Command Palette
Search for a command to run...
Chi-Bench: Können KI-Agenten end-to-End-Prozesse in der Gesundheitsversorgung mit langer Horizontdauer und hoher Politikhäufigkeit automatisieren?
Chi-Bench: Können KI-Agenten end-to-End-Prozesse in der Gesundheitsversorgung mit langer Horizontdauer und hoher Politikhäufigkeit automatisieren?
Zusammenfassung
Die ende-zu-Ende-Automatisierung realistischer Gesundheitsdienstleistungsprozesse stellt drei Fähigkeiten in den Mittelpunkt, die in aktuellen Benchmarks unterrepräsentiert sind: eine hohe Politikdichte, da Entscheidungen auf einer umfangreichen Bibliothek medizinischer, versicherungsspezifischer und operatives Regeln basieren müssen; eine Multi-Rolle-Zusammensetzung, bei der eine einzelne Aufgabe vom Agenten erfordert, mehrere Rollen mit Übergaben (Handoffs) zu übernehmen; sowie eine multilaterale Interaktion, bei der Intermediate-Workflow-Schritte mehrstufige Dialoge umfassen, wie z.B. Peer-to-Peer-Reviews und Patientenansprache. Wir führen χ-Bench ein, einen Benchmark für langfristige Gesundheitsdienstleistungs-Workflows in drei Bereichen: Provider-Vorautorisierung, Payer-Utilization-Management und Care-Management. Jede Aufgabe übergibt dem Agenten einen klinischen Fall in einem hochrealistischen Simulator von 20 Gesundheits-Apps, die über 87 MCP-Tools zugänglich sind. Der Agent muss diese durch Tool-Aufrufe und das Erstellen von Rollendokumenten in einen Endzustand führen, unterstützt durch eine 1.279-seitige Anleitung zur Managed-Care-Operations-Fähigkeit. In 30 Agent-Harness/Modell-Konfigurationen löst der beste Agent nur 28,0 % der Aufgaben, kein Agent erreicht mehr als 20 % bei strenger Pass@3-Bewertung, und die Ausführung aller Aufgaben in einer einzigen Sitzung reduziert die Leistung auf 3,8 %. Diese Ergebnisse legen die Hypothese nahe, dass ähnliche Defizite auch in anderen politikintensiven, rollenbasierten und irreversiblen Unternehmensbereichen zutage treten könnten.
One-sentence Summary
The authors introduce Chi-Bench, a benchmark for long-horizon healthcare workflows across provider prior authorization, payer utilization management, and care management that evaluates AI agents on policy density, multi-role composition, and multilateral interaction within a high-fidelity simulator of 20 healthcare apps exposed via 87 MCP tools and guided by a 1,279-document managed-care operations handbook, where results from 30 agent harness/model configurations show the best agent resolves only 28.0% of tasks, raising the hypothesis that similar gaps exist in other policy-dense, role-composed, irreversible enterprise domains.
Key Contributions
- The paper introduces χ-Bench, a benchmark evaluating frontier agents on long-horizon healthcare workflows across provider prior authorization, payer utilization management, and care management. Each task presents a clinical case within a high-fidelity simulator requiring the agent to drive the case to a terminal status through tool calls and artifact writing.
- The environment challenges agents with policy density and multi-role composition by exposing 20 healthcare apps via 87 MCP tools and requiring adherence to a 1,279-document operations handbook. Agents must navigate multi-turn dialogs and terminal handoffs between roles such as clinician coordinator and UM nurse without the ability to edit or re-run submitted steps.
- Evaluation across 30 agent harness and model configurations demonstrates that current frontier models struggle to generalize long-horizon capabilities to these realistic workflows. The best configuration, Claude Code+Claude Opus 4.6, resolves only 28.0% of tasks at pass@1, while performance drops to 3.8% when executing all tasks in a single session.
Introduction
The U.S. healthcare system relies on inefficient administrative workflows like prior authorization and care management that demand strict adherence to complex policies and coordination across multiple clinical roles. Although frontier AI agents demonstrate success in coding benchmarks, they struggle with the policy density, multi-role composition, and multilateral interactions inherent to these realistic enterprise tasks. The authors introduce Chi-Bench to rigorously test agent performance in a high-fidelity simulator featuring 20 healthcare applications and extensive operational guidelines. Their evaluation demonstrates that current top-tier models fail to resolve the majority of these end-to-end tasks, indicating a significant gap between existing agent capabilities and the requirements of policy-rich healthcare automation.
Dataset
-
Dataset Composition and Sources
- The authors introduce χ-Bench, a benchmark for long-horizon healthcare workflows spanning provider prior authorization, payer utilization management, and care management.
