Command Palette
Search for a command to run...
Von Pixeln zu Wörtern -- Hin zu nativen One-Vision-Modellen im großen Maßstab
Von Pixeln zu Wörtern -- Hin zu nativen One-Vision-Modellen im großen Maßstab
Zusammenfassung
Aktuelle Vision-Language-Modelle (VLMs) verknüpfen typischerweise separate Bildencoder und Sprachdecoder mittels mehrstufiger Ausrichtung. Dieser modulare Ansatz fragmentiert unweigerlich Signale auf Pixelebene über Frames hinweg und zerstreut frühe Interaktionen zwischen Pixeln und Wörtern. Parallel dazu bleiben native VLMs trotz beeindruckender Leistungen bei der Verarbeitung einzelner Bilder in den Bereichen des Multi-Bild-Verständnisses, des Video-Verständnisses und der räumlichen Intelligenz weitgehend unerforscht. Daher präsentieren wir NEO-ov, ein natives Foundation-Modell, das die Korrespondenz über Frames hinweg sowie zwischen Pixeln und Wörtern end-to-end erlernt, ohne externe Encoder, zusätzliche Adapter oder post-hoc-Fusion. Durch die vollständige Aufhebung von Modulgrenzen ermöglicht NEO-ov, dass eine feinkörnige und einheitliche räumlich-zeitliche Modellierung nativ innerhalb des Modells entsteht. Bemerkenswerterweise schließt NEO-ov die Lücke zu modularen Gegenstücken weitgehend und zeichnet sich gleichzeitig durch eine herausragende feinkörnige visuelle Wahrnehmung aus. Dies bestätigt, dass native „One-Vision“-Architekturen nicht nur umsetzbar, sondern im großen Maßstab wettbewerbsfähig sind. Über die rein empirischen Leistungsergebnisse hinaus präsentieren wir systematische Architekturanalysen sowie detaillierte Trainingsrezepte, um die nachfolgende Entwicklung nativer multimodaler Modelle zu erleichtern. Unser Code sowie die Modelle sind öffentlich unter folgender Adresse verfügbar: https://github.com/EvolvingLMMs-Lab/NEO.
One-sentence Summary
NEO-ov is a native one-vision foundation model that learns pixel-word and cross-frame correspondences end-to-end without external encoders, adapters, or post-hoc fusion, eliminating modular boundaries to enable unified spatiotemporal modeling that achieves competitive performance at scale across multi-image, video, and fine-grained visual perception tasks.
Key Contributions
- The paper introduces NEO-ov, a native vision-language foundation model that eliminates pre-trained encoders and adapters to unify spatial and temporal modeling within a single monolithic backbone. By learning cross-frame and pixel-word correspondence end-to-end from raw inputs, the architecture preserves fine-grained visual signals for unified spatiotemporal reasoning.
- Benchmark evaluations demonstrate that the encoder-free model surpasses existing native VLMs and approaches encoder-based competitors across diverse multimodal tasks. The unified representation space captures low-level geometric perception, motion dynamics, and long-range visual dependencies, delivering robust spatial intelligence without fragmented feature alignment.
- The work presents systematic architectural analyses and detailed training recipes that document the design choices and optimization strategies for native multimodal modeling. These contributions validate the feasibility of native architectures at scale and facilitate subsequent research in unified vision-language systems.
Introduction
Current vision-language models are increasingly deployed for complex multimodal applications like video understanding, multi-image analysis, and spatial reasoning, yet they rely on a modular encoder-decoder architecture that connects pretrained vision encoders to large language models. This fragmented design forces early compression of visual signals, discards fine-grained spatial and texture details, and creates efficiency and scalability bottlenecks that hinder true cross-modal integration. To overcome these constraints, the authors introduce NEO-ov, a native one-vision foundation model that removes external encoders and adapters entirely. By training a single monolithic backbone end-to-end on raw inputs, the model learns pixel-word correspondence and spatiotemporal dynamics natively, delivering competitive performance across diverse benchmarks while providing a clear architectural blueprint for future unified multimodal systems.
