Command Palette
Search for a command to run...
LocateAnything: Schnelle und hochwertige Visions-Sprache-Verankerung mit paralleler Box-Decodierung
LocateAnything: Schnelle und hochwertige Visions-Sprache-Verankerung mit paralleler Box-Decodierung
Zusammenfassung
Vision-Language-Modelle (VLMs) formulieren visuelles Grounding und Detektion üblicherweise als ein Koordinaten-token-Generierungsproblem, bei dem jede 2D-Box in mehrere 1D tokens serialisiert wird, die weitgehend unabhängig voneinander gelernt und decodiert werden. Diese token-by-token-Decodierung entspricht nicht der gekoppelten Struktur der Boxgeometrie und erzeugt aufgrund der strikt sequenziellen Generierung einen praktischen Inferenz-Engpass. Wir stellen LocateAnything vor, ein einheitliches generatives Framework für Grounding und Detektion, das auf Parallel Box Decoding (PBD) basiert. Durch das Decodieren geometrischer Elemente wie Begrenzungsrahmen und Punkte als atomare Einheiten in einem einzigen Schritt bewahrt LocateAnything die boxinterne geometrische Kohärenz und ermöglicht erhebliche Parallelität. Wir zeigen, dass PBD sowohl den Decodierdurchsatz als auch die Lokalisierungsgenauigkeit verbessert. Darüber hinaus entwickeln wir eine skalierbare Daten-Engine und kuratieren LocateAnything-Data, einen großskaligen Datensatz mit über 138 Millionen Trainingsbeispielen, der die Datenvielfalt für hochpräzise Lokalisierung erheblich steigert. Umfassende Evaluierungen zeigen, dass LocateAnything die Geschwindigkeits-Genauigkeits-Grenze vorantreibt, einen erheblich höheren Decodierdurchsatz erzielt und gleichzeitig die Lokalisierungsqualität bei hohem IoU über verschiedene Benchmarks hinweg verbessert. Die Ergebnisse unterstreichen die komplementären Vorteile von Parallel Box Decoding und großskaligen Trainingsdaten für die Ermöglichung eines effizienten und präzisen, einheitlichen visuellen Groundings und der Detektion.
One-sentence Summary
The authors introduce LocateAnything, a unified generative grounding and detection framework that replaces serial token decoding with Parallel Box Decoding to process bounding boxes as atomic units in a single step, preserving geometric coherence and enabling substantial parallelism alongside the 138-million-sample LocateAnything-Data dataset to advance the speed and accuracy frontier through higher decoding throughput and improved high-IoU localization across diverse benchmarks.
Key Contributions
- Introduce LocateAnything, a unified visual grounding and detection framework that replaces sequential coordinate token generation with Parallel Box Decoding (PBD) to predict bounding boxes or points as atomic units in a single parallel step.
- Preserve intra-box geometric coherence and support a flexible inference pipeline that dynamically selects between parallel, autoregressive, or hybrid decoding modes to balance computational throughput and output stability.
- Demonstrate state-of-the-art localization accuracy and up to a 2.5× inference speedup across diverse benchmarks, enabled by LocateAnything-Data, a large-scale dataset containing over 138 million training samples curated via a scalable data engine.
Introduction
Vision-language models are rapidly becoming the standard backbone for interactive and embodied systems, yet they require precise, low-latency spatial grounding to reliably translate natural language into actionable commands. Existing grounding methods typically serialize two-dimensional coordinates into one-dimensional token streams and rely on autoregressive next-token prediction, which creates a severe throughput bottleneck. Attempts to parallelize decoding with multi-token prediction ignore the inherent geometric coupling of spatial coordinates, often generating spurious correlations and unstable outputs. The authors leverage parallel box decoding to reframe visual localization by treating complete bounding boxes as atomic prediction units. This structural alignment enables simultaneous coordinate generation, delivering state-of-the-art accuracy while achieving up to a 2.5x speedup. The framework further introduces flexible inference modes to balance throughput and reliability for real-world deployment.
Dataset

• Dataset Composition and Sources The authors curate LocateAnything-Data, a large-scale corpus comprising 12 million unique images, 138 million natural language queries, and 785 million annotated bounding boxes. The collection aggregates high-quality open-source detection and grounding benchmarks, including Flickr30k Entities, gRefCOCO, RefCOCO, HumanPart, HumanRef, OpenImages, and Objects365. It also integrates graphical user interface datasets, specialized referring comprehension corpora, and extensive unlabeled imagery sourced from Unsplash and SA-1B.
