Command Palette
Search for a command to run...
ViMU: Benchmarking Video Metaphorical Understanding
ViMU: Benchmarking Video Metaphorical Understanding
Qi Li Xinchao Wang
Zusammenfassung
Jedes neue Medium, sobald es auftritt, wird für mehr als nur die Übertragung offensichtlicher Inhalte genutzt. Die Information, die es transportiert, operiert in der Regel auf zwei Ebenen: Einerseits der direkt präsentierte Inhalt, andererseits das Subtext darunter – die impliziten Ideen und Absichten, die der Urheber durch das Medium vermitteln möchte. In ähnlicher Weise dient Video-Technologie, seit sie weit verbreitet ist, nicht nur als leistungsstarkes Werkzeug zur Aufzeichnung und Kommunikation visueller Informationen, sondern auch als Vehikel für Emotionen, Haltungen und soziale Bedeutungen, die oft schwer explizit auszudrücken sind. Somit liegt die wahre Bedeutung vieler Videos nicht ausschließlich in dem, was auf dem Bildschirm gezeigt wird; sie ist häufig in Kontext, Ausdrucksweise und der sozialen Erfahrung des Betrachters eingebettet. Einige Formen eines solchen Video-Subtexts sind humorvoll, während andere Ironie, Spott oder Kritik transportieren. Diese impliziten Bedeutungen können auch kulturell unterschiedlich interpretiert werden und variieren je nach sozialer Gruppe. Die meisten bestehenden Video-Verstehensmodelle konzentrieren sich jedoch weiterhin primär auf das wörtliche visuelle Verständnis, wie das Erkennen von Objekten, Aktionen oder zeitlichen Beziehungen, und verfügen über keine systematische Fähigkeit, die in Videos eingebetteten metaphorischen, ironischen und sozialen Bedeutungen zu verstehen.
One-sentence Summary
The authors propose ViMU, a benchmark evaluating video models on metaphorical, ironic, and social subtexts rather than literal visual comprehension to address the lack of systematic ability to understand implicit meanings in existing video understanding models.
Key Contributions
- ViMU is introduced as a benchmark designed to evaluate video models beyond literal perception by focusing on subtext understanding, including rhetorical, social, and culturally grounded meanings. The benchmark utilizes a structured taxonomy and hint-free questioning to require models to infer latent meaning from evolving multimodal signals.
- Evaluation results demonstrate that current frontier models struggle substantially with interpreting implicit meaning, achieving below 50% overall performance despite strong surface-level capabilities. These findings highlight a fundamental limitation of existing video understanding systems regarding nuanced social or cultural meaning.
- Fine-grained analyses reveal systematic gaps and distinct behavioral patterns across models when tasked with recovering intended readings without prior interpretive hypotheses. This evidence suggests that advancing toward robust interpretation requires modeling latent meaning in addition to visible content.
Introduction
Recent advances in large multimodal models have enabled effective video understanding for tasks like visual grounding, yet these systems remain largely confined to surface-visible content. Prior benchmarks often focus on implicit physical relations or narrow humor phenomena and rely on multiple-choice formats that inadvertently reveal subtext hypotheses. To address this gap, the authors introduce ViMU, a benchmark designed to evaluate whether models can recover underlying social subtext without explicit hints. They curated a high-quality dataset of 588 videos and 2,352 questions to test metaphorical understanding across diverse rhetorical mechanisms.
Dataset
- Dataset Composition and Sources
- The authors introduce ViMU, a benchmark containing 2,352 questions across 588 videos sourced from YouTube, Bilibili, and TikTok.
- Content targets subtext understanding through over 10 rhetoric mechanisms and social value signals.
- Key Details for Each Subset
- Tasks include open-ended interpretation, multiple-choice identification for rhetoric and social signals, and evidence grounding.
- Evidence sources cover visual frames, visible text, editing patterns, transcripts, and audio tone.
- Target subjects span individuals, social roles, institutions, and identity groups.
- All questions are hint-free to ensure models infer meaning without explicit cues.
- Model Usage and Evaluation
- The dataset serves strictly as an evaluation benchmark rather than a training resource.
- Experiments assess whether models can infer implicit meaning and ground interpretations in multimodal evidence.
