Command Palette
Search for a command to run...
CVEvolve: Autonome Algorithmenentwicklung für die Verarbeitung unstrukturierter wissenschaftlicher Daten
CVEvolve: Autonome Algorithmenentwicklung für die Verarbeitung unstrukturierter wissenschaftlicher Daten
Ming Du Xiangyu Yin Yanqi Luo Dishant Beniwal Songyuan Tang Hemant Sharma Mathew J. Cherukara
Zusammenfassung
Die Verarbeitung wissenschaftlicher Daten erfordert häufig aufgaben spezifische Algorithmen oder KI-Modelle, was eine Hürde für Fachwissenschaftler darstellt, die ihre Daten analysieren möchten, aber möglicherweise nicht über umfassende Kenntnisse in den Bereichen Datenverarbeitung oder Bildverarbeitung verfügen. Diese Hürde zeigt sich besonders deutlich, wenn die Daten verrauscht sind, einen großen dynamischen Bereich aufweisen, nur spärlich gelabelt sind oder nur grob definiert sind. Wir stellen CVEvolve vor, einen autonomen agentic Harness mit einer Zero-Code-Schnittstelle zur Entdeckung von Algorithmen zur Verarbeitung wissenschaftlicher Daten. CVEvolve kombiniert eine mehrstufige Suchstrategie mit Tools zur Codeausführung, Implementierung von Evaluierungen, Verwaltung des Historienspeichers, Holdout-Tests sowie optionaler Inspektion wissenschaftlicher Daten und visueller Ausgaben. Die Suche wechselt zwischen Entdeckungs- und Verbesserungsmaßnahmen und verwendet lineage-aware stochastic candidate sampling, um Exploration und Exploitation auszubalancieren. Wir demonstrieren CVEvolve an der Registrierung von Röntgenfluoreszenzmikroskopie-Bildern, der Detektion von Bragg-Peaks und der Segmentierung von Hochenergiediffraktometrie-Bildern. In allen diesen Aufgaben findet CVEvolve Algorithmen, die über Basislinienmethoden hinausgehen, wobei die Verfolgung von Holdout-Tests hilft, Kandidaten zu identifizieren, die besser generalisieren als später überoptimierte Alternativen.详细术语翻译说明:task-specific algorithms → aufgaben spezifische Algorithmen 这里使用"aufgaben spezifisch"作为形容词来描述算法,符合德语习惯。AI models → KI-Modelle 使用"KI"(Künstliche Intelligenz)作为缩写,这是德语中对人工智能的标准说法。zero-code interface → Zero-Code-Schnittstelle 这里保留"Zero-Code"的英文形式,并用连字符连接德语中的"Schnittstelle",确保清晰易懂。autonomous agentic harness → autonomer agentic Harness "Harness"保留英文,因为其在该领域有特定含义,而"agentic"也保留英文以强调其作为技术术语的重要性。multi-round search strategy → mehrstufige Suchstrategie 使用"mehrstufig"表示多轮或多阶段的过程,符合德语表达习惯。lineage-aware stochastic candidate sampling → lineage-aware stochastic candidate sampling 该短语较长且属于技术细节,因此保留英文并标注原文。holdout test tracking → Verfolgung von Holdout-Tests 将"holdout test"保留英文,并通过"Verfolgung"表达跟踪的概念,符合科技写作风格。over-optimized alternatives → überoptimierte Alternativen 使用复合词"überoptimiert",符合德语合成词的习惯。其他优化:句子结构进行了调整,使其更符合德语的逻辑顺序。避免过度直译,例如将"creating a barrier"转化为"was eine Hürde darstellt",使表达更自然。保留了所有专有名词和技术术语的原始形式,同时确保它们在德语语境中易于理解。
One-sentence Summary
CVEvolve, an autonomous agentic harness with a zero-code interface, discovers scientific data-processing algorithms by combining a multi-round search strategy with lineage-aware stochastic candidate sampling to balance exploration and exploitation, demonstrating improvements over baseline methods on x-ray fluorescence microscopy image registration, Bragg peak detection, and high-energy diffraction microscopy image segmentation while utilizing holdout test tracking to identify candidates that generalize better than later over-optimized alternatives.