• Subset Breakdown and Key Details The dataset is structured around six distinct grounding tasks, each maintaining specific proportions and characteristics:
- General object detection: 66.9% of queries and 83.1% of bounding boxes, establishing the core spatial alignment foundation.
- GUI element grounding: 16.5% of queries, optimized for interface navigation and embodied agent workflows.
- Referring comprehension: 7.3% of queries, designed to link complex linguistic descriptions to precise spatial regions.
- Text localization: 3.6% of queries, focusing on tightly grounding visible text within images.
- Document and scene layout grounding: 3.5% of queries, enhancing structural reasoning capabilities.
- Point-based localization: 2.2% of queries, refining fine-grained spatial predictions. The corpus also incorporates over 22 million explicitly constructed negative samples across all domains to prevent model hallucination, with query-to-negative ratios calibrated per domain statistics. Target counts per query follow a long-tailed distribution, and query lengths vary significantly to reflect diverse linguistic grounding paradigms.
• Data Processing and Synthesis Pipeline The authors apply unified format cleaning and normalization across all raw sources. For the GroundCUA interface dataset, they implement a targeted cropping and augmentation strategy. They render each ground-truth bounding box on the original screenshot, crop a localized region around it, and feed both the full screenshot and cropped patch into Qwen3-VL alongside label, category, and platform metadata. The model then generates rich, multi-dimensional queries from three angles: appearance, spatial positioning, and functional intent. To expand multi-target grounding coverage, the team deploys an automated data engine. For labeled detection datasets, category prompts are sent to Qwen3-VL to synthesize detailed object-centric queries, which then guide Molmo to predict candidate points. Only points falling within known ground-truth boxes are retained as reliable supervision. For unlabeled images, Qwen3-VL directly generates diverse natural language prompts, which either trigger Molmo followed by SAM 3 for box generation, or directly invoke Rex-Omni for box prediction. All synthetically generated boxes undergo post-verification by Qwen3-VL to filter out inconsistent predictions.
• Training Usage and Mixture Strategy The processed dataset serves as the primary training corpus for the LocateAnything model. The authors blend the six domain subsets according to their natural proportions, maintaining the 66.9% general detection, 16.5% GUI, 7.3% referring, 3.6% text localization, 3.5% layout grounding, and 2.2% point-based localization mixture. This composition delivers dense, multi-domain supervisory signals that enable the model to learn precise coordinate alignments, handle heterogeneous visual scenarios, and confidently abstain from grounding when no valid target exists.
Experiment
The evaluation spans a comprehensive suite of benchmarks covering object detection, referring expression comprehension, GUI and document grounding, and OCR to validate the model's spatial reasoning and localization capabilities across diverse visual contexts. Main results and ablation studies confirm that the proposed parallel box decoding architecture and multi-token prediction formulation significantly enhance geometric precision and inference throughput compared to traditional generation methods. Qualitative analyses further demonstrate the framework's robustness in handling complex compositional queries, maintaining accurate instance separation in densely packed or occluded scenes, and effectively balancing speed and accuracy through flexible decoding strategies. Ultimately, these findings establish the approach as a highly effective and generalizable solution for unified visual grounding and detection tasks.
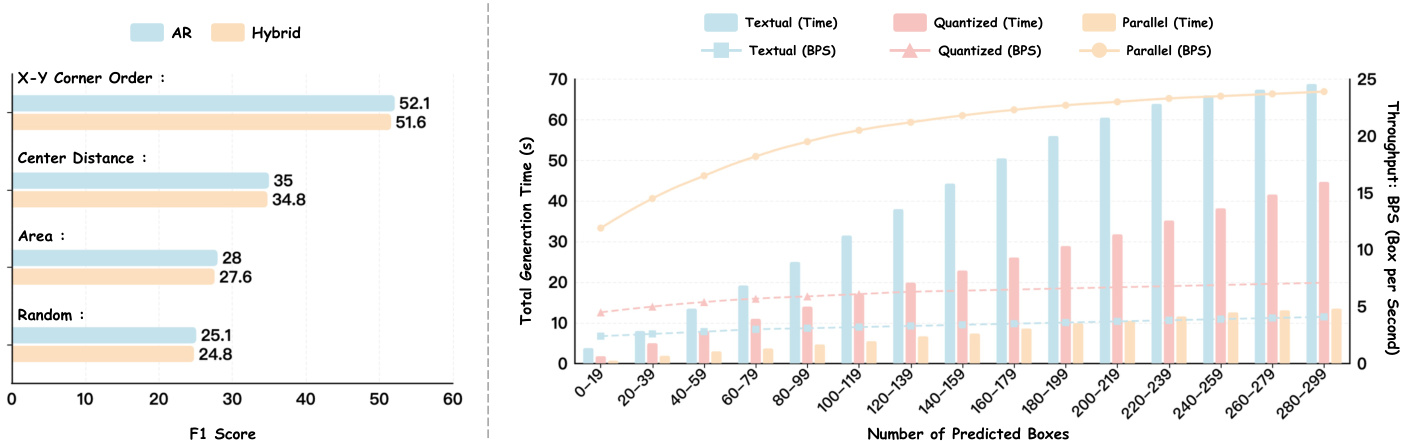
The authors analyze the impact of different box ordering strategies and decoding methods on model performance. The left chart shows that X-Y Corner Order achieves the highest F1 score among the tested sorting methods, while the right chart demonstrates that parallel decoding significantly reduces generation time and increases throughput compared to textual and quantized methods, especially as the number of predicted boxes grows. X-Y Corner Order yields the highest F1 score among the tested box sorting strategies. Parallel decoding reduces generation time and increases throughput compared to textual and quantized methods. Throughput improves with parallel decoding as the number of predicted boxes increases.
