Command Palette
Search for a command to run...
Technischer Bericht zu Phi-4-reasoning-vision-15B
Technischer Bericht zu Phi-4-reasoning-vision-15B
Jyoti Aneja Michael Harrison Neel Joshi Tyler LaBonte John Langford Eduardo Salinas
Zusammenfassung
Wir stellen Phi-4-reasoning-vision-15B vor, ein kompaktes, multimodales Reasoning-Modell mit offenen Gewichten, und teilen die Motivationen, Designentscheidungen, Experimente sowie die gewonnenen Erkenntnisse, die dessen Entwicklung geprägt haben. Unser Ziel ist es, der Forschungsgemeinschaft praktische Einsichten zum Aufbau kleinerer, effizienter multimodaler Reasoning-Modelle zu vermitteln und diese Erkenntnisse in Form eines offenen Modells bereitzustellen, das bei gängigen visuellen und sprachbasierten Aufgaben solide Leistungen erbringt und sich insbesondere im wissenschaftlichen und mathematischen Reasoning sowie beim Verständnis von Benutzeroberflächen auszeichnet.Zu unseren Beiträgen gehört der Nachweis, dass sorgfältige Architekturwahl und rigorose Datenkuratierung es kleineren, offenen multimodalen Modellen ermöglichen, mit deutlich geringerem Trainings- und Inferenz-Rechenbedarf sowie weniger Tokens wettbewerbsfähige Leistungen zu erzielen. Die substantiellsten Verbesserungen ergeben sich aus systematischer Filterung, Fehlerkorrektur und synthetischer Augmentierung – was unterstreicht, dass die Datenqualität nach wie vor der primäre Hebel für die Modellleistung ist. Systematische Ablationsstudien zeigen, dass Encoder mit hoher Auflösung und dynamischer Auflösung konsistente Verbesserungen bewirken, da eine präzise Wahrnehmung eine Voraussetzung für qualitativ hochwertiges Reasoning darstellt. Schließlich ermöglicht eine hybride Mischung aus Reasoning- und Nicht-Reasoning-Daten, ergänzt durch explizite Mode-Tokens, dass ein einzelnes Modell für einfachere Aufgaben schnelle direkte Antworten liefert und für komplexe Probleme Chain-of-Thought-Reasoning einsetzt.
One-sentence Summary
The authors present Phi-4-reasoning-vision-15B, a compact open-weight multimodal reasoning model that achieves competitive performance with significantly less training and inference-time compute and tokens through rigorous data curation and high-resolution, dynamic-resolution encoders, while utilizing a hybrid mix of reasoning and non-reasoning data with explicit mode tokens to deliver fast direct answers and chain-of-thought reasoning for scientific and mathematical reasoning as well as understanding user interfaces.
Key Contributions
- The work presents Phi-4-reasoning-vision-15B, a compact open-weight multimodal reasoning model designed to excel at scientific and mathematical reasoning while remaining efficient on modest hardware.
- Rigorous data curation and systematic filtering enable smaller models to achieve competitive performance with significantly less training compute, utilizing only 200 billion tokens compared to over a trillion for similar models.
- A hybrid mix of reasoning and non-reasoning data with explicit mode tokens allows the single model to deliver fast direct answers for simpler tasks and chain-of-thought reasoning for complex problems.
Introduction
Current vision-language models often trend toward increasing parameter counts and token consumption, which drives up training costs and inference latency for downstream deployment. This scaling approach creates barriers for resource-constrained environments where efficiency is critical. The authors present Phi-4-reasoning-vision-15B, a compact open-weight multimodal model designed to balance reasoning power with computational efficiency. They demonstrate that rigorous data curation and careful architecture choices enable smaller models to match the performance of larger counterparts while using significantly fewer tokens. Furthermore, the model employs a hybrid training mix with explicit mode tokens to dynamically switch between fast direct answers and chain-of-thought reasoning depending on task complexity.
Dataset

-
Dataset Composition and Sources
- The final data mix consists primarily of filtered open-source vision-language datasets, supplemented by high-quality domain-specific data from Microsoft teams and targeted acquisitions.
- Safety training signals include public datasets such as Hateful Memes, VLGuard, Think-in-Safety, and WildGuard, alongside internally generated examples.
- Domain-specific additions include math datasets acquired during Phi-4 language model training and LaTeX-OCR data derived from arXiv documents.
-
Data Filtering and Quality Control
- The authors manually classified data samples into categories like excellent quality, good questions with wrong answers, or low-quality images to determine inclusion.
- Records with incorrect answers or poor captions were regenerated using GPT-4o and o4-mini, while datasets with fundamental image errors were excluded.