- Performance metrics focus on open-ended accuracy and multiple-choice selection across semantic categories.
- Processing and Metadata Construction
- Curation follows a five-stage pipeline involving multimodal evidence extraction and LLM-driven annotation.
- Uniformly sampled frames and ASR transcripts are extracted to ground reasoning in observable signals.
- An iterative refinement loop validates question quality over up to three rounds to maintain difficulty.
- Five human experts validate the final set to ensure videos are self-contained without requiring external context.
- Fine-grained labels are aggregated into macro-level categories for consistent evaluation.
Method
The authors leverage a multi-stage pipeline to transform raw video data into a validated benchmark. Refer to the framework diagram for the overall architecture.
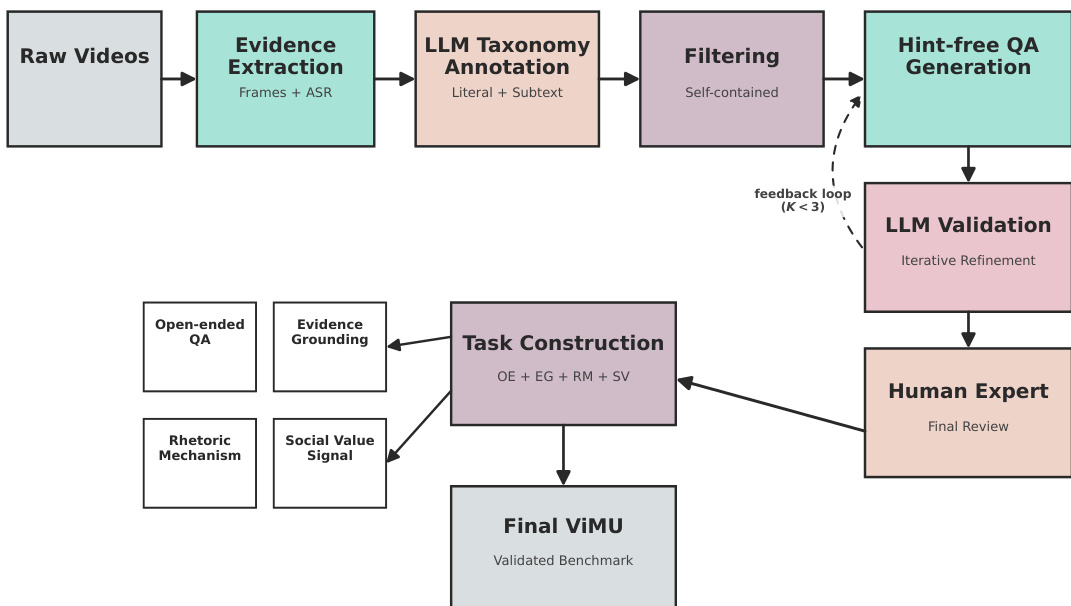
The process initiates with Raw Videos, which undergo Evidence Extraction to gather visual frames and Automatic Speech Recognition (ASR) transcripts. This extracted evidence is then processed by an LLM Taxonomy Annotation module responsible for categorizing content based on literal meaning and subtextual elements. Following annotation, a Filtering step ensures that the content is self-contained before proceeding to Hint-free QA Generation.
To ensure quality, the system employs an iterative refinement loop. The LLM Validation module reviews the generated questions, utilizing a feedback mechanism that allows for up to three iterations (K<3) to correct errors. The refined data then undergoes Human Expert review for final validation. Once validated, the data enters the Task Construction phase. This stage organizes the content into four distinct task categories: Open-ended QA, Evidence Grounding, Rhetoric Mechanism, and Social Value Signal.
For the structured subtext understanding tasks, specifically Rhetoric Mechanism and Social Value Signal identification, the authors evaluate models under two distinct prompt settings. The unguided setting provides only the task question, transcript, options, and output rules. In contrast, the guided setting supplements these inputs with taxonomy definitions for the five macro categories to assist the model. The taxonomy used during annotation includes specific categories such as Literal / Direct, where the video communicates its message without irony or figurative framing, and Opposition / Incongruity, which covers mechanisms like bait-and-switch or role reversal. Additionally, the Social Value Guidance options correspond to high-level social value signals that summarize finer-grained attitudes expressed in video memes. The final output of this pipeline is the Final ViMU Validated Benchmark.