Dataset

- Dataset composition and sources: The authors draw all resources from open-access datasets that feature explicitly defined usage policies.
- Key details for each subset: The provided excerpt does not specify subset sizes, individual sources, or filtering rules.
- Data usage and training configuration: The text does not outline training splits, mixture ratios, or how the data is integrated into the model.
- Processing and metadata: No cropping strategies, metadata construction, or additional preprocessing steps are described in the provided section.
- Additional procedural notes: The authors clarify that large language models served only as writing assistants for grammar and style refinement. All methodological, experimental, and conclusion content was developed and verified entirely by the human authors.
Method
The authors leverage a unified native vision-language backbone to extend autoregressive modeling across single-image, multi-image, and video inputs, forming a monolithic architecture that supports cross-image reasoning, temporal understanding, and spatial localization. The framework processes image and video inputs, along with text, into a unified sequence of tokens that are jointly processed by a single decoder-only model. Image inputs are encoded into visual tokens using a lightweight patch embedding layer composed of two convolutional layers with a GELU activation, producing one visual token for each 32×32 region. Text inputs are tokenized using the original language model tokenizer. Visual tokens are wrapped with <img> and </img> delimiters and concatenated with text tokens, forming a single sequence that is processed by the shared backbone. This approach enables efficient pixel-word and pixel-pixel alignment, as well as spatial-temporal reasoning within a single native framework.
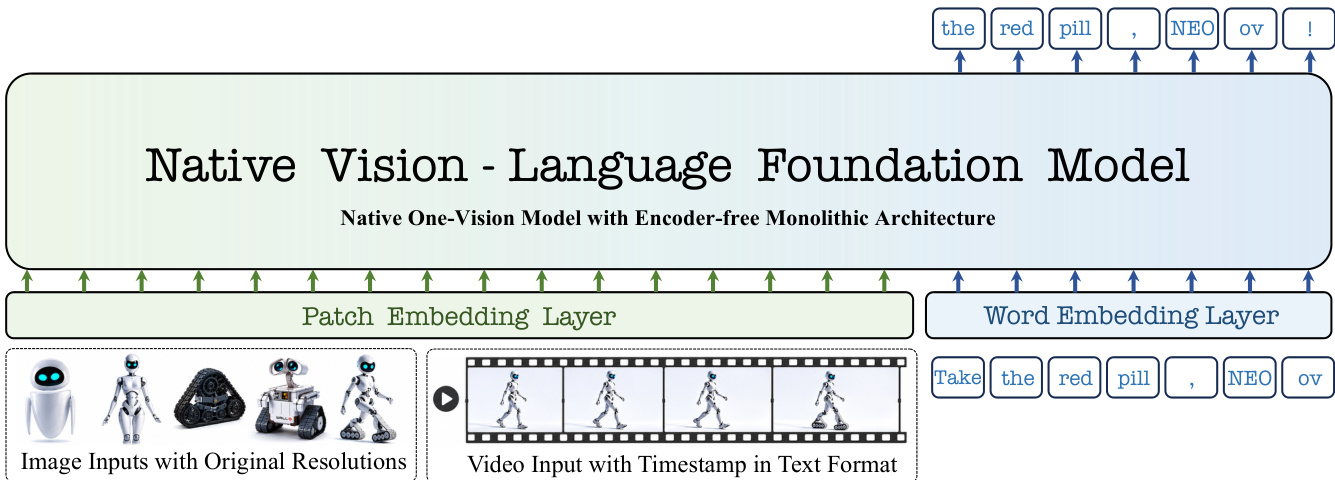
Refer to the framework diagram to understand how image and video inputs, represented at their original resolutions, are processed alongside text through a patch embedding layer and word embedding layer, respectively, to form a unified token sequence that enters the native vision-language backbone.