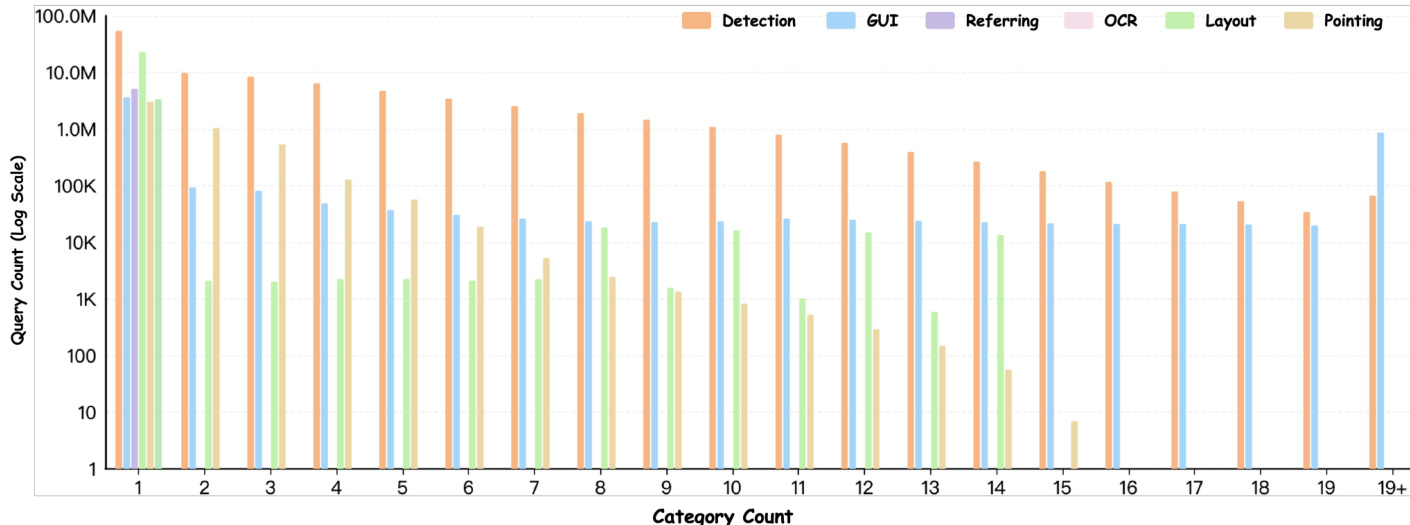
The authors analyze the distribution of query counts across different task categories and object instance counts, revealing that detection tasks dominate in both query volume and the number of object instances per image. The data shows a consistent pattern where detection-related queries are significantly more frequent than other tasks, and the number of queries generally decreases as the number of objects per image increases, with the highest counts observed for single-object instances. Detection tasks account for the majority of queries across all object instance counts. Query counts decrease as the number of objects per image increases, with the highest frequency observed for single-object instances. Other tasks such as GUI, referring, OCR, layout, and pointing have substantially lower query volumes compared to detection.