- The environment simulates 20 healthcare applications accessible via 87 MCP tools and relies on a 1,279-document Managed-Care Operations Handbook developed with Johns Hopkins Medicine clinicians.
- All data consists of fictional composites with no real Protected Health Information to ensure privacy compliance and allow redistribution.
-
Key Details for Each Subset
- The final dataset contains 75 representative tasks filtered from an initial pool of 523 candidates generated via rejection sampling.
- Tasks are categorized by difficulty based on document count for prior authorization, clinical criteria depth for utilization management, and patient consent profiles for care management.
- The simulation environment includes 50 fictional patients and approximately 90 healthcare worker personas to support multi-role interactions and hidden state asymmetry.
-
How the Paper Uses the Data
- Researchers use the dataset to evaluate 30 different agent harness and model configurations rather than for model training.
- Agents must navigate the simulator to reach terminal states such as approval or denial through tool calls and artifact generation.
- Performance is measured by a two-layer verifier that checks deterministic world state changes and uses an LLM judge to validate policy citations and clinical reasoning.
-
Processing and Metadata
- Task construction involves generating cases anchored to specific policy sections with human validation by licensed clinicians to ensure clinical realism.
- Metadata includes stage-specific rubrics, canonical case records, and workspace files that track agent outputs and simulator states.
- Chart data is cropped to include only the target patient's information to prevent information leakage from unrelated cases.
Method
The authors leverage a realistic healthcare software environment to evaluate frontier agents on complex operational workflows. The system is built across three domains: provider prior authorization, payer utilization management, and care management. Refer to the framework diagram for the overall architecture where agents interact with the environment.
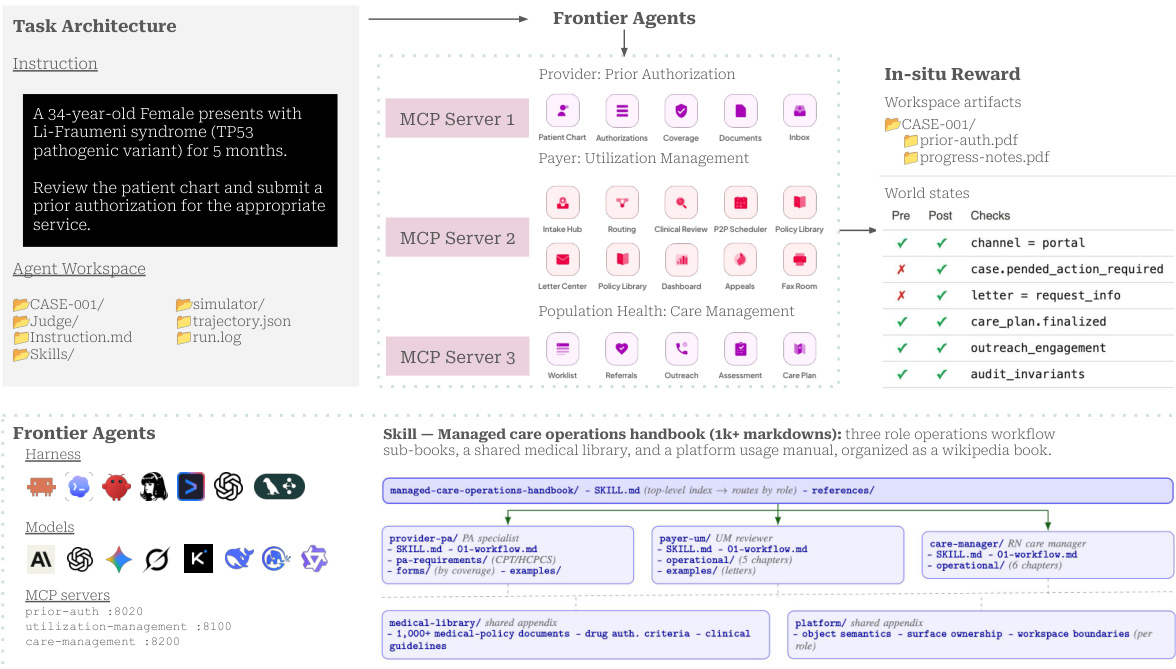
The environment exposes backend APIs as Model Context Protocol (MCP) tools, allowing agents to perform actions that trigger consistent cross-app effects. For example, a provider-side submission spawns a payer intake record and advances the event log.
To simulate realistic healthcare workflows, the authors encode specialized knowledge into a Managed-Care Operations Handbook. This skill acts as a wiki manual containing over 1,200 markdown documents organized by role.

