Command Palette
Search for a command to run...
Lernen der visuellen Roboternavigation in Menschenmengen mittels absichtsbewusster Szenenrepräsentationen
Lernen der visuellen Roboternavigation in Menschenmengen mittels absichtsbewusster Szenenrepräsentationen
Han Bao Bingyi Xia Hanjing Ye Yu Zhan Hao Cheng Baozhi Jia Wenjun Xu Jiankun Wang
Zusammenfassung
Die Navigation von Robotern in Menschenmengen erfordert die Fähigkeit, menschliche Absichten abzuleiten, wobei gleichzeitig die strukturellen Einschränkungen der Umgebung berücksichtigt werden müssen. Derzeit bietet Deep Reinforcement Learning (DRL) eine vielversprechende Methode zum Erlernen von Navigationspolicies, die menschliche Absichten verstehen. Allerdings stützen sich die meisten Ansätze auf begrenzte Szenendarstellungen, behandeln Fußgänger als einfache 2D-Punkte und ignorieren dabei reichhaltige visuelle Merkmale sowohl von Menschen als auch der Umgebung. Um dieses Problem zu adressieren, stellen wir iCrowdNav vor, eine neuartige visuelle Navigationsmethode für Menschenmengen mit absichtsbezogenen Szenendarstellungen, die Verhaltens- und Strukturkontext aus egozentrischen visuellen Beobachtungen kodiert. Unsere Methode nutzt zwei Kernkomponenten: einen räumlich-zeitlichen Encoder zur Extraktion von Belegungsmerkmalen der Szene sowie den Intent-Interact Former (I2 Former), ein auf Aufmerksamkeit basierendes Modul, das menschliche Posen kodiert, um die Bewegungsabsichten von Fußgängern abzuleiten. Diese Merkmale werden in ein kompaktes Zustands-Embedding integriert, das ein effektives Training von DRL-Policies unterstützt. Umfangreiche Experimente zeigen, dass unsere Methode im Vergleich zu Baseline-Methoden eine überlegene Leistung erzielt, und reale Einsatzszenarien demonstrieren die visionsbasierte Navigation in Menschenmengen.
One-sentence Summary
iCrowdNav enhances deep reinforcement learning for crowd navigation by leveraging intention-aware scene representations that integrate a spatio-temporal encoder for environmental occupancy and the Intent-Interact Former (I^2Former) for pedestrian pose inference from egocentric views, achieving superior performance over baselines in extensive experiments and demonstrating successful real-world deployment.
Key Contributions
- iCrowdNav is a visual navigation framework that learns intention-aware scene representations directly from egocentric camera observations. The architecture combines a spatio-temporal encoder for extracting occupancy features with an Intent-Interact Former module to process human poses and infer pedestrian motion intentions.
- The method replaces simplified 2D point representations with BEV features integrated with behavioral visual cues, enabling a deep reinforcement learning policy to navigate dense crowds. This design captures both environmental structural constraints and human behavioral context within a compact state embedding for effective policy training.
- Extensive simulation benchmarks and real-world physical robot deployments demonstrate that the framework achieves improved safety and robustness compared to existing baselines. These results validate the practical viability of vision-based crowd navigation in dynamic, populated environments.
Introduction
Autonomous robot navigation in dense crowds is essential for real-world service applications but requires anticipating human behavior while navigating constrained spaces. Prior deep reinforcement learning methods typically oversimplify scene representations by treating pedestrians as low-dimensional 2D points and relying on basic occupancy maps. This approach ignores critical visual cues like body poses and environmental semantics, which limits generalization from controlled simulations to unstructured real-world environments. To address these limitations, the authors leverage a novel visual encoder within a deep reinforcement learning framework to learn intention-aware scene representations directly from egocentric RGB-D cameras. They combine a spatio-temporal encoder that extracts dense occupancy features with an attention-based module that infers pedestrian motion tendencies from 3D human poses. These enriched visual cues are fused into a compact state embedding that enables robots to navigate safely and efficiently in complex crowds with successful zero-shot sim-to-real deployment.
Dataset

-
Dataset composition and sources The authors generate the dataset entirely through simulation using the SocNav-Gym environment built on Isaac Sim. Visual data is captured using a Clearpath Dingo robot equipped with two Intel RealSense D435 RGB-D cameras, which deliver a combined field of view of approximately 140 degrees and a depth range of 0.3 to 10 meters.
-
Key details for each subset Training scenarios feature hallways, corners, cluttered spaces, and dense open areas. Testing scenarios span specialized indoor settings including hospitals, offices, and warehouses. The provided text does not specify exact dataset sizes, filtering thresholds, or subset mixture ratios.
