Command Palette
Search for a command to run...
Verbesserte Large Language Diffusion Models
Verbesserte Large Language Diffusion Models
Shen Nie Qiyang Min Shaoxuan Xu Zihao Huang Yuxuan Song Yong Shan Yankai Lin Wayne Xin Zhao Chongxuan Li Ji-Rong Wen
Zusammenfassung
Moderne Large Language Models (LLMs) werden überwiegend unter Verwendung autoregressiver Faktorisierung und kausaler Aufmerksamkeitsmechanismen (Causal Attention) trainiert. Wir präsentieren iLLaDA, ein 8-Milliarden-Parameter (8B) maskiertes Diffusions-LLM, das vollständig neu trainiert wurde und auf einer vollständig bidirektionalen Aufmerksamkeitsmechanismus (Bidirectional Attention) basiert. iLLaDA behält das maskierte Diffusionsziel während des gesamten Pretrainings sowie des Supervised Fine-Tunings (SFT) bei. Dabei wurden 12 Billionen (12T) Token im Pretraining verarbeitet und das Fine-Tuning auf einem Anweisungskorpus mit 25 Milliarden (25B) Token über 12 Epochen durchgeführt. Zur Steigerung der Effizienz wird zudem die Generierung variabler Längen genutzt, und für die Mehrfachauswahl-Evaluierung (Multiple-Choice Evaluation) wird eine confidence-basierte Scoring-Methode eingeführt.Im Vergleich zu LLaDA zeigt iLLaDA verbesserte Leistungen in allgemeinen, mathematischen und Code-bezogenen Benchmarks: Beispielsweise erreicht iLLaDA-Base eine Steigerung von 21,6 Punkten im BBH-Benchmark und 14,9 Punkten im ARC-Challenge. iLLaDA-Instruct verbessert sich um 14,5 Punkte im MATH-Benchmark und um 16,5 Punkte im HumanEval-Benchmark. Trotz des nicht-autoregressiven Trainings bleibt iLLaDA in mehreren Benchmarks konkurrenzfähig mit Qwen2.5 7B. Diese Ergebnisse zeigen, dass ein vollständig bidirektionales Diffusions-Training von Grund auf ein vielversprechender Ansatz für leistungsstarke Sprachmodelle ist. Modellgewichte und Quellcode: https://github.com/ML-GSAI/LLaDA.
One-sentence Summary
The authors propose iLLaDA, an 8B-parameter masked diffusion language model trained from scratch with fully bidirectional attention and a masked diffusion objective across 12T pre-training tokens and fine-tuned for 12 epochs on 25B instruction tokens, which incorporates variable-length generation and confidence-based scoring to achieve broad improvements over LLaDA and remain competitive with Qwen2.5 7B on general, mathematical, and code benchmarks.
Key Contributions
- iLLaDA, an 8B-parameter masked diffusion language model, is trained from scratch with fully bidirectional attention and a masked diffusion objective maintained throughout pre-training on 12T tokens and supervised fine-tuning on a 25B-token instruction corpus for 12 epochs.
- Variable-length generation is used for inference efficiency, and a confidence-based scoring mechanism is introduced for multiple-choice evaluation.
- iLLaDA improves broadly over the prior LLaDA model, with a 21.6-point gain on BBH and 14.9 points on ARC-Challenge for the base version, and remains competitive with Qwen2.5 7B, demonstrating that fully bidirectional diffusion training from scratch is a viable direction for strong language models.
Introduction
The paper addresses the challenge of scaling diffusion models for language generation, an area dominated by autoregressive architectures. Diffusion models, which excel in continuous domains like image synthesis, struggle with discrete text data and have lagged behind autoregressive transformers in quality and efficiency at larger scales. The authors present key improvements to large language diffusion models that close this gap, demonstrating that diffusion-based language models can achieve competitive performance with autoregressive counterparts while offering potential advantages such as parallel decoding and controllable generation.
