-kabelgetriebenen weichen Roboterarm
Tiefes Verstärkungslernen-verbesserte ereignisgesteuerte datengetriebene prädiktive Regelung für einen 3D-kabelgetriebenen weichen Roboterarm
Cheng Ouyang Moeen Ul Islam Kaixiang Zhang Zhaojian Li Xiaobo Tan Dong Chen
Zusammenfassung
Die Regelung von Soft-Robotern ist aufgrund ihrer nichtlinearen und zeitvarianten Dynamik herausfordernd. Data-enabled predictive control (DeePC) bietet eine modellfreie Alternative, indem gemessene Eingangs-Ausgangs-Trajektorien direkt zur Konstruktion eines prädiktiven Reglers herangezogen werden. Allerdings erfordert die Abrollhorizont-Formulierung die Lösung eines Optimierungsproblems mit Nebenbedingungen zu jedem Abtastzeitpunkt, was für den Echtzeiteinsatz auf ressourcenbeschränkten Roboterplattformen rechnerisch aufwendig sein kann. Um diese Einschränkung zu überwinden, schlagen wir ein adaptives, verstärkungslernbasiertes ereignisgesteuertes DeePC-Framework (RL-ET-DeePC) für die Regelung von Soft-Robotern vor. Eine modellfreie RL-Policy wird trainiert, um basierend auf der aktuellen Systemzustandsrepräsentation zu bestimmen, wann der DeePC-Optimierer aufgerufen werden soll. Dadurch werden unnötige Optimierungsaufgaben reduziert, während die Regelungsgüte im geschlossenen Kreis erhalten bleibt. Simulationsergebnisse zeigen, dass RL-ET-DeePC die Optimierungsfrequenz im Vergleich zur periodischen DeePC-Variante um bis zu 66 % senkt, wobei eine vergleichbare Tracking-Genauigkeit beibehalten wird. Hardwareexperimente an einem dreidimensionalen, seilgetriebenen Soft-Roboterarm demonstrieren einen Zero-Shot-Transfer und erreichen eine Reduktion der Optimierungsfrequenz um 34 % bei einer mit der periodischen DeePC-Variante vergleichbaren Tracking-Genauigkeit sowie eine konsistentere Leistung im Vergleich zu einer statischen, schwellenwertbasierten ereignisgesteuerten Baseline.
One-sentence Summary
the paper propose RL-ET-DeePC, an event-triggered data-enabled predictive control framework that employs a model-free reinforcement learning policy to dynamically activate the optimizer, reducing optimization frequency by 66% in simulation and 34% during zero-shot transfer to a 3D cable-driven soft robotic arm while maintaining tracking accuracy comparable to periodic methods.
Key Contributions
- Introduces an adaptive reinforcement-learning-based event-triggered DeePC (RL-ET-DeePC) framework that addresses the computational demands of real-time soft robotic control by adaptively scheduling the predictive optimizer.
- Develops a model-free reinforcement learning policy that evaluates the current system state to dynamically trigger the optimizer only when necessary, thereby eliminating redundant calculations while preserving closed-loop tracking performance.
- Validates the framework through simulations and hardware experiments on a three-dimensional cable-driven soft robotic arm, demonstrating up to a 66% reduction in optimization frequency during simulation and a 34% reduction during zero-shot hardware deployment while maintaining tracking accuracy comparable to periodic methods and superior consistency over static threshold baselines.
Introduction
Controlling soft robots is inherently challenging due to their highly nonlinear and time-varying dynamics, which makes traditional model-based approaches impractical for real-world deployment. Data-enabled predictive control (DeePC) offers a promising model-free alternative by directly using measured input-output trajectories to construct predictive controllers, yet its receding-horizon design requires solving a constrained optimization problem at every sampling instant. This computational burden creates a significant bottleneck for resource-limited robotic platforms that demand low-latency control. To address this, the authors introduce an adaptive reinforcement learning-based event-triggered DeePC framework that dynamically schedules optimizer calls based on real-time system states. By training a model-free reinforcement learning policy to activate the controller only when necessary, they substantially cut computational overhead while preserving tracking accuracy, as validated through both simulations and zero-shot hardware experiments on a three-dimensional cable-driven soft arm.