-
How the paper uses the data The authors leverage the simulated trajectories to train and evaluate social navigation policies. Each episode randomizes the robot's starting and target positions to encourage adaptation across varied navigation tasks. Pedestrian agents follow the Social Force Model and move toward fully randomized destinations to drive policy learning.
-
Processing and environment details Natural pedestrian animations are rendered through Isaac Sim to ensure crowd interactions closely mirror real-world dynamics. The simulation does not mention explicit cropping strategies or metadata construction, relying instead on randomized episode initialization and physics-based pedestrian modeling to generate diverse navigation experiences.
Method
The authors address the challenge of vision-based robot navigation in crowded environments by formulating the task as a partially observed Markov decision process. The overall system architecture is depicted in the framework diagram, which illustrates the flow from system inputs to navigation actions. The method consists of three primary components: a feature extraction module, a feature fusion module, and a deep reinforcement learning network.
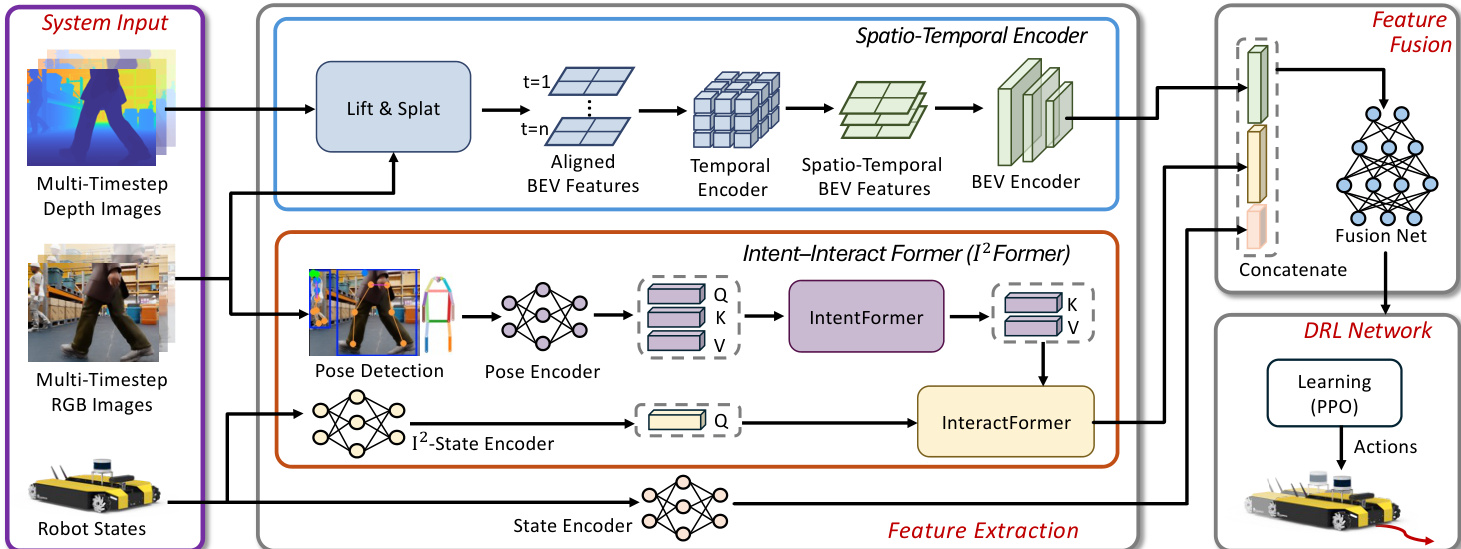
The feature extraction module processes multi-timestep RGB-D images and pedestrian poses. As shown in the detailed module diagram, the spatio-temporal encoder handles the visual inputs. It utilizes a pre-trained RGB backbone to extract features from the images. These features are then lifted to 3D space and splatted into a Bird's Eye View (BEV) representation. To capture temporal dynamics, the encoder aligns BEV features from previous time steps (t−1 and t−2) using a temporal encoder, resulting in a robust spatio-temporal BEV feature map. This encoder is kept frozen during training as it is pre-trained on external datasets.