The model employs a THW-decoupled attention mechanism, where attention heads are explicitly designed with separate dimensions for temporal (T), height (H), and width (W) components. This design preserves the temporal modeling capability of the base language model while augmenting it with dedicated spatial modeling. For tokens i and j, the Query and Key features are decomposed into T, H, and W components, and their correlation is computed as the sum of inner products across each dimension. The T branch captures textual order, cross-image relations, and cross-frame dependencies, while the H and W branches model 2D spatial structure. This is complemented by native rotary positional embeddings (Native-RoPE), which assign distinct indices for temporal and spatial positions. Text tokens retain only the temporal index, with spatial indices set to zero, whereas image tokens share a common temporal index within each image and use hi and wi to encode their spatial coordinates. Temporal indices remain continuous across modalities, while spatial indices are independently defined within each image.
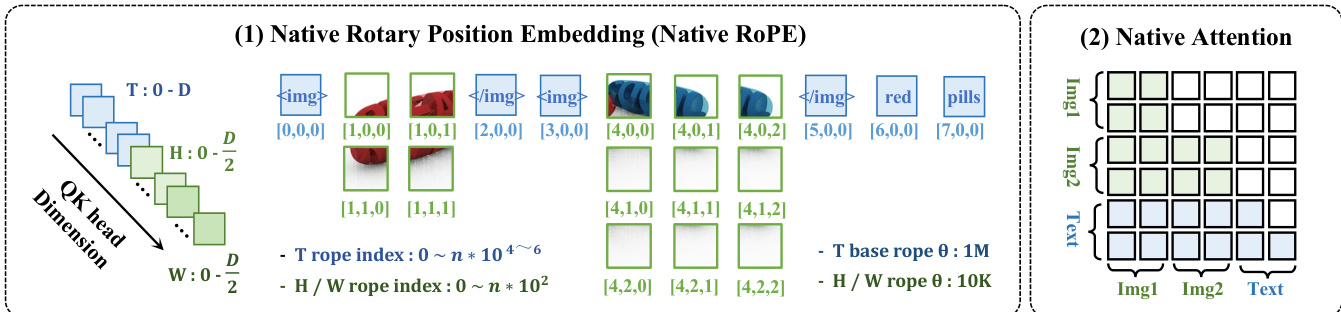
As shown in the figure below, the native rotary position embedding system unifies bidirectional spatial interactions within images with causal dependencies across text and video frames through a THW-aware frequency channel and index allocation, enabling unified modeling across single-image, multi-image, and video understanding.
For multi-image inputs, each <img> token in the prompt is replaced by an independent visual segment, preserving the textual order and representing each image as a distinct unit in the sequence. This allows images to be encoded at arbitrary resolution, adapting the number of visual tokens to the image's spatial size, which is beneficial for fine-grained comparison and spatially sensitive tasks. For video inputs, the model represents the video as a temporally ordered sequence of sampled frames, each serialized as an image unit with an associated timestamp. A global prefix encoding the video duration, number of sampled frames, and sampling rate is prepended, and explicit timestamps are included to facilitate temporal localization and cross-frame reasoning.
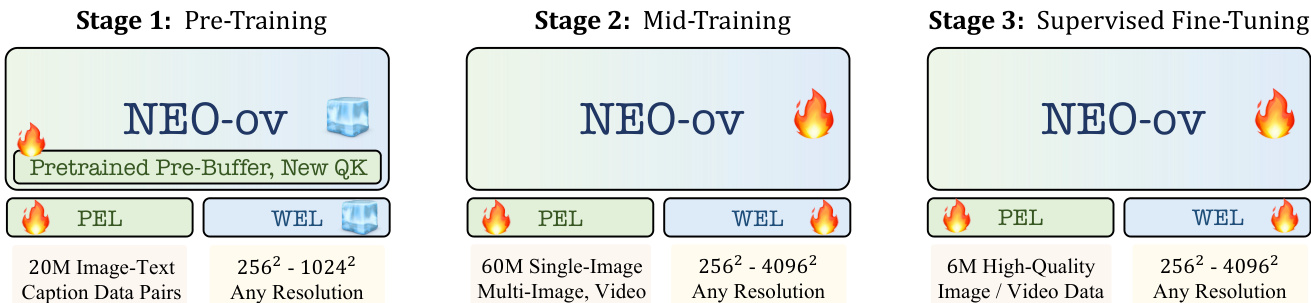
The training procedure for NEO-ov consists of three progressive stages. In the pre-training stage, the model develops foundational visual perception while aligning visual representations with the language backbone's semantic space. Optimization is restricted to the patch embedding layers, pre-buffer layers, and newly introduced QK-related parameters, using an autoregressive next-token objective. The mid-training stage scales spatial-temporal reasoning and enhances perception over high-resolution visual content, with all model layers jointly optimized on a diverse dataset. The context length is progressively extended, and a unified mixture of data types is used to improve stability and generalization. In the supervised fine-tuning stage, the model is refined on high-quality instruction-tuning data, with end-to-end optimization to strengthen fine-grained perception, long-context reasoning, and temporal dynamics modeling.
