Command Palette
Search for a command to run...
CollectionLoRA: Sammeln von 50 Effekten in 1 LoRA mittels Multi-Lehrer On-Policy Distillation
CollectionLoRA: Sammeln von 50 Effekten in 1 LoRA mittels Multi-Lehrer On-Policy Distillation
Fangtai Wu Hailong Guo Shijie Huang Jiayi Song Yubo Huang Mushui Liu Zhao Wang Yunlong Yu Jiaming Liu Ruihua Huang
Zusammenfassung
Die maßgeschneiderte Bildbearbeitung zielt darauf ab, vortrainierte Diffusionsmodelle unter Verwendung begrenzter gepaarter Daten mit spezifischen visuellen Effekten auszustatten, typischerweise mittels Low-Rank Adaptation (LoRA). Mit steigender Anzahl gewünschter Effekte führt das Speichern und dynamische Laden zahlreicher dieser Effekt-LoRAs zu einem erheblichen Anstieg des Bereitstellungsaufwands. Darüber hinaus werden in aktuellen Pipelines diese Effekt-LoRAs typischerweise mit Beschleunigungsmodulen für eine schnelle Generierung verkettet, was zu schwerwiegenden Parameterinterferenzen führt und Konzeptbleeding sowie eine Verschlechterung des Stils nach sich zieht. Wir präsentieren CollectionLoRA, ein Multi-Lehrer On-Policy-Distillierungsframework, das die Konzepte von bis zu 50 verschiedenen Effekt-LoRAs sowie die Fähigkeiten zur Few-Step-Generierung in ein einzelnes LoRA distillieren kann. Dies löst das Problem der Feature-Interferenz grundlegend und reduziert die Bereitstellungskosten erheblich. Konkret führt die Methode (i) einen Probabilistic Dual-Stream Routing-Mechanismus ein, der es dem Modell ermöglicht, während des Trainings zufällig zwischen Datenquellen zu wechseln, wodurch die Generalisierungsfähigkeit in unbekannten Szenarien effektiv verbessert wird; (ii) eine Asymmetric Orthogonal Prompting-Strategie zur Erzielung einer Konzeptisolierung im Prompt-Raum; (iii) ein Coarse-to-Fine Distillation Objective zur Verringerung der Verteilungsdifferenz zwischen den Lehrer- und Schülermodellen. Umfangreiche Evaluierungen zeigen, dass CollectionLoRA alle maßgeschneiderten Effekte sowie die Few-Step-Generierung in ein einzelnes LoRA distilliert, wodurch der Bereitstellungsaufwand reduziert wird, während eine Konzepttreue erreicht wird, die mit der unabhängig trainierter Lehrermodelle vergleichbar oder sogar überlegen ist.
One-sentence Summary
CollectionLoRA is a multi-teacher on-policy distillation framework that consolidates up to fifty customized visual effects and few-step generation capabilities into a single Low-Rank Adaptation module by integrating probabilistic dual-stream routing, asymmetric orthogonal prompting, and a coarse-to-fine distillation objective to resolve feature interference, thereby reducing deployment overhead while maintaining concept fidelity comparable to or better than independently trained models.
Key Contributions
- CollectionLoRA is a multi-teacher on-policy distillation framework that consolidates up to 50 customized visual effects and few-step generation capabilities into a single Low-Rank Adaptation module. This architecture eliminates parameter interference inherent in cascading multiple adapters and reduces deployment overhead to 0.5% of conventional pipelines.
- The framework integrates a Probabilistic Dual-Stream Routing mechanism, an Asymmetric Orthogonal Prompting strategy, and a Coarse-to-Fine Distillation Objective to stabilize multi-source training. These components enforce strict concept isolation in the prompt space and bridge distribution gaps between teacher and student models to prevent feature collapse.
- Extensive evaluations on the EffectBench benchmark demonstrate that the distilled model achieves concept fidelity comparable to or exceeding independently trained teachers while scaling to 180 distinct effects. The unified architecture further enables zero-shot effect composition at inference without requiring additional training or architectural modifications.
