Command Palette
Search for a command to run...
Kleine LLMs: Pruning im Vergleich zum Training von Grund auf
Kleine LLMs: Pruning im Vergleich zum Training von Grund auf
Yufeng Xu Taiming Lu Kunjun Li Jiachen Zhu Mingjie Sun Zhuang Liu
Zusammenfassung
Pruning verspricht einen effizienten Weg zu leistungsfähigen Small Language Models (SLMs). In dieser Arbeit untersuchen wir dieses Potenzial, indem wir das Modell Llama-3.1-8B bei Pruning-Ratios von 0,5 bis 0,8 mit sechs Methoden unterschiedlicher Granularität ( Depth, Width und sparse Granularities ) unter zwei kontrollierten, Token-äquivalenten (token-matched) Bedingungen analysieren.(1) Bei einem identischen Budget an Trainings-Tokens übertrifft die Initialisierung durch Pruning konstant die Random-Initialisierung. Dies zeigt, dass das Parent-Modell einen starken Startpunkt bietet. Der Vorteil schmilzt jedoch, je größer das Trainings-Token-Budget wird und je höher die Pruning-Ratio ist, und verschwindet bei der höchsten im Rahmen dieser Studie untersuchten Pruning-Ratio nahezu vollständig.(2) Wenn der Trainingsprozess stattdessen mit einem gesamten Token-Budget durchgeführt wird, das dem gesamten Verbrauch der kompletten Pipeline entspricht, bewahrt das Pruning bei feiner Granularität weiterhin einen Vorteil, während grobere strukturelle Pruning-Methoden entweder gleichgezogen oder übertroffen werden können. Dies deutet darauf hin, dass das Parent-Modell Wissen transferiert, das zusätzliche Trainings-Tokens allein nicht vollständig wiederherstellen können – dies gilt jedoch nur bei feiner Granularität.Zusammengenommen liefern unsere Ergebnisse eine klare Empfehlung: Wenn ein großes vor Trainiertes (pretrained) Modell zur Verfügung steht und das Trainings-Token-Budget begrenzt ist, ist Pruning der Training-from-scratch-Ansatz überlegen. Ist das Trainingsbudget hingegen unbegrenzt, kann Training-from-scratch bei groberem Pruning wettbewerbsfähig sein, sodass ein großes vor Trainiertes Parent-Modell nicht immer notwendig ist. Unser Code steht unter github.com/zlab-princeton/pruning-vs-scratch zur Verfügung.
One-sentence Summary
Comparing six pruning methods spanning depth, width, and sparse granularities on Llama-3.1-8B at pruning ratios of 0.5–0.8 under two token-matched budgets, Princeton researchers reveal that pruned initialization significantly outperforms random initialization when training tokens are limited, though this advantage narrows as the budget grows and the pruning ratio rises, nearly vanishing at the highest ratio, and that when training from scratch receives the full pipeline budget, finer granularities still benefit while coarser structured pruning is matched or surpassed, offering a clear guide that a large parent model is necessary only when training tokens are limited.
Key Contributions
- Six pruning methods spanning depth, width, and sparse granularities are compared on Llama-3.1-8B at pruning ratios 0.5–0.8 under two token-matched retraining conditions.
- Given the same retraining token budget, pruned models consistently outperform randomly initialized models, though the advantage shrinks as the token budget grows and as the pruning ratio increases, nearly vanishing at ratio 0.8.
- When scratch training receives the full pipeline token budget, fine-grained sparse pruning still provides a benefit while coarser structured pruning can be matched or exceeded. Therefore, pruning is recommended when training tokens are limited, but training from scratch is competitive for coarse-grained pruning when tokens are abundant.
Introduction
As large language models scale, pruning becomes critical for reducing inference costs, but prior work rarely examines how pruning granularity and retraining data interact under token-limited budgets. The authors address this gap by systematically evaluating six pruning methods across depth, width, and sparse granularities within a continual pretraining framework, revealing nuanced trade-offs between compression rate, accuracy retention, and data efficiency.