Experiment
The evaluation assesses NEO-ov across image understanding, video comprehension, and spatial intelligence tasks, benchmarking it against both native and modular vision-language architectures while conducting ablation studies on attention mechanisms and training progression. The results demonstrate that native end-to-end modeling successfully preserves fine-grained visual context and long-range dependencies, enabling robust reasoning and effective hallucination suppression without external encoders. Additionally, deep pixel-level interactions and progressive training stages consistently strengthen spatial perception and cross-modal generalization, collectively validating the scalability and competitive advantage of unified native multimodal frameworks.
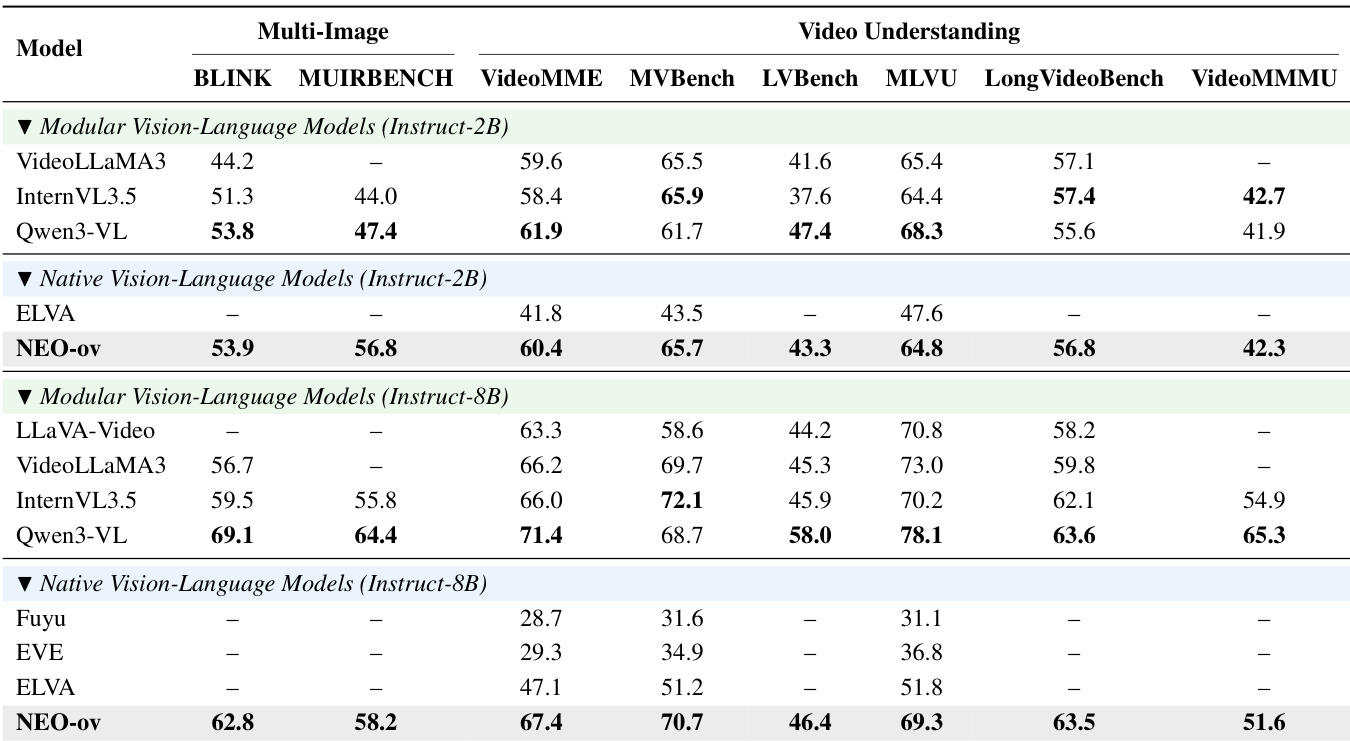
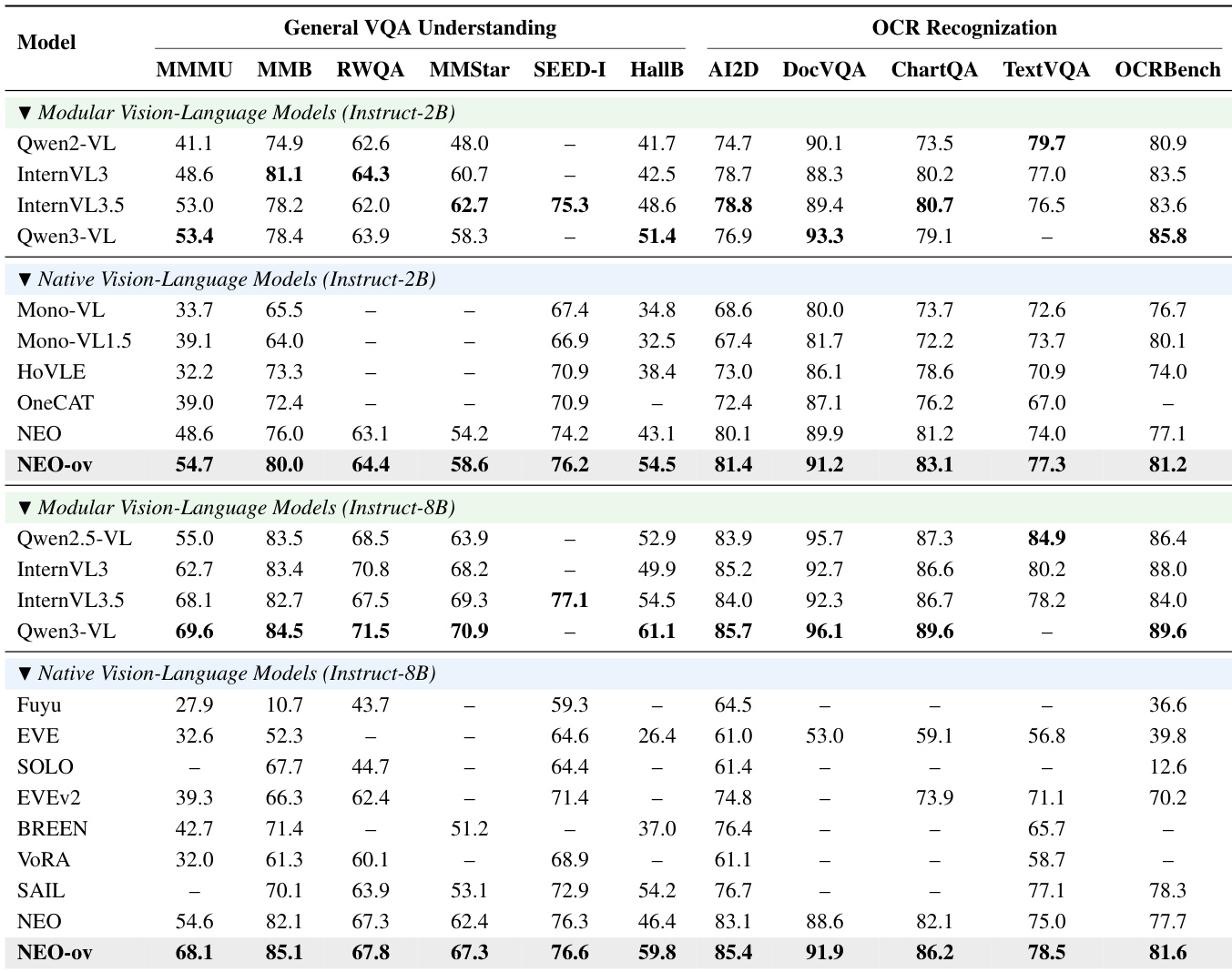
The authors evaluate NEO-ov on multi-image and video understanding benchmarks, comparing it against both modular and native vision-language models. Results show that NEO-ov achieves competitive or superior performance across various tasks, particularly in video understanding and multi-image reasoning, demonstrating the effectiveness of its native architecture. The model consistently outperforms prior native models and matches or exceeds modular counterparts in key areas such as temporal reasoning and long-context understanding. NEO-ov achieves competitive or superior performance compared to both modular and native vision-language models on multi-image and video understanding benchmarks. NEO-ov shows strong gains in video understanding tasks, particularly in long-context and temporal reasoning, outperforming several modular models. NEO-ov demonstrates consistent improvements across different scales and training stages, indicating effective progressive training for multimodal capabilities.