Experiment
The evaluation assesses 16 multimodal large language models on the ViMU benchmark through zero-shot testing across tasks measuring open-ended interpretation, evidence grounding, and implicit social or rhetorical understanding. Findings reveal that strong general video interpretation capabilities do not guarantee precise comprehension of implicit stances or coded meanings, with performance varying significantly across model families rather than strictly distinguishing between open-weight and proprietary models. Furthermore, error analysis indicates that models primarily fail to retrieve complete supporting evidence rather than hallucinating cues, while exhibiting biases toward safer, literal categories over nuanced social signals.
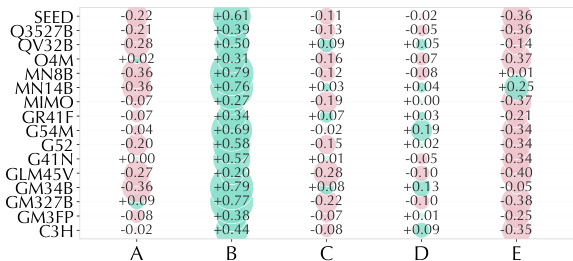
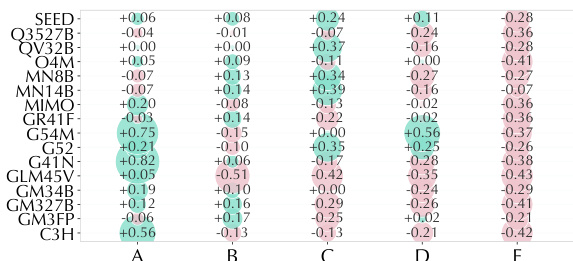
The the the table visualizes model-option affinity bias without guidance, indicating systematic tendencies where models over-predict or under-predict specific options relative to ground truth prevalence. Positive values represent over-prediction while negative values represent under-prediction, revealing that models consistently favor certain categories like option B while avoiding others like option E across various architectures. This pattern suggests a shared bias in how models interpret social value signals, often defaulting to emotional attitudes rather than nuanced ideological framing. Models exhibit a strong positive bias towards option B, indicating a tendency to over-select Emotional Attitude. There is a consistent negative bias for option E, showing models frequently under-predict Identity or Ideological Signaling. The bias patterns remain relatively stable across different model families, suggesting common limitations in handling complex social signals.
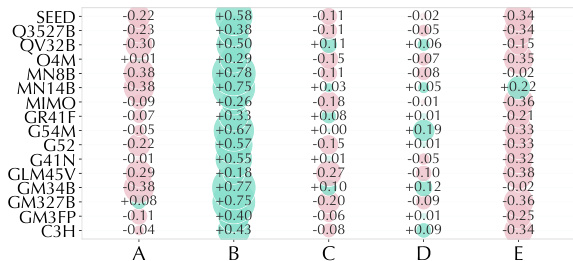
The the the table displays model-option affinity bias scores across five categories, highlighting systematic tendencies in model predictions. It reveals a consistent pattern where models strongly over-predict option B while simultaneously under-predicting option E. These results indicate that current models default to broad affective interpretations rather than capturing nuanced or implicit social signals. Option B shows a strong positive bias, indicating frequent over-prediction across nearly all models. Option E consistently exhibits negative values, reflecting a widespread tendency to under-predict this category. The data demonstrates clear option-level biases, suggesting models struggle with specific implicit or identity-based signals.