Experiment
This work frames pruning as an initialization strategy and compares it against training from scratch under two token-matched settings, using Llama-3.1-8B as the parent model and six pruning methods spanning structured and sparse granularities. Under an equal training token budget, pruned initialization consistently beats random initialization, though this advantage shrinks as the pruning ratio increases and nearly vanishes at the most aggressive compression. When scratch training is granted the full token budget of the entire pruning pipeline, it catches up to coarse structured pruning, but fine-grained sparse pruning retains its lead, showing that parent knowledge can transfer benefits that additional training tokens alone cannot recover.
The authors evaluate Minitron depth pruning initialization against training from scratch across varying retraining token budgets. Results demonstrate that pruning initialization consistently yields lower loss and perplexity along with higher downstream accuracy compared to random initialization. However, this performance advantage diminishes as the retraining token budget increases. Pruning initialization consistently outperforms random initialization across all evaluated token budgets. The performance gap between pruned and scratch-trained models narrows as the retraining token budget grows. Initializing from a released model checkpoint yields performance comparable to or slightly better than using a custom pretrained checkpoint.
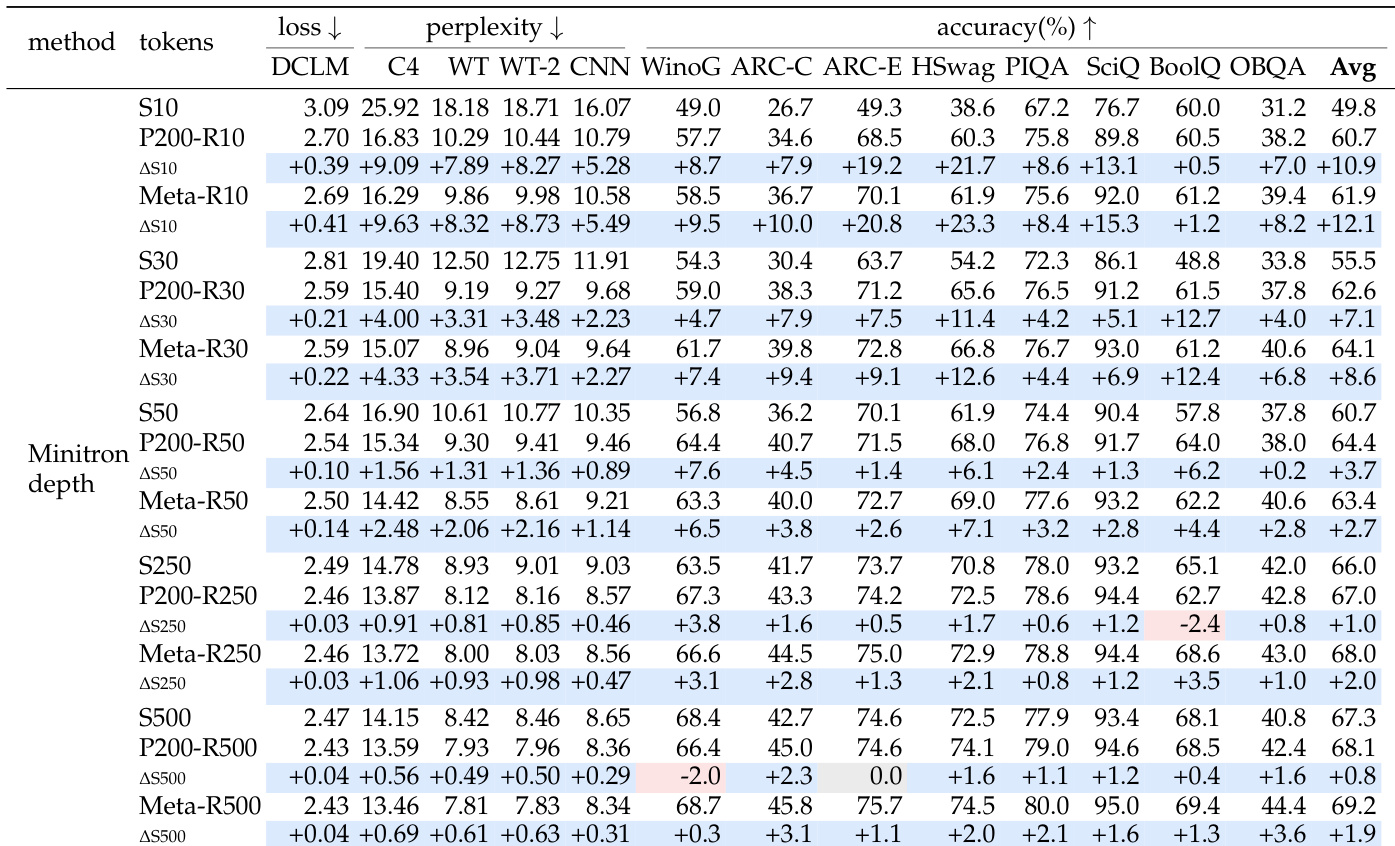
The authors compare pruning initialization against training from scratch under equal training token budgets and equal total token budgets. Results show that pruning initialization consistently outperforms random initialization when the training token budget is equal. However, when the scratch model is trained with the full token budget of the pruning pipeline, it becomes competitive with structured pruning methods, while finer sparse pruning methods retain their advantage. Under an equal training token budget, the pruned initialization consistently achieves lower perplexity and higher average accuracy than training from scratch across all evaluated methods. When given the full token budget, training from scratch becomes competitive with or surpasses coarser structured pruning methods, effectively closing the performance gap. Finer granularity sparse pruning maintains an accuracy advantage over training from scratch even when the total token budget is matched, unlike coarser structured methods.
