Command Palette
Search for a command to run...
OmniRetrieval: Vereinheitlichter Abruf über heterogene Wissensquellen hinweg
OmniRetrieval: Vereinheitlichter Abruf über heterogene Wissensquellen hinweg
Jinheon Baek Soyeong Jeong Sangwoo Park Woongyeong Yeo Minki Kang Patara Trirat Heejun Lee Sung Ju Hwang
Zusammenfassung
Reale Informationsbedürfnisse erfordern den Zugriff auf strukturell vielfältige Wissensquellen, von unstrukturiertem Text und relationalen Tabellen bis hin zu Wissensgraphen und Eigenschaftsgraphen. Bestehende Retrievers operieren jedoch jeweils nur auf einer Quelle unter einer festen Abfragesprache, wodurch die umfassendere Landschaft verfügbaren Wissens hinter inkompatiblen Schnittstellen fragmentiert bleibt. Ein naheliegender Versuch zur Vereinheitlichung würde diese Quellen in einen gemeinsamen Raum überführen, doch dies würde die strukturellen affordances (wie Schemata, Ontologien und kompositionelle Operatoren) auslöschen, die jeder Quelle ihre Ausdrucksstärke verleihen. Effektives Retrieval über diverse Wissensbestände erfordert daher keine Homogenisierung, sondern eine übergeordnete Schicht, die jede Quelle nach ihren eigenen Bedingungen bedient. Um dies zu erreichen, präsentieren wir OmniRetrieval, ein Framework, das beliebige Abfragen in natürlicher Sprache entgegennimmt, geeignete Wissensquellen identifiziert und quellen-native Abfragen an deren native Ausführungsmaschinen weiterleitet. In einem umfangreichen Benchmark, der 13 Datensätze und 309 verschiedene Wissensbasen über Text-, relationalen und graphenstrukturierten Quellen abdeckt, übertrifft OmniRetrieval Einzelquellen-Baselines und zeigt damit, dass es als allgemeine Schnittstelle zu den heterogenen Quellen dienen kann, während es die strukturellen Unterschiede bewahrt, die jede Quelle wertvoll machen.
One-sentence Summary
OmniRetrieval is a unified retrieval framework that accepts natural-language queries, identifies appropriate heterogeneous knowledge sources, and dispatches source-native queries to their native execution engines to preserve structural affordances, serving as a general-purpose interface that outperforms single-source baselines across 13 datasets and 309 distinct text, relational, and graph-structured knowledge bases.
Key Contributions
- OmniRetrieval is a unified retrieval framework that automatically selects appropriate knowledge sources and formulates queries in their native languages, thereby preserving the structural affordances of unstructured text, relational tables, and graph databases rather than flattening them into a shared representation.
- The framework implements a modular dispatch architecture that integrates existing text-to-query generators as pluggable components while addressing joint source selection, multi-language query formulation, and cross-form evidence consolidation within a single pipeline.
- Evaluation across a benchmark spanning 13 datasets and 309 knowledge bases demonstrates that the framework consistently outperforms single-source baselines, establishing it as a general-purpose interface for heterogeneous retrieval tasks.
Introduction
Real-world information needs frequently span unstructured text, relational tables, and knowledge graphs, making unified retrieval critical for accurate and comprehensive knowledge access. Prior retrieval systems typically operate within isolated silos, and while some attempts unify these sources by projecting them into shared embedding spaces, these methods flatten essential structural affordances and bias results toward surface-level similarity rather than semantic relevance. To overcome these limitations, the authors introduce OmniRetrieval, a framework that dynamically identifies relevant knowledge bases and formulates executable queries in each source's native language. By routing these queries to dedicated backends and consolidating the structurally diverse outputs, the system preserves the expressive power of each data type while providing a general-purpose interface that scales effortlessly to new repositories.
Dataset

- Dataset Composition and Sources: The authors compile a benchmark from 13 public datasets that collectively span four database backends and provide 309 distinct knowledge bases. All resources are sourced from existing public repositories and utilized under their original licenses for research purposes. The team does not apply additional filtering for personally identifiable information or offensive content, deferring to upstream dataset policies.