Method
The authors introduce iLLaDA, an 8B parameter masked diffusion language model trained from scratch utilizing fully bidirectional attention. The core methodology retains the masked diffusion objective throughout both the pre-training and supervised fine-tuning phases, enabling the model to learn robust bidirectional representations.
During pre-training, the model optimizes a likelihood-based masked diffusion objective for discrete data. Given a clean sequence x0 of length L, the authors sample a masking ratio t from a uniform distribution between 0 and 1. Each token is independently replaced by a mask token with probability t to form a corrupted sequence xt. The model is then trained to predict all masked tokens using the following loss function:
L(θ)≜−Et,x0,xt[t1∑i=1L1[xti=M]logpθ(x0i∣xt)]
Here, the indicator function ensures that the loss is computed exclusively for the masked tokens, distinguishing this approach from traditional masked language modeling with a fixed masking ratio.
The backbone of the model is a dense Transformer incorporating RMSNorm, SwiGLU, and RoPE, without any attention or MLP bias. A key architectural modification involves the use of grouped-query attention instead of standard multi-head attention. This design choice significantly reduces the memory footprint of cached key and value states during cache-style implementations. Additionally, the authors tie the input embedding and language model head parameters to control the overall parameter count. The architectural differences between this model and its predecessor are summarized as shown in the figure below:
The pre-training process operates with a maximum sequence length of 8192 tokens. To enhance efficiency and robustness, the authors randomly split sequences into two shorter segments with a 30 percent probability. Variable-length examples are packed within each batch, and attention is computed using a FlashAttention-based variable-length kernel that utilizes cumulative sequence offsets to separate examples without padding. The learning rate is linearly warmed up to 2×10−4 and maintained at a constant rate until the pre-training loss plateaus, at which point it transitions to a cosine decay schedule with a minimum learning rate of 5×10−6. Optimization is performed using the AdamW optimizer with a weight decay of 0.1.
For supervised fine-tuning, the authors depart from prior approaches that typically keep prompt tokens visible and apply masks only to the response region. Instead, they employ the exact same data processing and masking scheme used during pre-training. Each instruction example is formatted as a prompt-response sequence followed by a single terminal |EOS| token. All formatted examples are concatenated into a continuous instruction corpus, from which 8192-token training sequences are sampled. Random masks are then applied to the entire sequence, meaning prompt tokens, response tokens, and the terminal token can all be masked. This unified masking format naturally supports variable-length block generation.
The fine-tuning corpus comprises approximately 25 billion tokens, and the model is trained for 12 epochs. The learning rate schedule begins with a linear warmup to 5×10−6, remains constant, and finally undergoes a linear decay to 5×10−7 over the final 10 percent of the training process. The AdamW optimizer is again utilized with a weight decay of 0.1.
Experiment
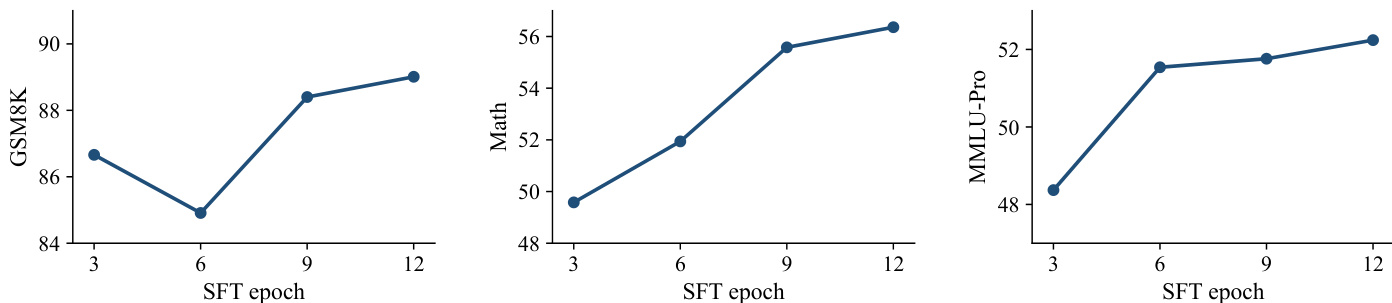
iLLaDA is evaluated on a broad suite of language understanding, reasoning, mathematics, and code generation benchmarks in both base and instruction-tuned settings, comparing against prior diffusion models and the autoregressive Qwen2.5 7B. The base model substantially advances bidirectional diffusion performance, matching or exceeding the autoregressive baseline on several reasoning tasks, while the instruct model significantly narrows the gap but still trails on math and code due to the absence of reinforcement-learning alignment. Ablations validate that confidence-based multiple-choice scoring and extended supervised fine-tuning yield clear improvements, with performance continuing to rise through many epochs. Overall, the experiments show that bidirectional diffusion pre-training can acquire strong general and reasoning capabilities, demonstrating that competitive large language models need not rely on autoregressive generation.