Key Contributions
- This work introduces CVEvolve, an autonomous agentic harness featuring a zero-code interface for scientific data-processing algorithm discovery. The system combines a multi-round search strategy with tools for code execution, evaluation implementation, and history management.
- The framework employs a dynamic workflow that grants agents freedom to configure development environments and translate user-provided metric descriptions into executable evaluation procedures. Lineage-aware stochastic candidate sampling balances exploration and exploitation during the search process.
- Experiments demonstrate the framework on representative scientific imaging problems such as X-ray fluorescence microscopy image registration and Bragg peak detection. Results show the agent synthesizes algorithms that rival or exceed manual baselines while using holdout test tracking to ensure robust generalization.
Introduction
Domain scientists frequently encounter bottlenecks when processing complex unstructured data such as microscopy images due to a lack of specialized programming expertise. Prior automated research systems typically rely on structured optimization problems with predefined evaluators, which limits their ability to handle the noisy or variable nature of real-world scientific datasets. To address this challenge, the authors introduce CVEvolve, an autonomous agentic harness designed for zero-code algorithm discovery. The system employs a multi-round search strategy alongside tools for code execution, visual inspection, and agent-managed holdout testing to prevent over-optimization. CVEvolve translates natural language instructions into robust processing pipelines, allowing scientists to develop task-specific algorithms without writing custom evaluation scripts.
Method
CVEvolve is designed as an autonomous search controller wrapped around a large language model (LLM) agent. The system leverages code, data, evaluation, history, and visualization tools to propose, run, and evaluate candidate algorithms. The overall workflow is structured into three primary stages: workspace preparation, baseline evaluation, and algorithm development. Refer to the framework diagram for a comprehensive view of these stages and their interactions.