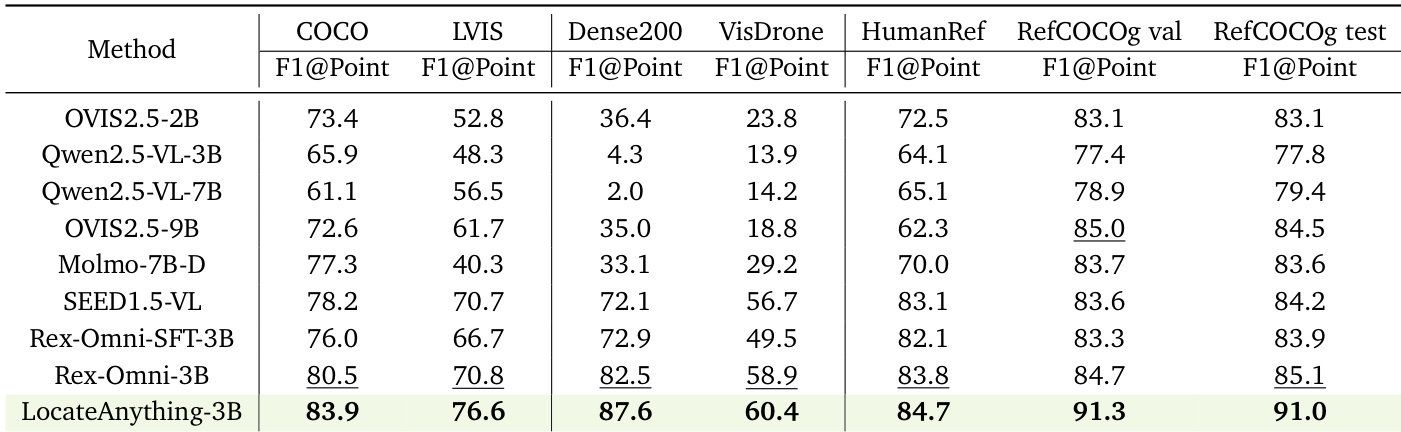
The authors evaluate LocateAnything-3B on multiple benchmarks, including dense object detection, language-aware grounding, and point-based localization tasks. The model demonstrates strong performance across various scenarios, particularly in dense and complex environments, while also achieving high decoding speed. Results show that LocateAnything outperforms several state-of-the-art models in terms of accuracy and efficiency. LocateAnything achieves superior performance on dense detection and language-aware grounding benchmarks compared to existing models. The model demonstrates high decoding speed, significantly outperforming text-based methods in terms of throughput. LocateAnything shows robust localization accuracy in challenging scenarios such as dense object detection and complex referring expressions.
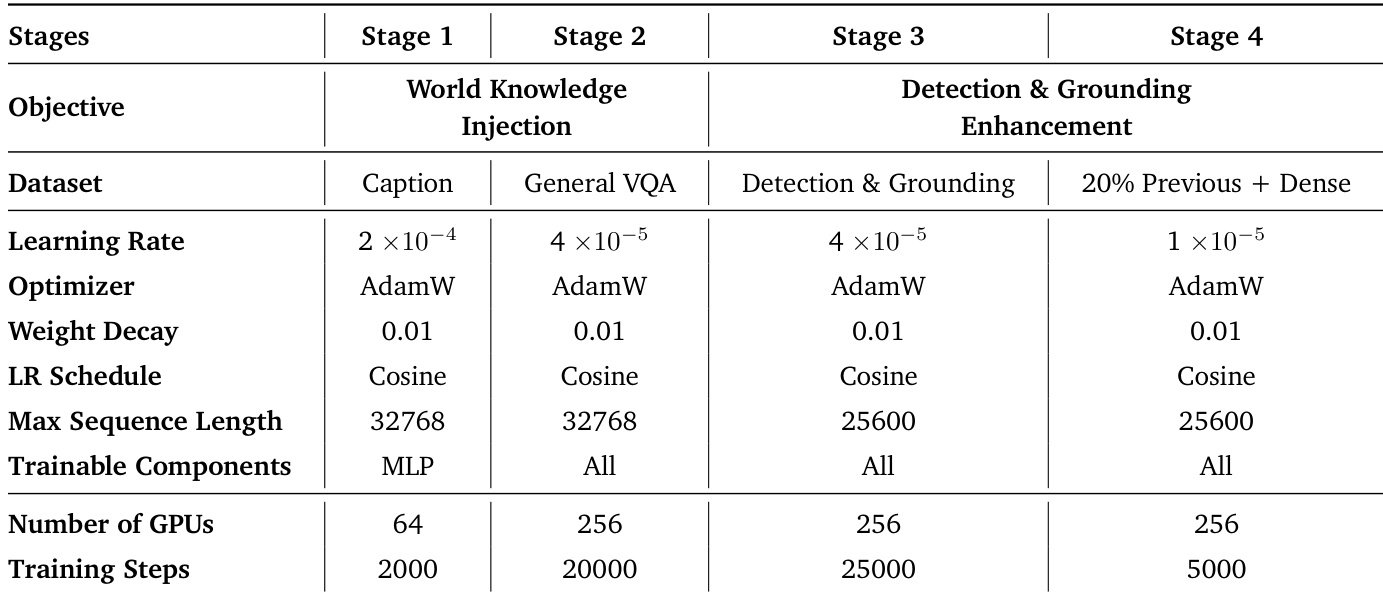
{"summary": "The the the table outlines a multi-stage training process for a vision-language model, beginning with world-knowledge alignment and progressing through stages focused on detection and grounding enhancement. Each stage uses distinct datasets and configurations, with increasing complexity and scale in terms of training steps and computational resources.", "highlights": ["The training process consists of four stages, starting with world-knowledge alignment and moving to detection and grounding enhancement.", "Training parameters such as learning rate and optimizer remain consistent across stages, while sequence length and training steps increase significantly in later stages.", "The number of GPUs used varies across stages, with the highest number employed during the detection and grounding enhancement phase."]