- Subset Details: Document search tasks utilize seven BEIR corpora covering medical, scientific, financial, web, Wikipedia, and multi-hop QA domains, with each corpus acting as an independent knowledge base. Relational database tasks draw from 206 Spider databases and 80 BIRD databases, totaling 286 SQLite files. RDF tasks map three datasets (SimpleQuestions, QALD-10, LC-QuAD 2.0) to a single Wikidata endpoint. Property graph tasks use 15 Neo4j graphs from Text2Cypher across domains like movies, finance, and social networks. The authors sample exactly 300 questions per dataset to standardize evaluation.
- Usage and Processing: The dataset is structured for benchmarking rather than training. The authors do not define training splits or mixture ratios, focusing instead on direct execution. Each sampled question is translated into the appropriate query language and run against the corresponding backend, whether local SQLite instances, public SPARQL endpoints, or Neo4j endpoints.
- Metadata and Context Construction: The authors generate a structural context descriptor for each backend to guide query generation. For document collections, the context is a brief topical summary outlining the domain and typical document style. Relational databases receive their full schema expressed through CREATE TABLE statements, including column types and key constraints. RDF contexts are built dynamically per question, combining fixed SPARQL prefixes, topic entities linked to Wikidata identifiers, and the top 30 candidate predicates ranked by semantic similarity. Property graphs are provided with a complete schema overview, detailing node labels, typed property keys, relationship types, and explicit edge triples.
Method
The OmniRetrieval framework is designed to enable cross-source retrieval across heterogeneous knowledge sources by operating through a unified access layer that coordinates three core stages: source selection, query formulation, and cross-source evidence selection. The overall architecture is structured to maintain the native query languages and structural semantics of each source while enabling a cohesive retrieval process. The framework begins by identifying relevant sources from a pool of independently maintained knowledge bases, each with its own native query language and structural context. This initial step is critical to ensure that subsequent operations leverage the appropriate backend for each source, preserving the expressiveness of native operators such as joins, traversals, and path queries.
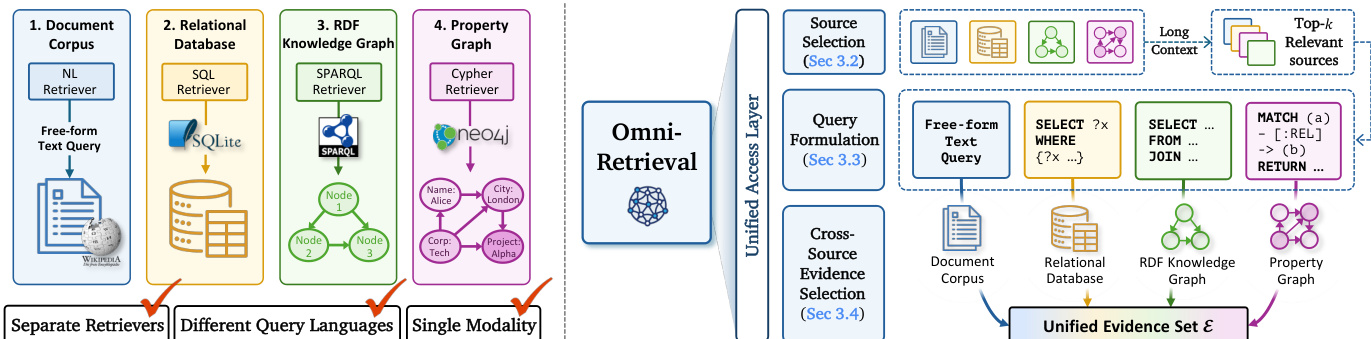
As shown in the figure below, the framework processes the user question q through a long-context language model to select a subset of relevant sources from the pool B. This selection is performed by encoding both the query and the structural descriptors cb of all available sources into the model's input, allowing the model to rank sources based on their relevance to the question. The output of this stage is a ranked list S of up to k sources, which is then used to proceed to the next phase. The long-context capability enables the model to reason over the full set of source descriptors, including schemas, ontologies, and corpus summaries, without requiring a uniform embedding space, thereby preserving the semantic distinctions between different types of structural contexts.