The authors evaluate NEO-ov across various benchmarks, comparing its performance to both specialized and general-purpose models. Results show that NEO-ov achieves competitive or superior performance, particularly in spatial intelligence tasks, and demonstrates strong scalability across different model sizes. The model consistently outperforms or matches leading alternatives on multiple benchmarks, highlighting its effectiveness in capturing fine-grained visual and spatial representations. NEO-ov achieves competitive or superior performance compared to spatial-specialist models on multiple spatial intelligence benchmarks. NEO-ov outperforms general-purpose models on several tasks, especially in spatial reasoning and geometric understanding. The model shows consistent performance improvements across different scales and training stages, indicating strong scalability and generalization.
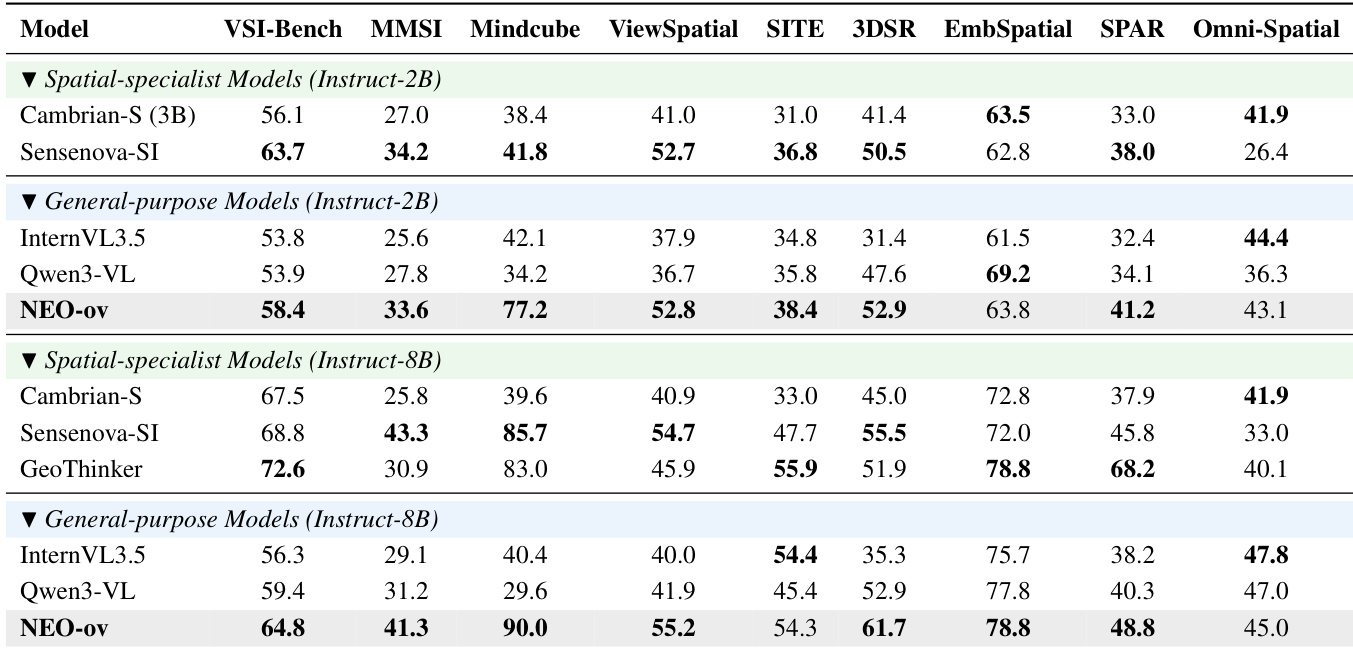
The authors evaluate NEO-ov across multiple domains including image understanding, video understanding, and spatial intelligence, demonstrating strong performance compared to both native and modular VLMs. The results show that progressive training stages improve performance across all benchmarks, with more significant gains observed at smaller model scales. The model achieves competitive or superior results on reasoning-intensive and hallucination-sensitive tasks, highlighting the effectiveness of native end-to-end modeling. NEO-ov achieves competitive or superior performance compared to both native and modular VLMs across diverse benchmarks. Progressive training stages consistently improve performance, with more pronounced gains at smaller model scales. NEO-ov shows strong performance on reasoning-intensive and hallucination-sensitive tasks, demonstrating the effectiveness of native modeling.
The authors evaluate NEO-ov on multiple benchmarks across image understanding, OCR recognition, video understanding, and spatial intelligence. Results show that NEO-ov achieves strong performance across various tasks, particularly excelling in reasoning-intensive and hallucination-sensitive scenarios. It demonstrates competitive or superior performance compared to both native and modular vision-language models, especially in tasks requiring fine-grained visual and spatial understanding. NEO-ov achieves strong