Introduction
Diffusion models have transformed customized image editing by enabling precise, high-quality content modification through task-specific Low-Rank Adaptation modules. However, deploying multiple specialized LoRAs alongside acceleration layers creates significant bottlenecks, including heavy storage overhead, dynamic routing latency, and parameter conflicts that cause concept bleeding and style degradation. To resolve these deployment challenges, the authors leverage multi-teacher on-policy distillation to introduce CollectionLoRA, a framework that consolidates diverse visual effects and few-step generation into a single unified module. They stabilize the training process through probabilistic dual-stream routing, asymmetric orthogonal prompting, and a coarse-to-fine distillation objective, which collectively preserve generalization, isolate conflicting concepts, and bridge distribution gaps. This architecture successfully compresses dozens of visual effects into one LoRA, drastically cutting deployment costs while enabling zero-shot effect composition without sacrificing fidelity.
Method
The authors leverage a multi-teacher on-policy distillation framework, CollectionLoRA, to consolidate up to 50 diverse visual effects and few-step generation capabilities into a single Low-Rank Adaptation (LoRA) module, thereby eliminating the deployment overhead and parameter interference associated with traditional multi-LoRA systems. The framework operates by training a student generator to approximate the output distributions of multiple pre-trained effect-specific teacher LoRAs, enabling a unified model that can generate diverse effects without dynamic loading or composition during inference.
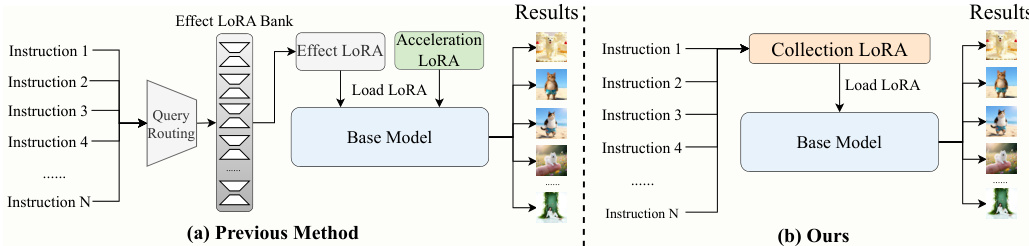
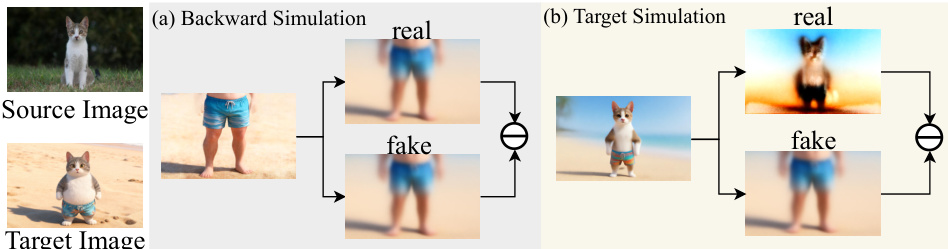
Refer to the framework diagram, which illustrates the overall architecture of CollectionLoRA. The method is built upon the principles of Distribution Matching Distillation (DMD), where the student generator is trained to match the data distribution of the teacher models. To ensure consistency with the few-step generation process used at inference, the framework employs backward simulation to generate training targets that simulate the cumulative sampling trajectory of multi-step inference. This involves iteratively denoising and re-noising a sample from pure noise until a specific timestep is reached, creating a simulated clean image that captures the desired generation characteristics. The generator is then trained to denoise a noisy version of this simulated sample, with the objective of matching the score functions of the real and fake distributions.