Following source selection, the framework formulates executable queries in the native language of each selected source. For each source b∈S, the system generates a query q^b conditioned on the source's structural context cb. This is achieved using a per-source prompt template that incorporates the user question q, the structural context cb, and an instruction specifying the target query language. The query generation leverages a single large language model (LLM) to produce valid queries in SQL, SPARQL, Cypher, or free-form text, depending on the backend. In the case of unstructured corpora, the question may be rewritten into a hypothetical passage to improve retrieval effectiveness, while for structured sources, the LLM directly emits the executable query in the appropriate language.
The final stage involves cross-source evidence selection, where the outputs from each source's execution engine are consolidated into a unified evidence set E. The framework takes as input the user question q and the executor outputs {Exec(b,q^b)}b∈S, which may vary in form—ranging from relational tuples to RDF triples or textual passages. To filter irrelevant results, the system uses a language model to evaluate each output in the context of the question. The model is prompted to identify which of the retrieved results best answers the question, effectively selecting the most relevant evidence across heterogeneous sources. This step ensures that the final output is both accurate and coherent, completing the retrieval task by returning a filtered subset of results that are semantically aligned with the user's query.
Experiment
The evaluation compares OmniRetrieval against single-backend, routing, and unified-representation baselines across document search, SQL, SPARQL, and Cypher paradigms using multiple language model backbones. The main benchmark validates that engaging multiple candidate sources and consolidating outputs through cross-source evidence selection consistently outperforms rigid single-paradigm approaches. Subsequent analyses on candidate size and model scale confirm that accurate initial source selection remains the most critical bottleneck, while evidence selection reliably recovers semantically correct answers even when the optimal source is initially missed. Finally, the comparison against unified representation methods demonstrates that preserving native query structures is essential for capturing complex relational compositions that shared embeddings cannot represent.
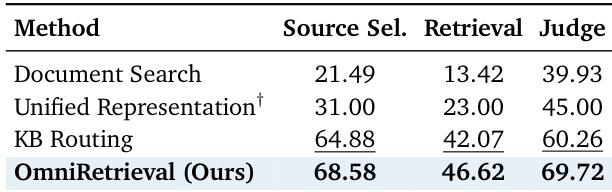
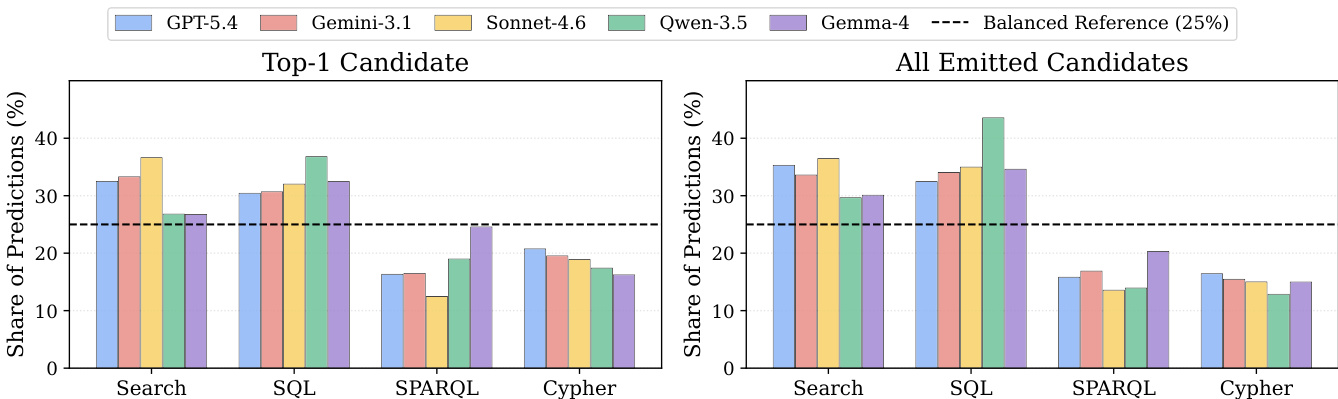
The authors compare OmniRetrieval against several baselines, including single-backend methods, KB Routing, and a unified representation approach, using metrics for source selection, retrieval quality, and LLM-based judgment. Results show that OmniRetrieval outperforms all baselines across the evaluated metrics, with significant gains in source selection and retrieval accuracy, while also achieving the highest judgment score. The framework's advantage stems from engaging multiple candidate sources and consolidating results through cross-source evidence selection, rather than relying on a single backend or unified representation. OmniRetrieval outperforms all baselines in source selection, retrieval accuracy, and LLM-based judgment metrics. The framework achieves the highest source selection accuracy and retrieval quality compared to single-backend methods and KB Routing. OmniRetrieval's performance is superior to a unified representation approach, demonstrating the benefit of native query execution over shared representation methods.