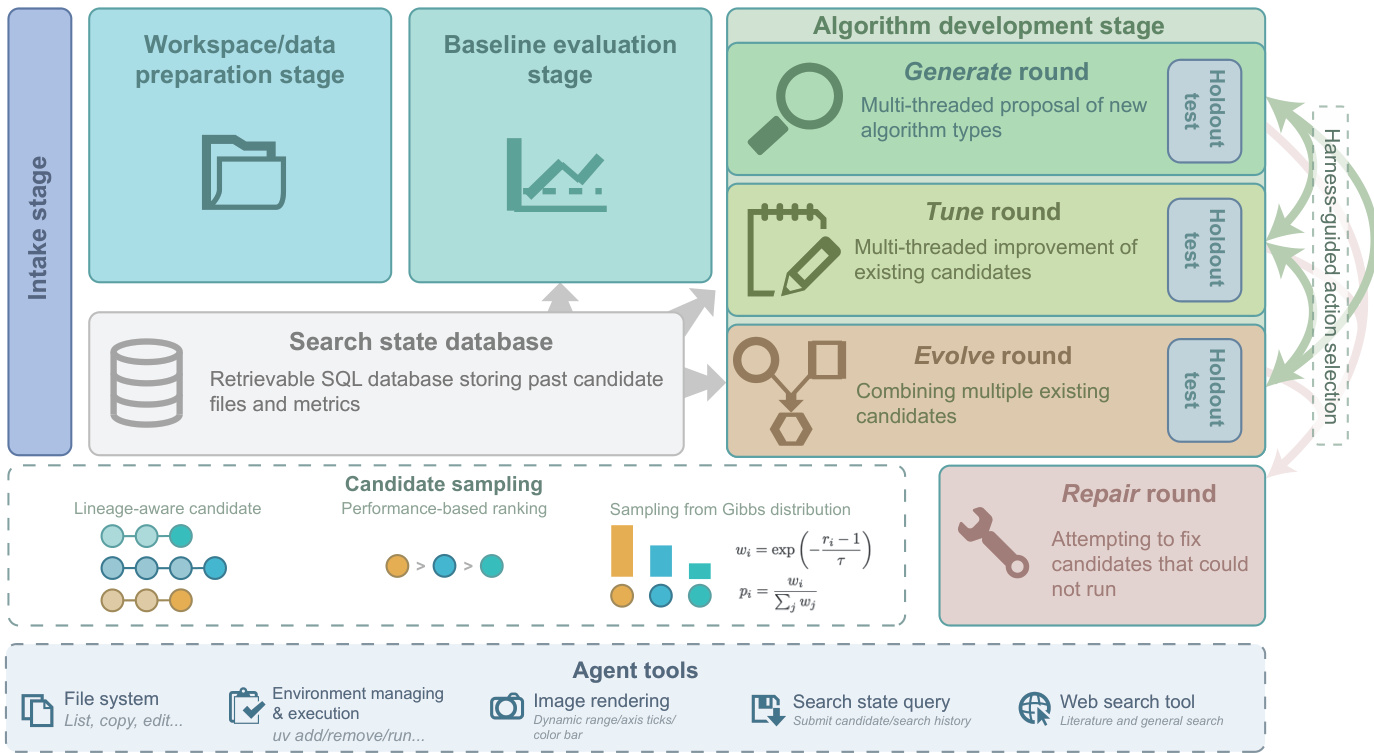
During the intake stage, the agent prepares the workspace, builds the environment, and implements the performance evaluation. The baseline evaluation stage follows, where the agent assesses user-provided or suggested baseline algorithms to establish a performance benchmark. The core of the system lies in the algorithm development stage, which operates through a series of rounds. In each round, a harness selects one of three actions with distinct strategic focuses: generate, tune, or evolve. The generate action proposes new algorithm types, the tune action improves existing candidates, and the evolve action combines multiple existing candidates. For rounds involving parent candidates, the system employs lineage-aware sampling inspired by MAP-Elites. A holdout test may optionally run at the end of each round on a separate dataset using a dedicated agent to handle unstructured data and evaluation schemes.
To manage the search state, CVEvolve utilizes a persistent relational database. This SQL-backed store retains the candidate pool, round history, and metric definitions, allowing the agent to query past performance and lineage information without relying on in-context memory or vector stores. This design ensures reproducibility and deterministic ranking. Candidate sampling for tune and evolve rounds uses a stochastic approach based on a Gibbs distribution. Let ri∈{1,2,…} denote the rank of candidate i in the eligible pool, where ri=1 is the best. CVEvolve assigns each candidate an unnormalized selection weight:
wi=exp(−τri−1),where τ>0 is a temperature parameter controlling exploration. The actual sampling probability is the normalized Gibbs distribution:
pi=∑jwjwi.As τ→0+, the distribution becomes greedy, concentrating on top-ranked candidates. Larger τ values spread probability mass more broadly. For evolve rounds, a same-lineage penalty is applied to encourage combining different lineages:
w~i=wiλmi,where λ∈[0,1] is the penalty factor and mi is the count of already selected parents sharing the candidate's lineage.