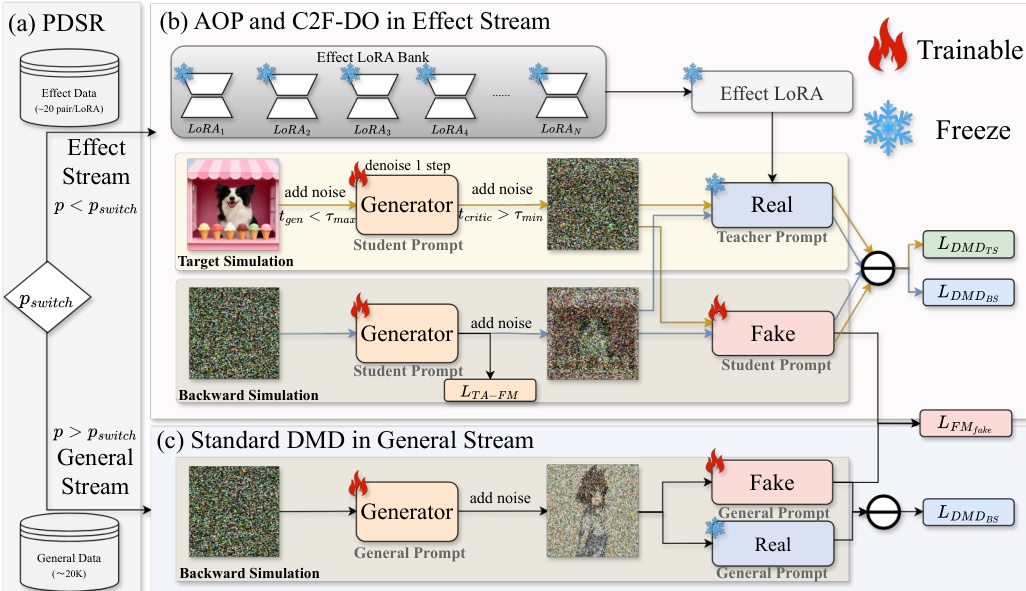
As shown in the figure below, the framework is structured around a probabilistic dual-stream routing mechanism, which dynamically allocates training batches to one of two streams based on a switching probability. In the general stream, the model is trained on unlabeled general-domain data using the frozen base model as the teacher, applying a standard DMD loss via backward simulation to maintain foundational generalization and prevent catastrophic forgetting. In the effect stream, the model focuses on integrating the specific visual effects. This stream utilizes a frozen effect LoRA from a bank as the teacher, and the student generator is trained to learn both the target distributions and denoising trajectories. The training process in the effect stream is further enhanced by a Coarse-to-Fine Distillation Objective to address the significant distribution gap between the student and teacher models during early training stages.
To mitigate feature interference and ensure concept isolation within the shared parameter space, the authors introduce an Asymmetric Orthogonal Prompting strategy. This approach uses distinct prompts for the teacher and student models. The teacher employs its original training prompt, while the student uses a unique orthogonal trigger word combined with a descriptive caption generated by a Vision-Language Model, ensuring clear separation of concepts. The Coarse-to-Fine Distillation Objective combines trajectory anchoring via flow matching to stabilize early training and target-simulated distribution matching to restore high-frequency details. The final overall objective is a weighted sum of the losses from the general and effect streams, determined by the routing decision at each iteration, ensuring the student model acquires both general knowledge and specific effect capabilities in a unified manner.
Experiment
Evaluated on a diverse benchmark across animal and portrait categories, the experimental setup compares the proposed framework against single-effect, accelerated, and unified multi-task baselines to validate generation fidelity, structural consistency, and deployment efficiency. Qualitative and quantitative analyses demonstrate that the joint distillation strategy effectively eliminates texture loss, style bleeding, and generalization collapse, while maintaining robust subject preservation under heavy concept compression. Further ablation and scaling experiments confirm that each architectural module addresses specific optimization bottlenecks, enabling seamless incremental extension, stable training dynamics, and an emergent zero-shot compositional capability without additional fine-tuning.
The authors conduct an ablation study to evaluate the impact of different components in their method under a 50-in-1 concurrent distillation setting. Results show that the full configuration, which includes all proposed components, achieves the best performance across multiple metrics, particularly in style alignment, subject consistency, and instruction-following quality, while significantly reducing failure rates. The study demonstrates that each component contributes to specific improvements, with the combination leading to stable training and superior overall results. The full model configuration achieves the highest scores in CLIP, DreamSim, VSA, EditReward, and the lowest Bad Case Rate compared to ablated versions. The integration of all components leads to stable training dynamics and improved convergence, outperforming configurations with only partial components. Each component contributes to specific improvements, such as reducing concept bleeding, restoring high-frequency textures, and enhancing structural consistency.