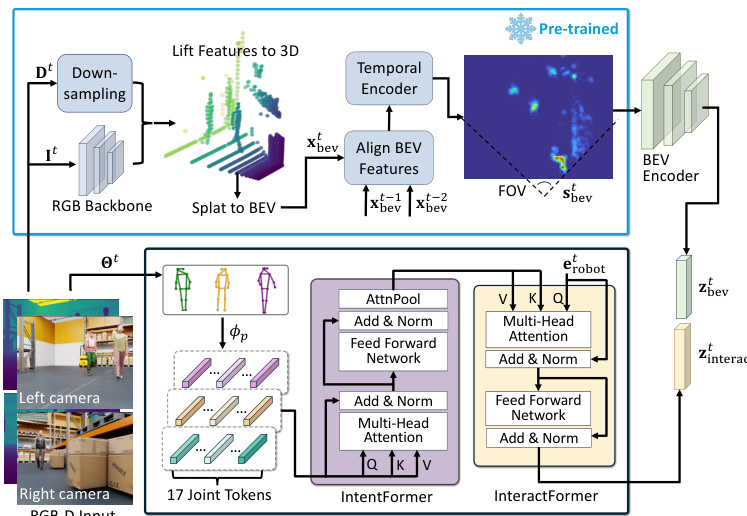
Simultaneously, the Intent-Interact Former (I2Former) extracts intention-aware features from the poses of surrounding pedestrians. The pose detection module identifies pedestrians and encodes their 17 joint tokens. These tokens are processed by an IntentFormer, which captures the intention of the pedestrians. The InteractFormer then integrates these intention features with the robot's internal state embedding (erobott) through multi-head attention mechanisms, producing interaction-aware features.
The extracted spatio-temporal BEV features (zbevt) and the interaction features (zinteractt) are concatenated with the robot state embedding to form a comprehensive state representation. This state embedding is fed into a DRL network based on the Proximal Policy Optimization (PPO) algorithm. The network is trained to maximize the expected cumulative reward, defined as:
L(θ)=Eπθ[t=0∑∞γtrt]where γ is the discount rate and rt is the reward at time t. The reward function is designed to encourage safe navigation, collision avoidance, and smooth trajectories. Specifically, the navigation reward rnavt provides dense feedback based on the distance to the goal (dgt) and the minimum distance to obstacles or pedestrians (dot). The reward logic is structured as follows:
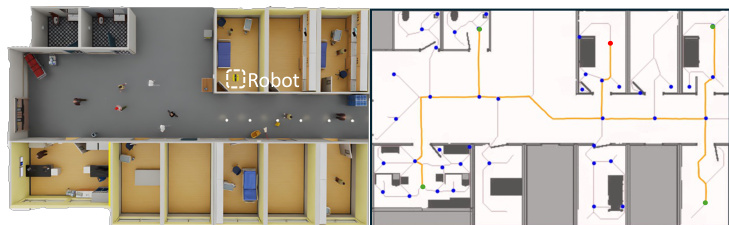
rnavt=⎩⎨⎧20,−20,0.5(dot−0.9),3.2(dqt−1−dqt),if dgt≤ρrobotelse if dot≤ρrobotelse if ρrobot<dot<0.9otherwise,where ρrobot is the radius of the robot. To address potential jitter in the policy, a trajectory-smoothing reward rωt is also included, which penalizes excessive angular velocity. The method is evaluated in complex indoor scenarios, as illustrated in the simulation visualization, where the robot must navigate through hallways and rooms while maintaining social distance from pedestrians.
Experiment
The proposed method was evaluated through simulated crowd navigation across varying spatial constraints and densities, long-horizon topological mapping tasks, and real-world deployments in complex public environments. These experiments validate the combined effectiveness of the spatio-temporal BEV encoder and intention-aware I²Former modules against ablated variants and established navigation baselines. Qualitatively, the full architecture consistently yields smoother trajectories, enhanced spatial awareness, and significantly reduced intrusion into personal space, particularly in dense or narrow settings. Ablation studies confirm that integrating both environmental occupancy features and pedestrian intention modeling is essential for flexible navigation, while real-world tests further demonstrate the system's robustness and social compliance under dynamic, occluded conditions.