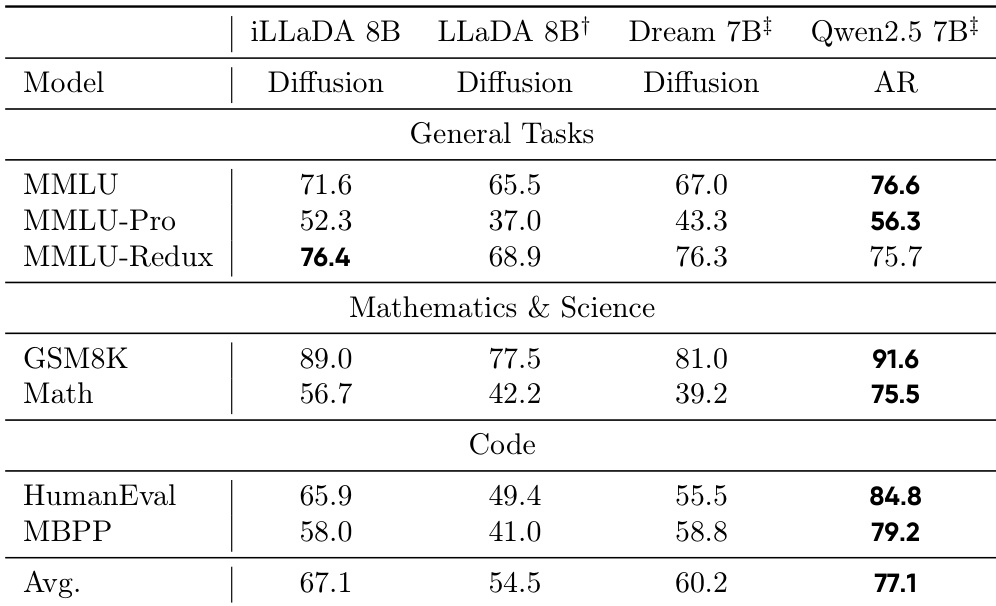
The authors evaluate iLLaDA, a bidirectional masked diffusion language model, against other diffusion models and a strong autoregressive baseline on standard benchmarks. Results show that iLLaDA substantially outperforms previous diffusion models across general, mathematical, and coding tasks, achieving the highest average score among them. While the autoregressive baseline still leads on most benchmarks, iLLaDA demonstrates competitive performance and even surpasses it on specific tasks like MMLU-Redux. iLLaDA achieves the best average performance among the evaluated diffusion language models, showing significant improvements over prior versions. The model narrows the gap with strong autoregressive baselines, performing competitively on general and mathematical reasoning benchmarks. iLLaDA outperforms the autoregressive baseline on the MMLU-Redux benchmark, highlighting its strong capabilities in multi-task understanding.