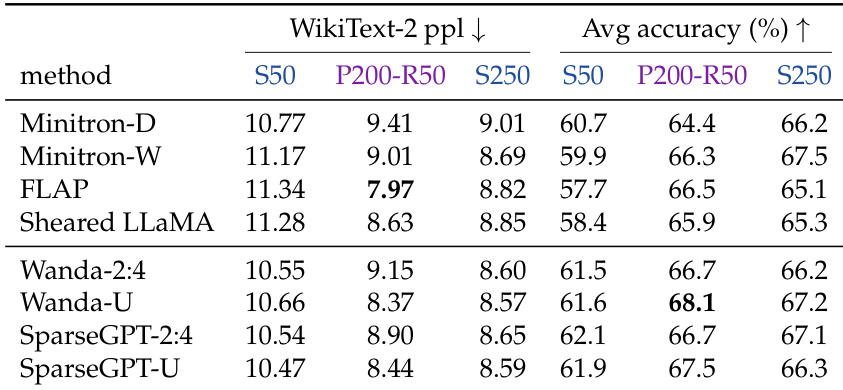
The authors compare pruning initialization against training from scratch under equal training token and equal total token budgets across various pruning methods and granularities. Results show that pruning initialization consistently outperforms random initialization when training token budgets are equal, though this advantage diminishes for coarser granularities when the total token budget is matched. Finer-grained sparse pruning methods retain a performance edge over training from scratch even when the scratch model is trained on the full token budget of the pruning pipeline. Pruning initialization consistently yields lower perplexity and higher downstream accuracy than training from scratch under an equal training token budget across all evaluated methods. When given the full token budget of the pruning pipeline, training from scratch matches or surpasses coarser structured pruning methods but struggles to catch up to finer sparse pruning methods. Finer pruning granularities provide a stronger initialization advantage and better preserve the parent model capabilities compared to coarser structured approaches.