The authors compare their method against a baseline that combines a base model with acceleration LoRA, evaluating performance across varying numbers of LoRAs. Results show that their approach achieves consistently higher scores than the baseline across all tested configurations, with minimal variation in performance as the number of LoRAs increases. The proposed method outperforms the baseline across all tested numbers of LoRAs. The performance of the proposed method remains stable as the number of LoRAs increases. The baseline shows lower scores compared to the proposed method in all evaluated settings.

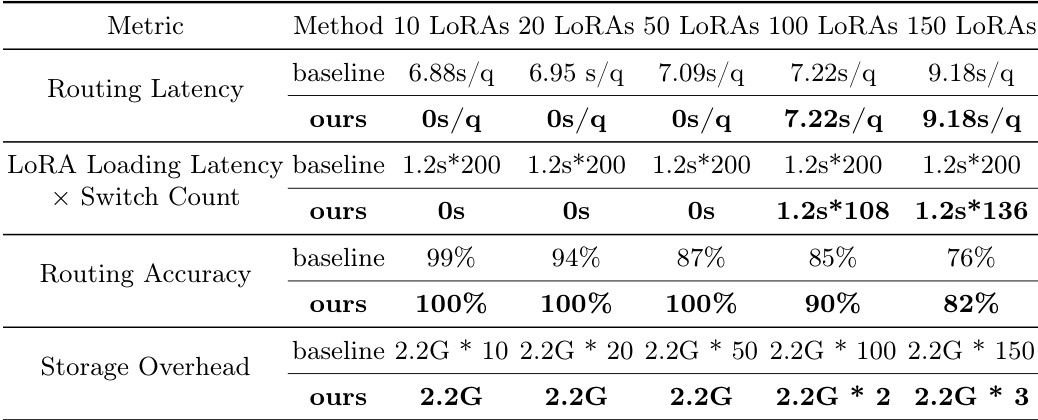
The authors compare their method against a baseline in terms of deployment efficiency, focusing on latency, accuracy, and storage overhead across varying numbers of LoRAs. Results show that their approach achieves zero routing latency, maintains 100% routing accuracy, and incurs a constant storage overhead, outperforming the baseline which exhibits increasing latency and decreasing accuracy as the number of LoRAs grows. The method demonstrates consistent performance regardless of the number of LoRAs, indicating robustness and scalability. The proposed method achieves zero routing latency and 100% routing accuracy across all LoRA configurations, outperforming the baseline which shows increasing latency and decreasing accuracy. The storage overhead remains constant at 2.2GB regardless of the number of LoRAs, in contrast to the baseline's linear growth. The method maintains stable performance with minimal degradation even as the number of LoRAs increases, demonstrating scalability and efficiency.
The authors evaluate a unified model for multi-effect image generation, comparing it against baseline methods across varying numbers of LoRAs. Results show that the proposed approach maintains competitive performance across different scales, outperforming alternatives in certain settings while demonstrating robustness to increasing complexity. The proposed method achieves competitive performance across varying numbers of LoRAs, outperforming baselines in some configurations. The model maintains stable performance as the number of LoRAs increases, showing robustness to scalability challenges. The approach consistently outperforms the baseline methods in specific scenarios, indicating effective handling of multi-concept fusion.

The authors conduct a quantitative evaluation comparing their proposed method against baseline approaches on a benchmark for multi-effect image generation. Results show that their approach achieves superior performance in style alignment and overall quality while significantly reducing failure rates, outperforming both single-effect and multi-task baselines. The method maintains strong subject consistency and demonstrates robustness under extreme concept compression and scaling. The proposed method outperforms baseline approaches in style alignment and overall image quality while achieving a substantially lower failure rate. The method maintains strong subject consistency and structural fidelity under extreme concept compression, despite marginal degradation in traditional metrics. The approach scales effectively to a large number of effects and supports incremental extension without catastrophic forgetting.

Ablation studies under a concurrent distillation setting confirm that each proposed component addresses specific limitations, with their full integration yielding stable training and significantly improved style alignment, subject consistency, and structural fidelity. Comparative evaluations across increasing adapter counts demonstrate that the method maintains consistent generation quality and deployment efficiency, avoiding the latency spikes and accuracy drops characteristic of baseline approaches. Additional benchmarks for multi-effect image generation further validate the model’s robustness to concept compression and scalability, showing that it effectively fuses multiple styles without catastrophic forgetting while delivering superior overall quality.