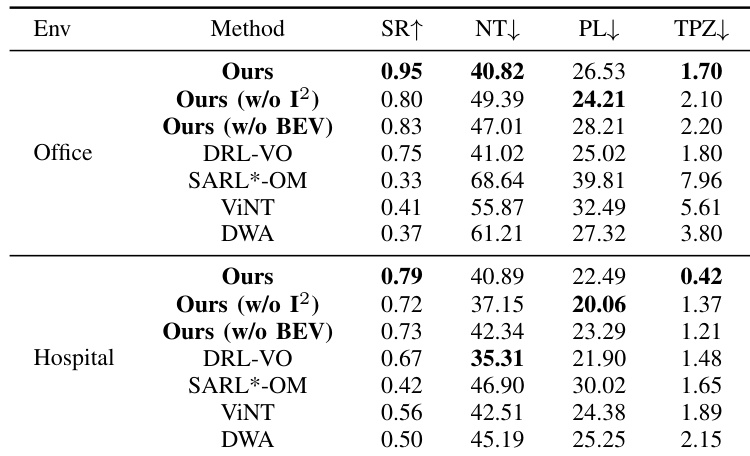
The experiment evaluates the proposed navigation method against baselines and ablation variants in office and hospital settings. The full method consistently achieves the highest success rates and the lowest time spent in pedestrians' private zones, indicating superior safety and effectiveness. Ablation studies confirm that both the intention-aware module and the BEV representation are crucial, as their removal leads to degraded performance in success rate and personal space compliance. The proposed method achieves the highest success rates in both office and hospital environments compared to all baseline methods. Removing the intention-aware module results in a decrease in success rate and significantly increased time spent in pedestrians' private zones. The full method demonstrates the safest navigation behavior by maintaining the lowest time in private zones across both environments.
The authors evaluate their navigation method against several baselines and ablated variants across three distinct environments with varying widths and crowd densities. The results indicate that the full method achieves the highest success rates and most efficient navigation while minimizing intrusion into pedestrians' personal space. Removing key components like the intention-aware module or the BEV encoder leads to significant performance drops, particularly in success rate and social compliance. The proposed method consistently outperforms baselines in success rate, navigation efficiency, and social compliance across all tested environments. Ablation studies demonstrate that both the intention-aware module and the BEV encoder are critical for robust performance, as their absence increases collisions and social violations. In narrow and high-density scenarios, the method maintains superior stability and safety compared to baselines, which often exhibit rigid or inefficient navigation behaviors.
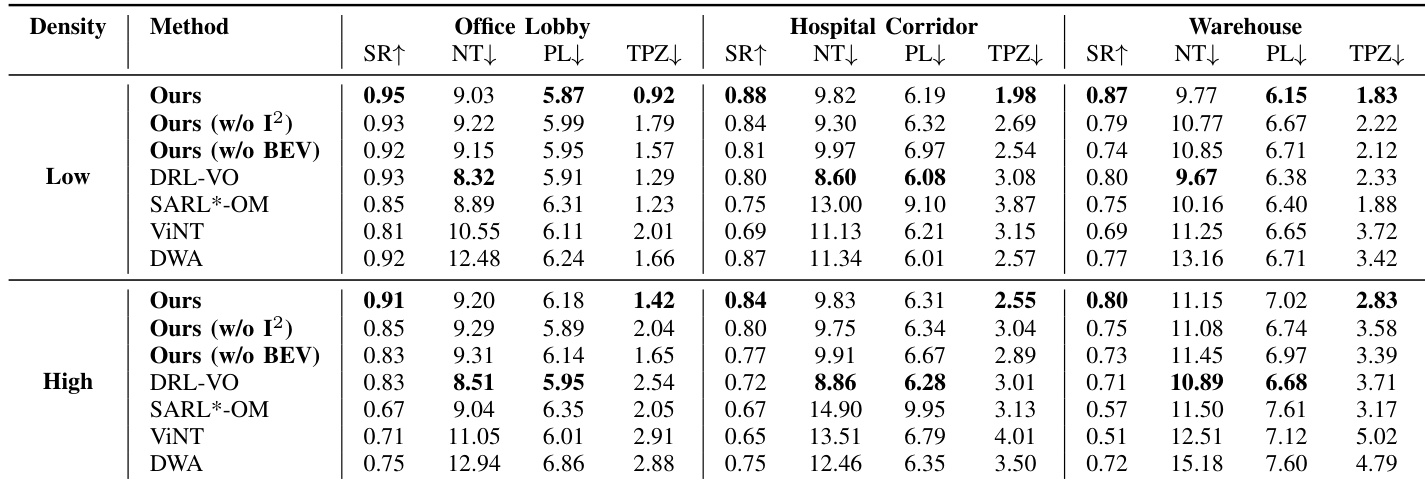
The proposed navigation method was evaluated across office, hospital, and varied environmental settings against standard baselines and ablated variants to assess its overall effectiveness and social compliance. The full system consistently demonstrates superior navigation success and efficiency while strictly minimizing intrusion into pedestrians' personal space, particularly in narrow or crowded conditions where baseline approaches exhibit rigid or unsafe behaviors. Ablation studies further validate that both the intention-aware module and the BEV representation are critical for robust performance, as their removal significantly compromises safety, increases social violations, and degrades overall reliability.