performance on reasoning-intensive and hallucination-sensitive benchmarks, surpassing prior native and modular models. NEO-ov outperforms other models on OCR recognition and spatial intelligence tasks, highlighting its ability to capture fine-grained visual and spatial representations. The model shows consistent improvements across different scales and training stages, indicating effective learning and generalization capabilities.
The authors compare different architectural approaches for multimodal models, focusing on the performance of a native architecture with a pre-buffer mechanism against traditional encoder-based methods. Results show that the pre-buffer approach achieves competitive or superior performance across various tasks, particularly in OCR and spatial intelligence, suggesting that direct pixel-level interactions enhance visual understanding. The study also highlights that progressive training stages improve performance, especially for smaller model sizes, indicating effective learning of multimodal capabilities. The pre-buffer mechanism outperforms encoder-based methods on OCR and spatial intelligence tasks, indicating better handling of fine-grained visual details and spatial dependencies. Native architectures with direct pixel-pixel and pixel-word interactions show stronger performance on spatial intelligence benchmarks compared to encoder-based models. Progressive training stages lead to consistent performance improvements, with more significant gains observed in smaller model variants.
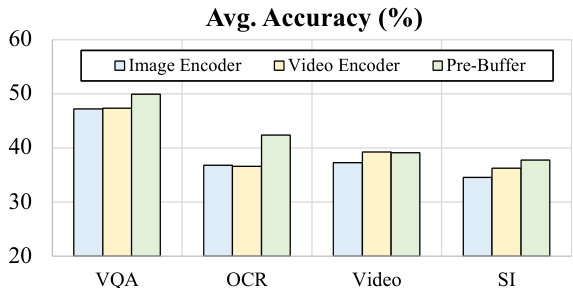
The authors evaluate NEO-ov across benchmarks covering multi-image and video understanding, spatial intelligence, and OCR recognition, comparing it against modular, native, and encoder-based vision-language models. These experiments validate the effectiveness of a native architecture utilizing a pre-buffer mechanism for direct pixel-level interactions, alongside a progressive training strategy. Qualitatively, the model consistently delivers competitive or superior results, particularly excelling in temporal reasoning, spatial understanding, and hallucination-sensitive scenarios. Overall, the findings demonstrate that the proposed approach achieves strong scalability, captures fine-grained visual representations effectively, and generalizes reliably across different model scales.