The underlying agent application is implemented using a LangGraph-based framework. The runtime employs a compact node graph that separates message ingestion, model reasoning, tool execution, and optional image follow-up handling. As shown in the figure below:
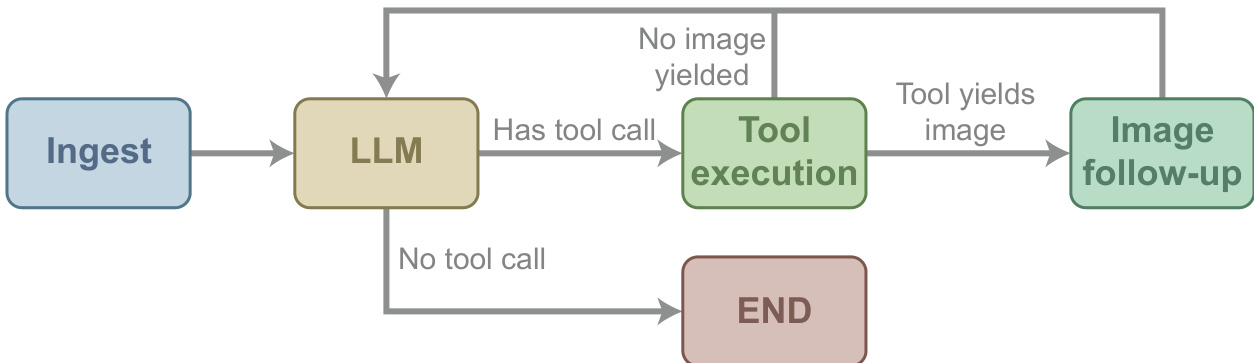
The workflow begins at the Ingest node, which prepares the system and task prompts. The state is passed to the LLM node for reasoning. If the response contains a tool call, it routes to the Tool execution node. If the tool returns a structured response containing an image path, the flow moves to the Image follow-up node. Here, the image is loaded, encoded, and appended as a multimodal observation before returning to the LLM for the next reasoning step. This mechanism allows the agent to inspect visual outputs, such as plots or scientific images, which is critical for tasks involving image processing pipelines like the one illustrated in the flowchart below.
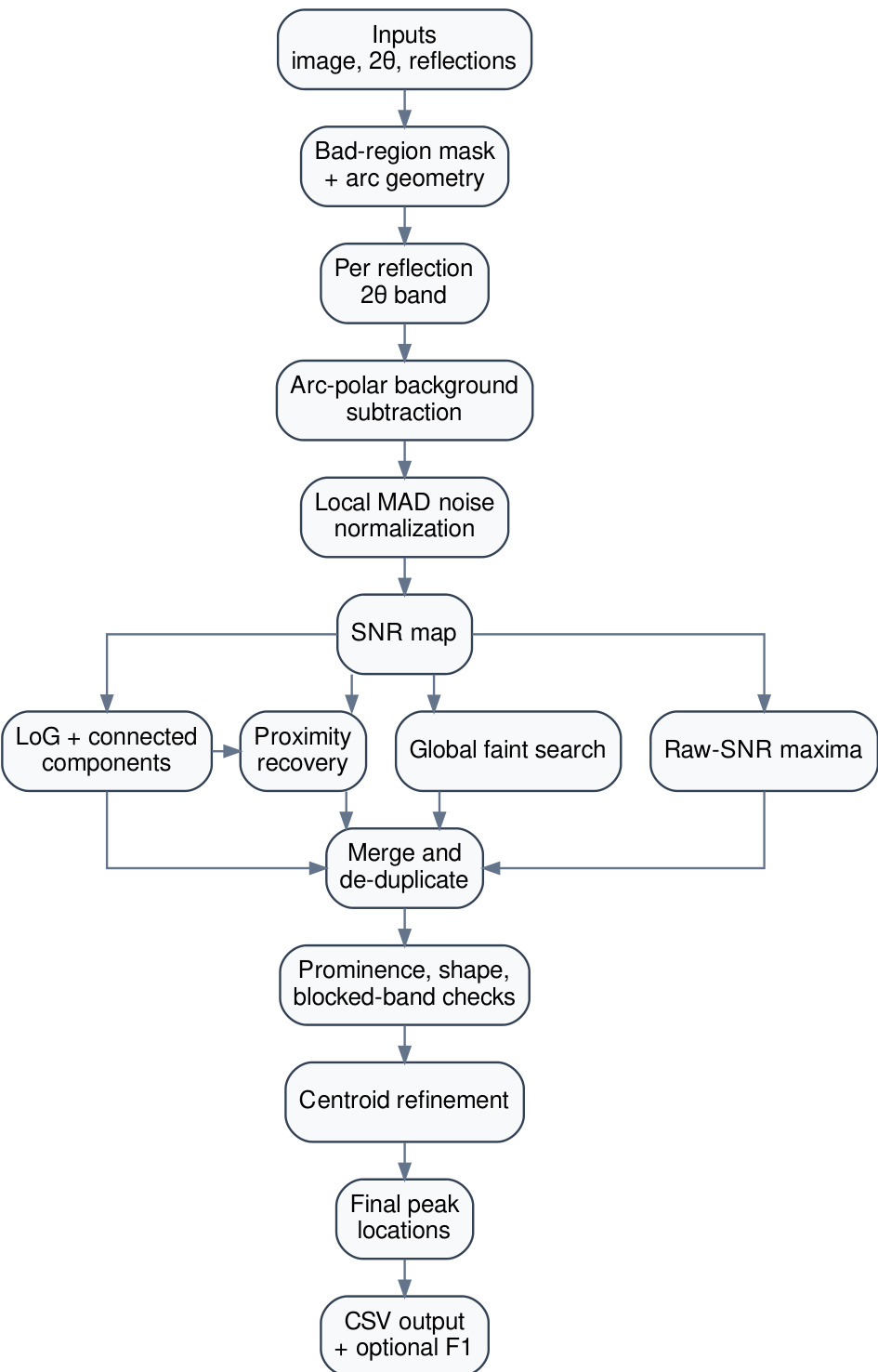
CVEvolve exposes several tool families to support these operations. File system tools allow listing, reading, writing, and editing files within the workspace. Environment management tools enable the installation of dependencies and execution of Python scripts via commands like uv add and uv run. The image viewing tool renders images into agent-viewable PNGs, supporting dynamic range selection and logarithmic scaling to inspect weak structures or high-dynamic-range data. Search state tools permit the agent to log results, inspect history, and submit new candidates. Additionally, web search tools provide access to literature repositories to inform algorithm development.
The system also supports an optional holdout test to evaluate generalization without exposing holdout data during design. When enabled, the main agent receives a prompt describing the holdout folder structure but cannot inspect the data. Upon candidate submission, a separate holdout test agent is spawned in a temporary workspace to run the evaluation and record metrics, ensuring data isolation. Failed candidates are routed to a repair round where the system attempts to fix issues preventing execution.