The top-level skill routes the agent to role-specific sub-skills such as PA specialist or UM reviewer. Each sub-skill opens with a workflow chapter before diving into role-specific templates and appendices like a medical library of policies.
A task is formalized as a quadruple including instructions, the environment, role-scoped tools, and a verifier, modeled as a hierarchical POMDP M=(S,A,O,P,Z,R,ρ0;H). As shown in the figure below:
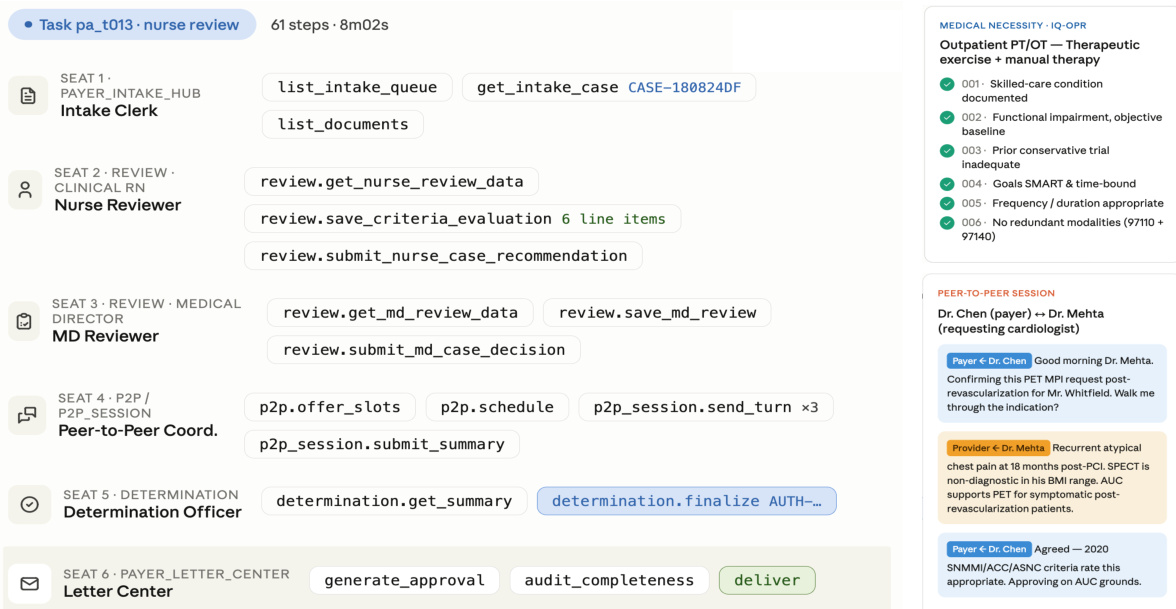
The execution trace illustrates a Payer UM task where multiple roles, such as the Nurse Reviewer and MD Reviewer, handle distinct stages. Handoffs are irreversible, with outgoing commits becoming incoming input for the next stage.
The environment reproduces end-to-end clinical operations that interlock through shared cases and documents. As shown in the figure below:
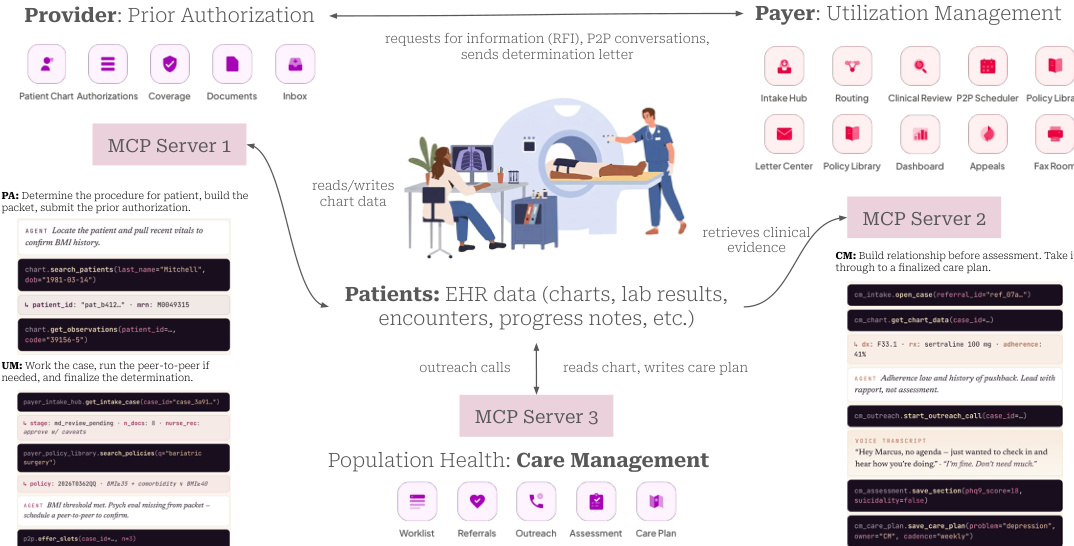
Provider agents submit requests which are processed by payer agents, while care management agents handle longitudinal patient outreach. Data flows through shared EHR records, ensuring that actions in one domain impact the state in another.