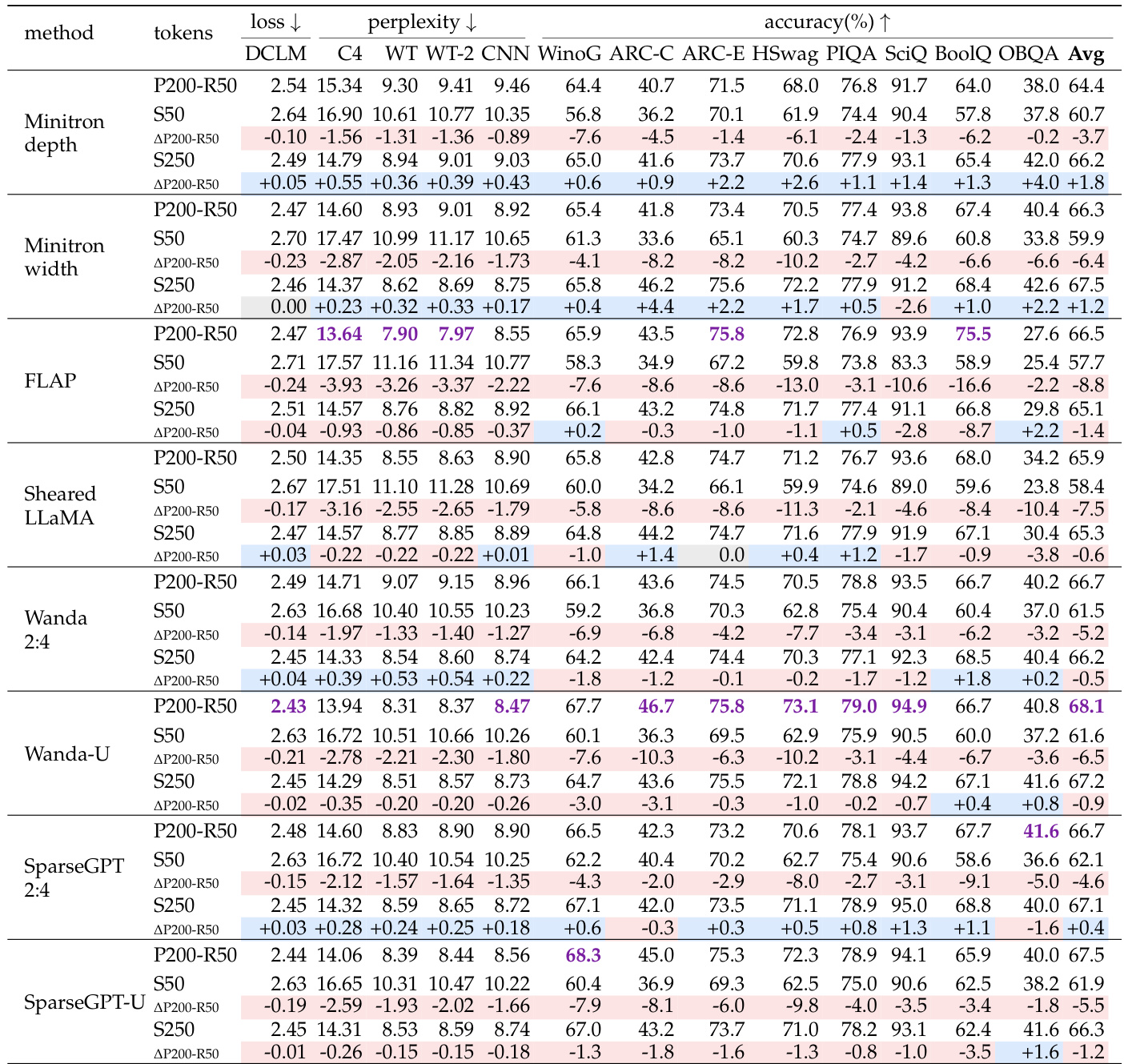
The authors evaluate the FLAP pruning method as an initialization strategy compared to training from scratch across various retraining token budgets. Results indicate that initializing with a pruned model consistently outperforms random initialization in terms of perplexity and downstream accuracy. However, the performance advantage of pruning diminishes as the retraining token budget increases, showing that additional training data helps close the gap between the two approaches. Pruned initialization consistently achieves lower perplexity and higher average accuracy than training from scratch across all evaluated token budgets. The performance advantage of pruning over scratch training diminishes as the number of retraining tokens increases. Initializing from a publicly released large model checkpoint yields slightly better results than the authors' custom pretraining pipeline.