The authors evaluate OmniRetrieval against multiple baselines across different backbone models, demonstrating consistent performance improvements over single-backend and routing methods. Results show that OmniRetrieval achieves higher accuracy by engaging multiple sources and consolidating results through cross-source evidence selection, with gains particularly evident in structured paradigms like SQL and SPARQL. The framework's effectiveness is further supported by analyses indicating that broader source exploration and evidence selection are key drivers of its success. OmniRetrieval consistently outperforms single-backend and routing baselines across all backbone models and retrieval paradigms. The framework achieves higher accuracy by engaging multiple candidate sources and using cross-source evidence selection, particularly benefiting structured retrieval tasks. Performance improvements are most pronounced in structured paradigms, with gains narrowing as source selection accuracy increases.
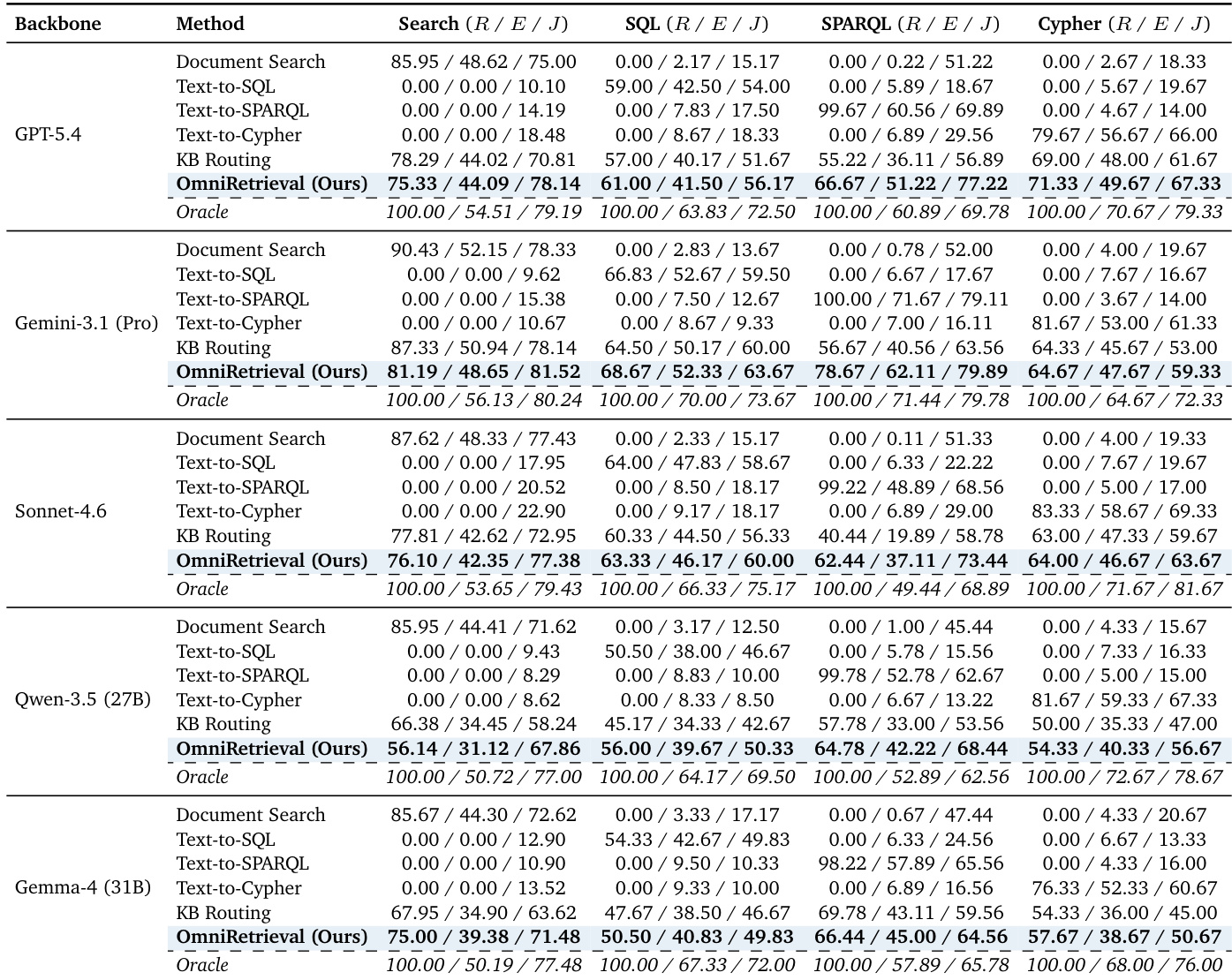
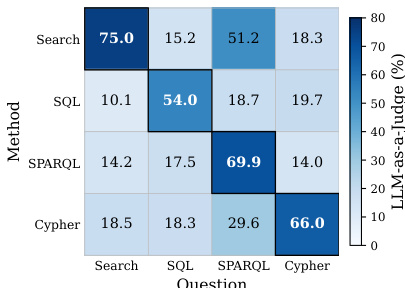
The authors evaluate a framework that engages multiple knowledge sources through their native query languages and consolidates results via cross-source evidence selection. Results show that the framework outperforms single-backend and routing baselines across all retrieval paradigms, with consistent gains in LLM-as-a-Judge accuracy, particularly when retrieving from diverse sources. The framework achieves higher performance than single-backend and routing baselines across all retrieval paradigms. The method shows consistent gains in LLM-as-a-Judge accuracy, especially when retrieving from multiple sources. Source selection remains balanced across paradigms despite a catalog dominated by relational databases.
The authors compare OmniRetrieval against multiple baselines across different backbone models, showing that OmniRetrieval consistently outperforms single-backend and KB Routing methods. Results indicate that source selection accuracy and retrieval quality improve with larger backbone models, though a gap remains compared to the Oracle upper bound. Evidence selection plays a key role in