The system employs a two-layer verifier to score trials based on the simulator's persisted record. Refer to the verification pipeline diagram.
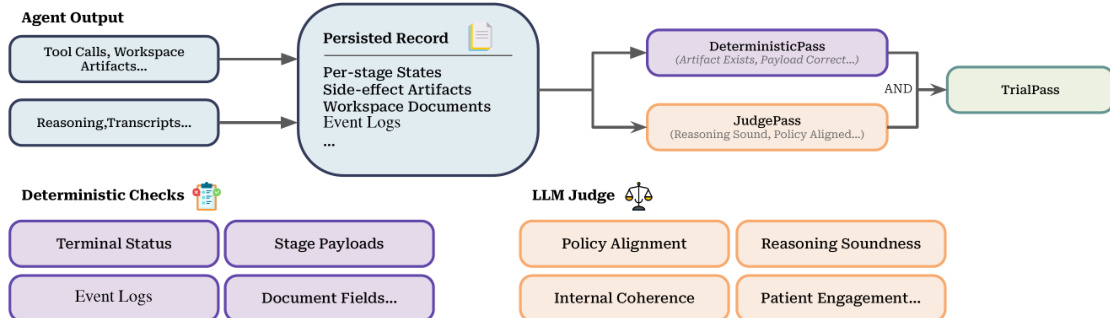
The pipeline combines a deterministic contract check with a rubric-based LLM judge. A trial passes only when both layers succeed, ensuring artifacts exist and reasoning is policy-aligned.
Experiment
This evaluation assesses thirty agent configurations across proprietary and open-source stacks using a high-fidelity healthcare benchmark covering prior authorization, utilization management, and care management. Results indicate that while top single-agent setups achieve modest success, performance collapses in multi-agent arenas and long-horizon marathon scenarios due to coordination failures and context limits. Detailed failure analysis attributes most errors to clinical reasoning mistakes and incomplete workflow execution, demonstrating that agents frequently misapply policies or violate autonomy protocols. Consequently, the authors conclude that deploying these systems for irreversible patient care workflows requires extreme caution due to persistent safety and reliability gaps.
The authors evaluate long-horizon agent capabilities by comparing isolated single-task trials against a marathon mode where agents process a queue of 25 tasks in a single session. Results show a severe degradation in pass rates across all healthcare domains when agents are required to manage multiple tasks simultaneously. Both evaluated configurations suffer a significant drop in success rates when transitioning from isolated tasks to the marathon setting. Utilization Management and Prior Authorization show substantial performance gaps between the single-task baseline and the marathon mode. Care Management presents a critical challenge in marathon mode, with performance collapsing to near-zero levels for one of the tested configurations.

The authors evaluate prior authorization workflows using a single-agent provider setup and an end-to-end two-agent system involving provider and payer roles. Results show that while the provider-only baseline achieves a pass rate of approximately 30 percent, adding the payer agent and cross-role checks causes performance to collapse to zero. This indicates that current agent configurations struggle significantly when required to coordinate across multiple roles in this domain. The provider-only baseline achieved a pass rate of roughly 30 percent. Introducing a payer agent and cross-role checks caused the pass rate to drop to zero. Failures in the two-agent setup included tasks that were never submitted or failed final verification checks.