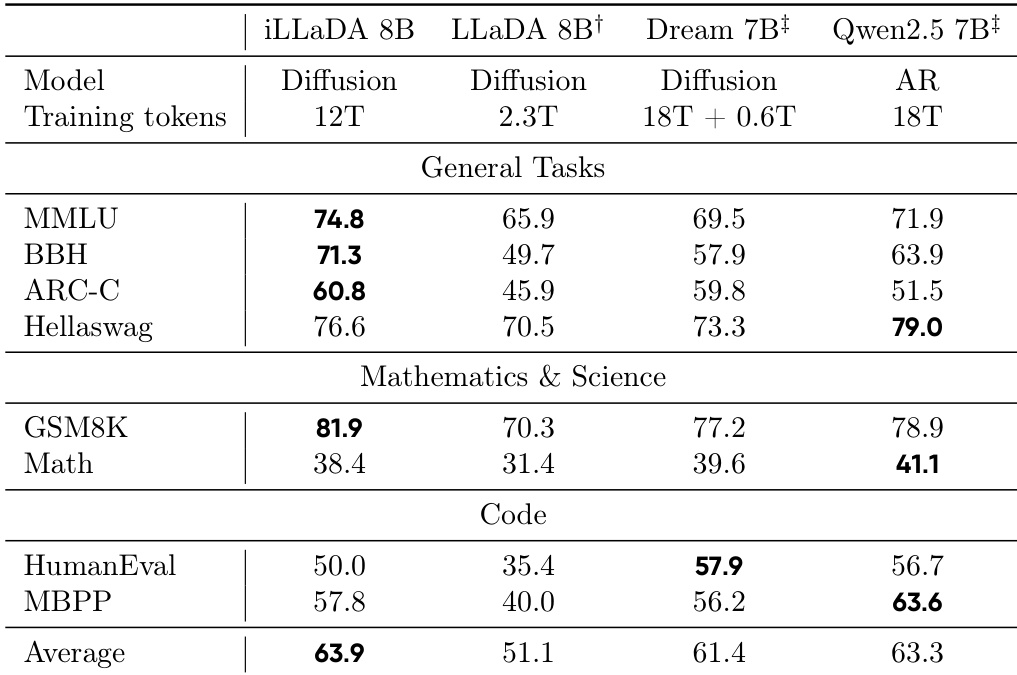
The authors compare base model performance across general, mathematical, and coding benchmarks for the proposed iLLaDA 8B diffusion model against LLaDA 8B, Dream 7B, and the autoregressive Qwen2.5 7B. Results indicate that iLLaDA 8B achieves the highest average performance, showing substantial improvements over the previous LLaDA model. While iLLaDA 8B outperforms the autoregressive Qwen2.5 7B on several reasoning and general tasks, the autoregressive model retains advantages in specific coding and advanced math areas. iLLaDA 8B obtains the highest average score across all categories, demonstrating significant gains over the LLaDA 8B baseline. iLLaDA 8B surpasses the autoregressive Qwen2.5 7B on general understanding and reasoning benchmarks such as MMLU, BBH, and ARC-Challenge. The autoregressive Qwen2.5 7B and Dream 7B models retain performance advantages on code generation tasks, leading on MBPP and HumanEval respectively.
The authors conduct an ablation study on multiple-choice scoring rules, comparing a likelihood-based approach with a confidence-based scoring method. Results indicate that the confidence-based scoring rule consistently outperforms the likelihood baseline across various benchmarks, motivating its adoption for multiple-choice evaluations. Confidence-based scoring achieves higher performance than likelihood-based scoring across all tested benchmarks. The improvement is observed in general language understanding tasks such as PIQA and HellaSwag. The confidence-based approach also yields better results on the ARC-Challenge benchmark.

The evaluation compares iLLaDA, a bidirectional masked diffusion language model, against prior diffusion models and an autoregressive baseline across general understanding, mathematical reasoning, and coding benchmarks. iLLaDA consistently achieves the highest average performance among diffusion models and narrows the gap with the autoregressive model, even surpassing it on certain multi-task understanding and reasoning benchmarks such as MMLU, BBH, and ARC-Challenge. An ablation on multiple-choice scoring further shows that a confidence-based rule robustly outperforms likelihood-based scoring, which is adopted for all evaluations. Overall, iLLaDA demonstrates strong and competitive capabilities, particularly in reasoning and comprehension, though autoregressive models retain advantages in some coding tasks.