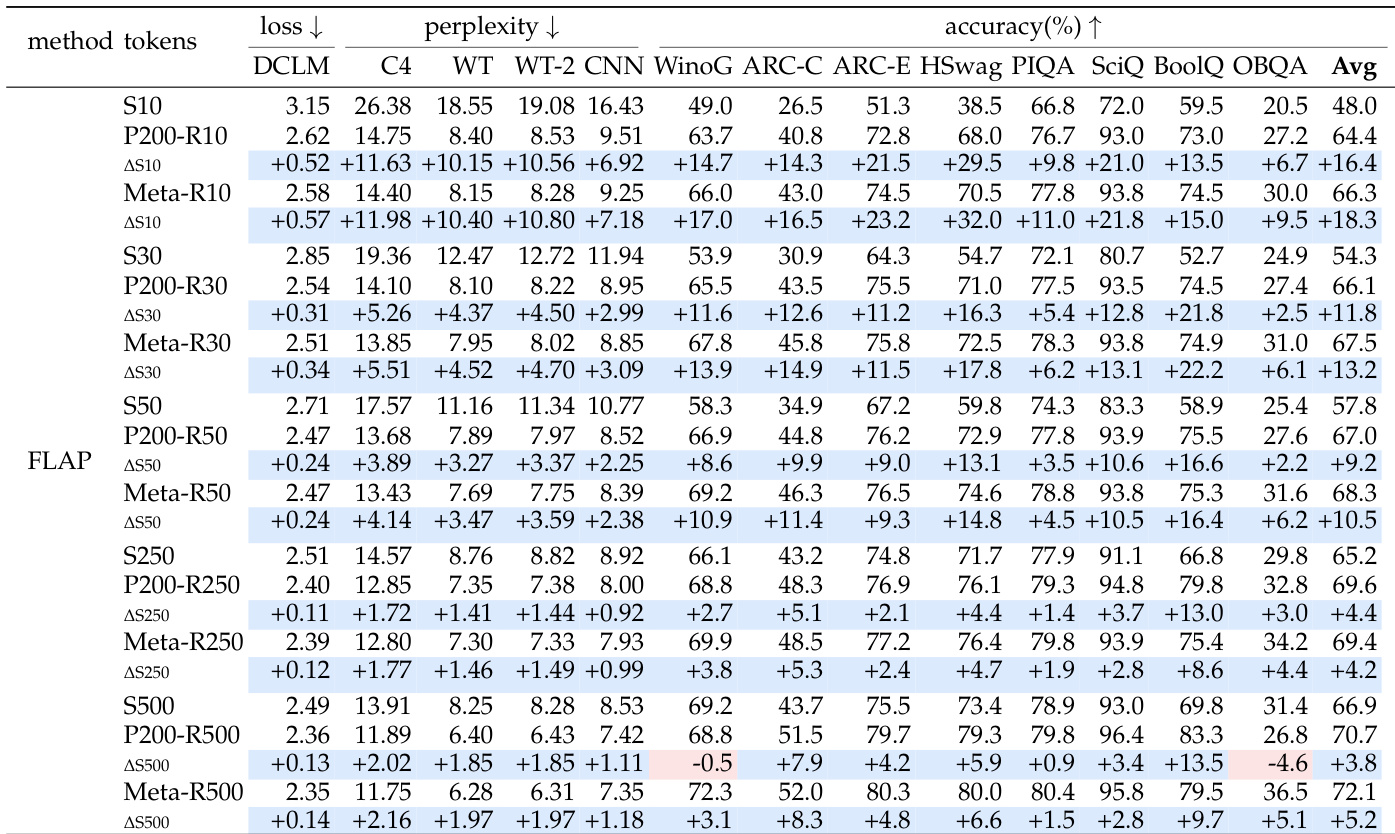
The authors compare pruning large language models against training from scratch, utilizing an architecture search to define target model configurations at a standard pruning ratio. Results indicate that pruning initialization consistently outperforms random initialization under equal training budgets, acting as a token-efficient shortcut. However, this advantage diminishes with higher compression, and while coarse structured pruning can be matched by extended training, fine-grained sparse pruning retains its edge. Pruning initialization provides a strong starting point that beats random initialization under equal training token budgets. The advantage of pruning shrinks as the pruning ratio increases and the target model becomes smaller. Fine-grained sparse pruning outperforms training from scratch even when the scratch model is trained on the full token budget of the pruning pipeline.
Across multiple experimental setups comparing pruning initialization to training from scratch, pruning consistently yields lower perplexity and higher accuracy under equal retraining token budgets, though its advantage diminishes as the retraining token count increases or the pruning granularity becomes coarser. When training from scratch is allowed the full token budget of the pruning pipeline, it becomes competitive with or surpasses coarser structured methods, while finer sparse pruning approaches retain a clear performance edge. Utilizing a publicly released model checkpoint for initialization performs comparably to or slightly better than a custom pretrained checkpoint, and the overall findings confirm that pruning transfers valuable parent model knowledge, with the benefit most pronounced for fine-grained sparsity and limited retraining data.