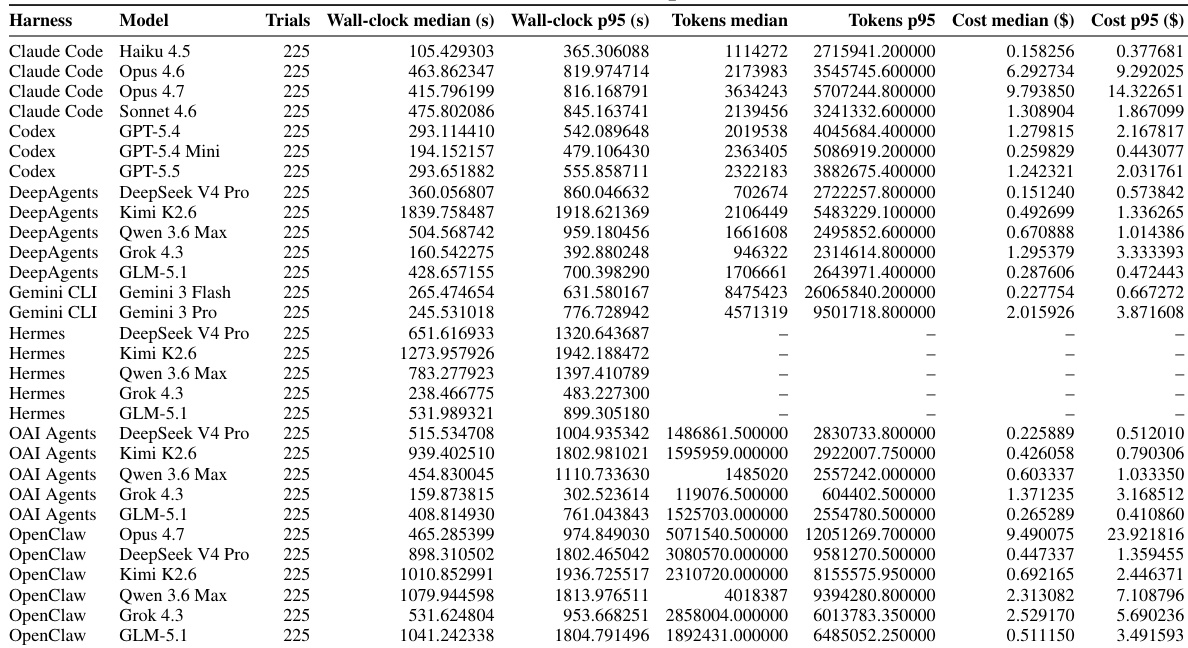
The the the table details efficiency metrics including wall-clock time, token usage, and cost across thirty agent harness and model configurations. Proprietary models generally incur higher expenses compared to open-weight alternatives, while some low-cost configurations like those using Kimi K2.6 exhibit significantly higher execution latencies. Variability in performance is evident as 95th percentile values consistently exceed median figures for both time and cost. Proprietary models such as Opus 4.6 and 4.7 show higher median costs than open-weight models. Configurations utilizing Kimi K2.6 demonstrate substantially longer wall-clock times relative to their cost efficiency. Token and cost data are unavailable for the Hermes harness rows in this dataset.
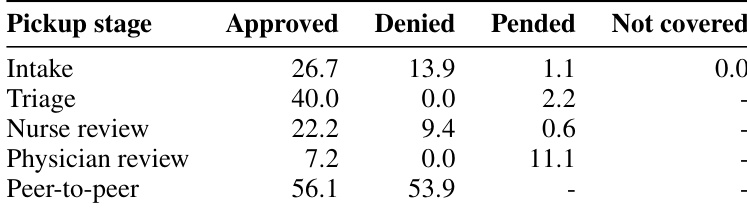
The the the table details the distribution of Utilization Management task outcomes across various pickup stages, showing how cases progress from intake to peer-to-peer review. Peer-to-peer review stands out as the stage with the highest engagement for final decisions, while earlier stages like intake and triage handle fewer denials. The associated text identifies the peer-to-peer stage as the most challenging due to the need for adversarial multi-turn dialogue. Peer-to-peer review generates the highest rates of both approved and denied outcomes compared to earlier stages. Unlike earlier stages, the peer-to-peer stage shows no pending cases, indicating it serves as a final decision point. The text identifies the peer-to-peer stage as the most difficult workflow component due to adversarial dialogue requirements.
The the the table stratifies agent performance across three healthcare domains and difficulty levels, indicating that success rates generally decline as task difficulty increases. Utilization Management demonstrates the highest success rates on easy tasks, while Care Management struggles significantly on hard tasks. Reliability metrics are consistently lower than single-trial success rates, pointing to consistency challenges. Performance trends downward as difficulty increases from Easy to Hard across all domains. Care Management exhibits the lowest success rates on hard tasks, with reliability metrics collapsing to near-zero. Single-trial success rates are consistently higher than reliability metrics, indicating run-to-run inconsistency.

The evaluation assesses healthcare agent capabilities by contrasting isolated single-task trials with marathon mode and comparing single-agent versus multi-agent workflows. Results demonstrate severe performance degradation in complex settings, particularly when agents must coordinate across roles or manage long horizons, causing success rates to collapse in Care Management and Prior Authorization domains. Efficiency analysis reveals cost and latency trade-offs across model configurations, while task distribution identifies peer-to-peer review as the most challenging stage due to adversarial dialogue requirements. Overall, reliability remains inconsistent as performance declines with increasing task difficulty.