Method
The authors propose a control framework tailored for cable-driven soft robotic arms, such as the fabricated structure shown in the figure below.
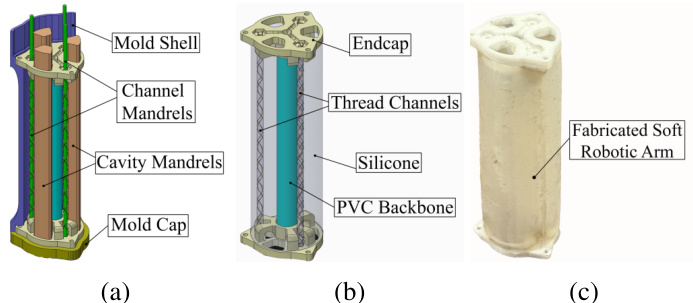
The core methodology is an RL-ET-DeePC (Reinforcement Learning Event-Triggered Data-Enabled Predictive Control) architecture. As illustrated in the framework diagram, the system is divided into two primary stages: pre-data preprocessing and an RL-based event-triggered control loop.
Pre-Data Preprocessing and SVD-DeePC The method utilizes a data-driven approach to model the system dynamics without explicit identification of state-space matrices. The authors collect offline input-output trajectories, denoted as ud and yd, and arrange them into block Hankel matrices of depth L. According to Willems's Fundamental Lemma, the column span of this Hankel matrix characterizes all admissible trajectories of the underlying linear time-invariant system.
HL=[HL(yd)][HL(ud)]However, soft robots require extensive data collection, resulting in high-dimensional Hankel matrices that are computationally expensive to process in real-time. To mitigate this, the authors apply Singular Value Decomposition (SVD) to compress the data. The concatenated Hankel matrix is factorized, and the matrix is truncated to rank r, retaining only the dominant singular values. This preserves the principal dynamical modes while significantly reducing the dimensionality of the decision variables. The resulting reduced Hankel matrix HˉL allows any valid trajectory to be approximated as:
[u[1,L]y[1,L]]=HˉLgˉwhere gˉ is a lower-dimensional decision vector.
RL-Based Event-Triggered Control Loop The control loop, depicted in the lower section of the framework diagram, integrates this compressed data representation with a reinforcement learning agent to manage computational costs. At each time step t, the system state is derived from the tracking error et and its variation Δet. This state is fed into the RL Agent, which outputs a binary action at∈{0,1}.
If the action is 1, the system triggers the SVD-DeePC Optimizer. This module solves a regularized optimization problem to minimize tracking error and control effort subject to the data-driven constraints. The optimization problem includes a slack variable to handle measurement noise and regularization terms to prevent overfitting.
gˉ,u,y,σyminsubject to∥y−yr∥Q2+∥u∥R2+λy∥σy∥22+λg∥gˉ∥22HˉLgˉ=uiniuyiniy+00σy0The optimizer produces an optimal control sequence, the first element of which is applied to the robot, and the remaining elements are stored in the Control Sequence Buffer.
If the action is 0, the optimization is skipped to save computation. Instead, the controller retrieves the next control input from the Control Sequence Buffer. This allows the system to utilize the prediction horizon from the previous optimization step, transforming conventional receding-horizon control into an event-driven mechanism.
Supervisory Override Mechanism To ensure robustness, a Supervisor module acts as a safeguard within the control architecture. It monitors the Control Sequence Buffer and the time elapsed since the last update. If the buffer is empty or the time since the last optimization exceeds the prediction horizon minus one (t−tlast≥N−1), the Supervisor forces a trigger (δt=1), overriding the RL agent's decision. This ensures that the controller always has a valid control sequence available and prevents excessive open-loop execution. The effective triggering signal δt determines whether the SVD-DeePC Optimizer runs or the buffered input is used.
Training and Interaction The RL agent is trained to balance tracking accuracy and computational efficiency. The reward function penalizes both the tracking error and the computational cost of triggering the optimizer. The parameter ρ in the reward function controls the trade-off, encouraging the agent to learn a state-dependent policy that triggers optimization only when necessary. The agent interacts with the environment in episodes, updating its policy based on the observed states, actions, and rewards. This framework is algorithm-agnostic, allowing for the integration of various RL approaches such as DQN, PPO, or A2C.