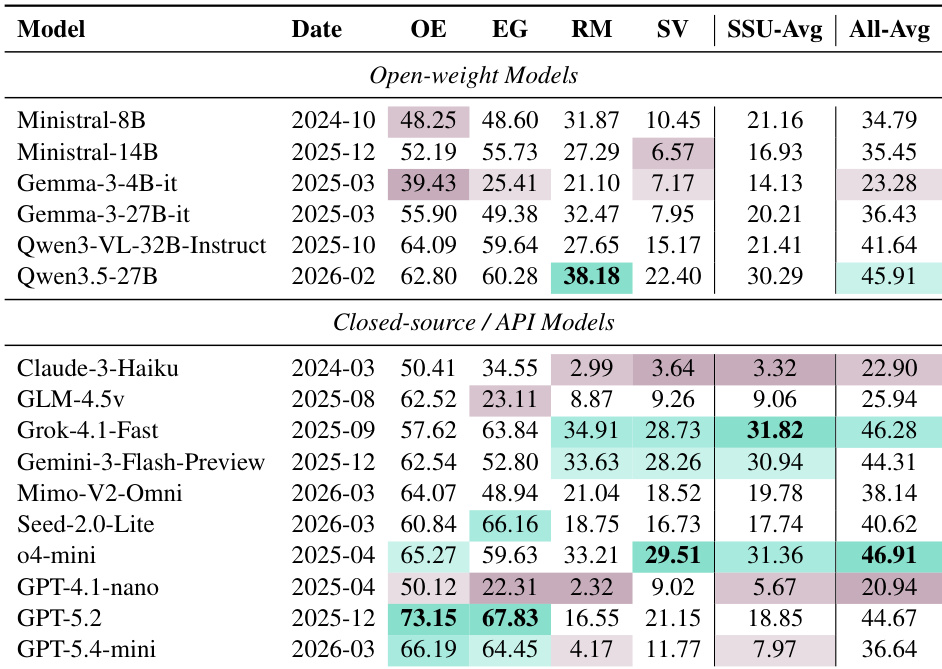
The authors evaluate 16 multimodal language models on a benchmark designed to test implicit video understanding. Results indicate a clear performance gap where models excel at general open-ended interpretation and evidence grounding but struggle significantly with identifying specific rhetoric mechanisms and social value signals. Top-performing models in open-ended interpretation show a sharp decline in accuracy when tasked with identifying rhetoric mechanisms or social value signals. Different model families display distinct strengths, with some specialized models outperforming generalist leaders on structured subtext understanding tasks. Open-weight models demonstrate competitive performance against proprietary models, with certain open-source variants achieving higher overall averages than specific closed-source counterparts.
The authors analyze the taxonomy geometry of model predictions to evaluate how well models preserve structural relationships between different categories in evidence grounding and rhetoric tasks. The results show that while models recover some dominant co-occurrence patterns, their predicted matrices are generally flatter and less contrasted than the ground truth, indicating a failure to preserve fine-grained relations. Furthermore, providing guidance introduces systematic local shifts in these relations but does not consistently improve the overall structural fidelity relative to the ground truth. Models capture limited taxonomy structure, with predicted matrices appearing flatter and less contrasted than ground truth. Guidance mechanisms induce local shifts in pairwise relations but fail to consistently restore global structural fidelity. Current models are substantially weaker at recovering structured multi-source evidence patterns compared to isolated perceptual cues.

The authors evaluate 16 multimodal large language models on the ViMU benchmark, which assesses open-ended interpretation, evidence grounding, rhetoric mechanism identification, and social value signal identification. The results highlight a significant performance gap where models excelling at general video interpretation often struggle with implicit rhetorical and social understanding tasks. Additionally, the analysis reveals that closed-source models are not uniformly superior to open-weight models across all evaluated metrics. Models excelling in open-ended interpretation often show a sharp performance drop in identifying rhetoric mechanisms and social value signals. The results demonstrate that frontier capabilities in general video understanding do not automatically translate to precise comprehension of implicit stances or socially coded meanings. Open-weight models such as Qwen3.5-27B can achieve higher average scores than certain closed-source models like GPT-4.1-nano and Claude-3-Haiku.
The evaluation assesses 16 multimodal language models on the ViMU benchmark, revealing that while models excel at general open-ended interpretation, they struggle significantly with identifying specific rhetoric mechanisms and social value signals. Analysis indicates systematic affinity biases where models over-predict emotional attitudes while under-predicting ideological signaling, alongside a failure to preserve fine-grained structural relationships even when guidance mechanisms are applied. Furthermore, open-weight models demonstrate competitive performance against proprietary counterparts, suggesting that frontier capabilities in general video understanding do not automatically translate to precise comprehension of implicit stances.