recovering correct answers even when source selection fails. OmniRetrieval consistently outperforms single-backend and KB Routing baselines across all backbone models. Larger backbone models show improved performance, with the gap to the Oracle upper bound narrowing as model scale increases. Evidence selection effectively recovers correct answers even when the gold source is not selected initially.
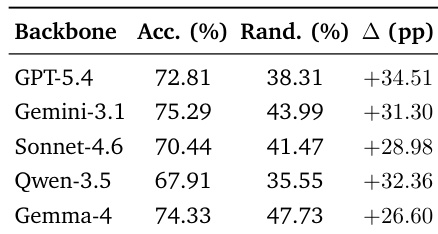
The authors analyze the distribution of predicted retrieval paradigms for different backbone models, showing that source selection remains broadly balanced across paradigms despite the underlying dataset imbalance. The top-1 candidate predictions are relatively consistent across models, while the full set of emitted candidates reveals higher diversity, particularly for the Search paradigm. The predictions for all models stay within a narrow range of the balanced reference line, indicating consistent paradigm allocation. Source selection predictions remain balanced across retrieval paradigms despite dataset imbalance. The full set of emitted candidates shows higher diversity compared to top-1 predictions, especially for the Search paradigm. All backbone models maintain predictions within a narrow range of the balanced reference line.
The experiments evaluate OmniRetrieval against single-backend, routing, and unified representation baselines across multiple backbone models and retrieval paradigms to validate the effectiveness of its native multi-source querying and cross-source evidence consolidation mechanisms. Results consistently demonstrate that the framework surpasses all comparative methods in source selection, retrieval accuracy, and LLM-based judgment, with particularly pronounced advantages in structured query tasks. The performance gains are primarily driven by the framework's ability to aggregate diverse knowledge bases, enabling robust evidence selection that successfully recovers correct answers even when initial source predictions are imperfect. Furthermore, the approach scales favorably with larger backbone models and maintains a balanced distribution across retrieval paradigms despite underlying dataset imbalances.