- Significant effort was dedicated to fixing formatting and logical errors programmatically across the open-source datasets.
-
Training Usage and Processing Strategies
- Diversification techniques include generating detailed image descriptions for math and science images to create multiple records per image.
- Multi-image records were constructed in scrambled and caption-matching formats to enhance attention mechanisms in complex scenarios.
- Sequential screenshot pairs were utilized to generate change detection data for computer-use and robotics applications.
- Training mixtures were optimized by increasing math data by three times while holding computer-use data constant to improve benchmark performance.
- Human prompts replaced over-engineered prompts to teach the model robustness against perfectly structured user inputs.
-
Technical Specifications
- Spatial coordinates are normalized to the range of 0.0 to 1.0 relative to image dimensions for consistent representation across resolutions.
- Safety evaluation utilized automated red teaming on Azure to assess risks related to disallowed content, copyright, and jailbreak susceptibility.
Method
The authors leverage a mid-fusion architecture to balance the expressivity of joint representations with the efficiency of pretrained components. This design choice avoids the high computational costs of early-fusion models while maintaining strong cross-modal reasoning capabilities.
Refer to the framework diagram below for the overall structure of the Phi-4-reasoning-vision-15B model.
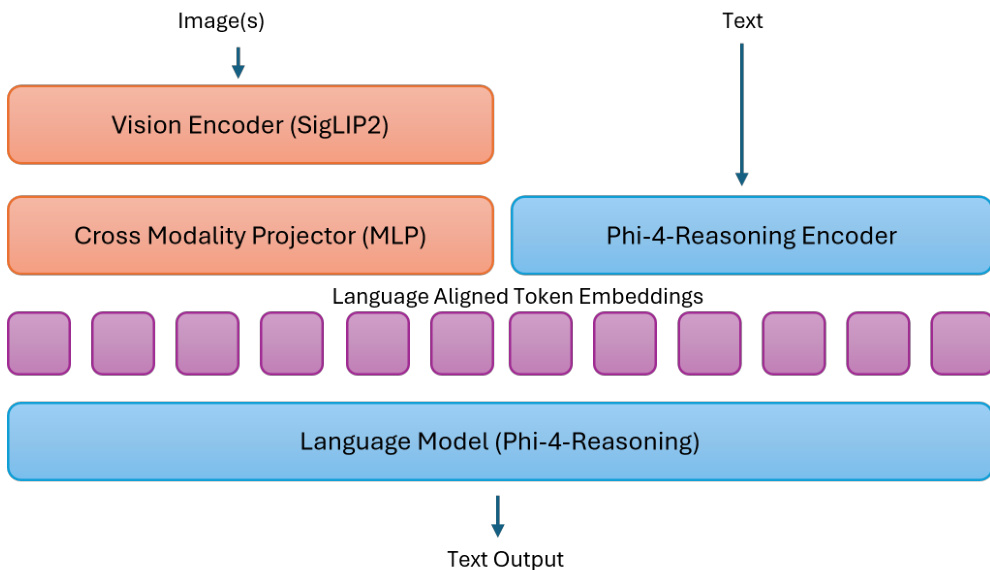
The system processes visual inputs through a SigLIP-2 vision encoder, which converts images into a compact set of visual tokens. These tokens are then projected into the language embedding space using a Cross Modality Projector implemented as a Multi-Layer Perceptron (MLP). The resulting language-aligned visual tokens are interleaved with text tokens and fed into the Phi-4-Reasoning language model backbone. The authors selected dynamic resolution vision encoders with a high number of visual tokens to maximize grounding performance on high-resolution datasets, particularly for tasks involving information-dense interfaces like desktop screens.
The training process is executed in three distinct stages to ensure robust alignment and capability. The first stage focuses on MLP pretraining, where only the cross-modality projector is trained while the vision encoder and language model remain frozen. This establishes a shared representation space between the visual features and text embeddings. The second stage involves instruction tuning on the entire model using a large dataset of single-image visual instruction data. This stage covers diverse tasks including visual question answering, mathematical reasoning, and computer use. The final stage extends the model's capabilities through training on long-context, multi-image, and responsible AI (RAI) data.
To balance inference efficiency with reasoning depth, the model employs a mixed reasoning and non-reasoning training approach. During supervised fine-tuning, reasoning samples include chain-of-thought traces marked with specific tokens, while non-reasoning samples are tagged to signal direct responses. This allows the model to dynamically choose between direct inference for perception-focused tasks and structured multi-step reasoning for complex domains like math and science.
As illustrated in the example below, the model is capable of interpreting visual diagrams to solve physics problems involving spring-mass systems.