Experiment
The evaluation combines high-fidelity simulations and physical experiments on a cable-driven soft robotic arm to assess the proposed RL-ET-DeePC framework. Simulation tests validate the controller's ability to balance tracking accuracy with computational efficiency while generalizing to unseen trajectories. Hardware experiments further confirm that the learned policy successfully transfers to real-world conditions, maintaining stable control and context-aware triggering without relying on fixed error thresholds. Overall, the framework effectively reduces optimization frequency by prioritizing updates during dynamic transitions, preserving tracking fidelity comparable to periodic control while adapting intelligently to motion context.
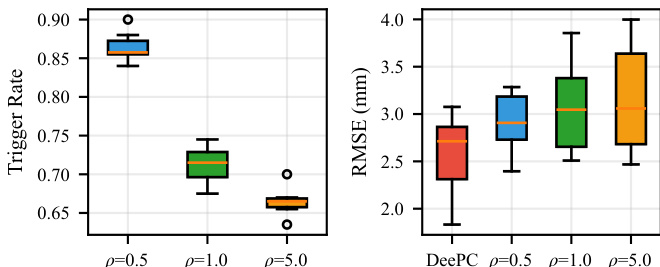
The authors evaluate the RL-ET-DeePC framework on a physical soft robotic arm, comparing it against a periodic DeePC baseline. The results demonstrate a clear trade-off controlled by the penalty parameter: increasing the penalty significantly reduces the frequency of controller updates while maintaining acceptable tracking accuracy. The periodic DeePC controller serves as the high-accuracy baseline, whereas the RL-based approach effectively lowers computational burden by adapting when to re-optimize. Increasing the penalty parameter leads to a substantial decrease in the trigger rate, reducing optimization calls compared to the periodic baseline. The RL-ET-DeePC method maintains tracking accuracy comparable to the periodic DeePC controller, even with reduced update frequencies. The learned policy successfully transfers from simulation to hardware, preserving the desired accuracy-efficiency trade-off under real-world conditions.
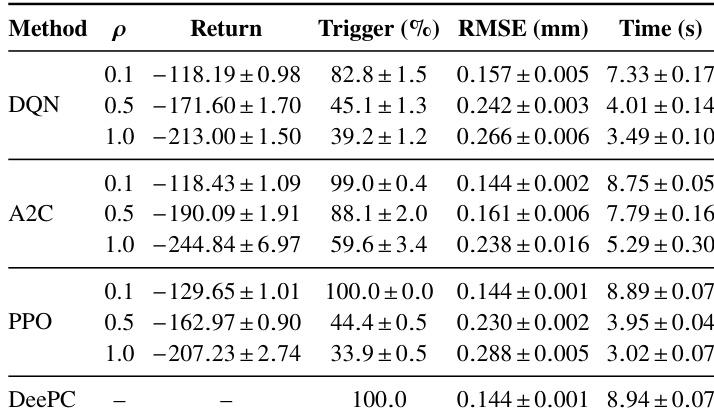
The authors compare reinforcement learning-based event-triggered DeePC methods including DQN, A2C, and PPO with a periodic DeePC baseline. Increasing the penalty parameter rho consistently reduces the triggering frequency and total computation time for all RL algorithms, while slightly increasing the tracking error. PPO demonstrates the most efficient performance, achieving the greatest reduction in decision time while maintaining acceptable tracking accuracy relative to the other RL methods. Increasing the penalty parameter rho results in lower triggering rates and reduced computational time for all RL algorithms. PPO achieves the lowest total decision time among the RL methods, outperforming DQN and A2C in efficiency. The periodic DeePC baseline maintains the highest triggering rate and accuracy, serving as the performance ceiling that RL methods approximate with reduced computational cost.
The experiments evaluate a reinforcement learning-based event-triggered DeePC framework on a physical soft robotic arm, benchmarking it against a periodic DeePC baseline to assess computational efficiency and tracking performance. By adjusting a penalty parameter, the study demonstrates that the RL approach successfully balances reduced optimization frequency with maintained tracking accuracy, effectively lowering computational demands without compromising control quality. Among the tested algorithms, PPO proves most efficient, while the entire framework validates a robust simulation-to-hardware transfer that preserves the desired accuracy-efficiency trade-off under real-world conditions.