Experiment
CVEvolve was evaluated across three computer vision tasks involving image registration, peak detection, and segmentation, where it successfully generated robust analytical algorithms that outperformed baseline algorithms and alternative evolution methods. Holdout testing proved critical in preventing overfitting during development, particularly when training data was scarce, while a separate optimization experiment demonstrated the value of stochastic sampling in avoiding local optima. These findings collectively validate the system's ability to produce interpretable, high-performance workflows for complex scientific imaging problems without requiring dedicated GPU resources.
The the the table presents the holdout test errors for the XRF image registration task, comparing baseline algorithms against candidates generated by evolutionary methods. The results demonstrate that the algorithm discovered by CVEvolve achieved the lowest average Euclidean distance, significantly outperforming the brute-force baseline and the candidate found by OpenEvolve. Phase correlation exhibited the highest error, indicating it is less effective for this specific registration problem than the other methods. CVEvolve identified the most accurate algorithm, achieving the lowest registration error among all tested methods. Evolved candidates significantly outperformed the brute-force baseline, which in turn performed better than phase correlation. Phase correlation resulted in the highest error, suggesting standard strategies struggle with the image characteristics of this task.

This experiment evaluates XRF image registration by comparing baseline algorithms against candidates generated through evolutionary methods. The results demonstrate that the algorithm discovered by CVEvolve achieved the lowest registration error, significantly outperforming the brute-force baseline and the candidate found by OpenEvolve. In contrast, phase correlation exhibited the highest error, indicating that standard strategies struggle with the image characteristics of this task compared to the evolved solutions.