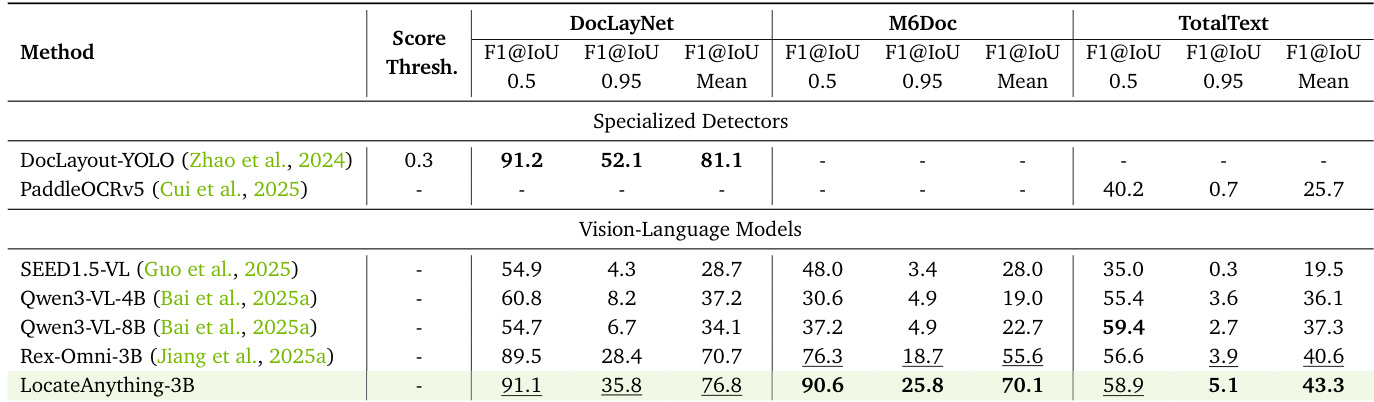
The the the table presents a comparison of various models on document layout grounding and OCR tasks across multiple benchmarks. LocateAnything-3B achieves the highest scores on most metrics, particularly excelling in F1@IoU 0.5 and F1@IoU 0.95 on DocLayNet and M6Doc, demonstrating strong performance in precise spatial localization. The results indicate that LocateAnything outperforms both specialized detectors and vision-language models, especially in dense and structured document scenarios. LocateAnything-3B achieves the highest F1 scores on DocLayNet and M6Doc, outperforming specialized detectors and other vision-language models. The model shows strong performance in both high and low IoU thresholds, indicating precise and robust localization. LocateAnything-3B surpasses Rex-Omni and other VLMs in OCR tasks, demonstrating superior boundary delineation and instance separation in document understanding.
The experimental evaluation examines architectural choices, real-world query distributions, and standardized benchmarks to validate the design and performance of LocateAnything-3B. Initial tests on internal components confirm that optimized box ordering and parallel decoding substantially enhance both prediction accuracy and computational throughput. Analysis of usage patterns reveals a dominant reliance on detection tasks, which directly informs the model's progressive training pipeline focused on grounding and spatial reasoning. Final benchmarking across dense detection, language-aware grounding, and document understanding demonstrates that the architecture consistently outperforms existing models, delivering superior localization precision and robust handling of complex scenarios.