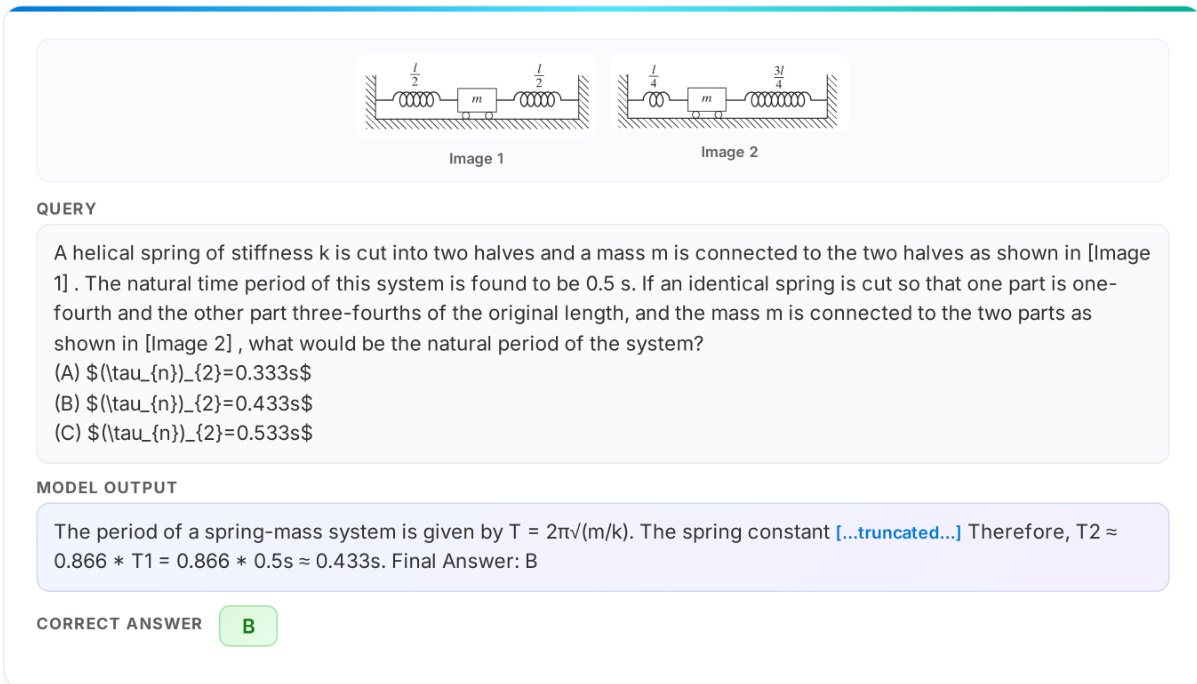
The model analyzes the provided diagrams to determine the natural period of the system, applying the formula T=2πm/k to derive the correct answer. This functionality validates the integration of visual encoding with the reasoning backbone.
Experiment
Experiments varying mathematics and computer-use data proportions demonstrated that a single model can achieve uniformly superior performance across diverse reasoning domains without negative trade-offs. Comprehensive evaluations using standardized frameworks on benchmarks like MathVerse and ScreenSpot confirm that the model effectively balances thinking and non-thinking modes while excelling at visual grounding and GUI interaction. Overall results indicate a desirable trade-off between accuracy and inference cost compared to open-weight alternatives, though limitations remain regarding extreme visual detail and optimal reasoning mode switching.
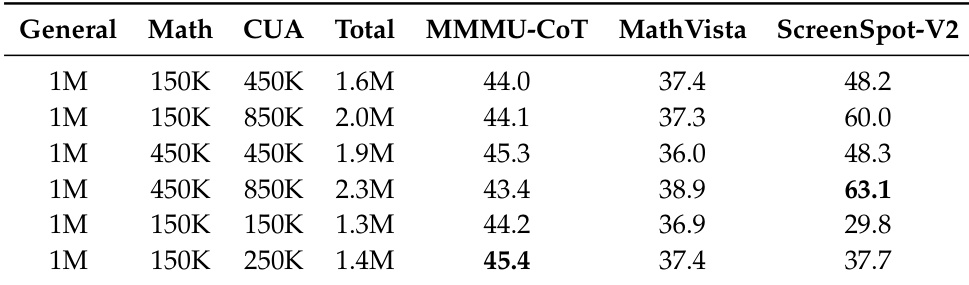
The authors analyze the effects of varying mathematics and computer-use data proportions on model performance. They find that increasing computer-use data significantly boosts GUI grounding capabilities without harming mathematical reasoning. The results suggest that a single model can achieve strong uniform performance across different reasoning tasks with the right data mix. Increasing computer-use data significantly improves performance on the ScreenSpot-V2 benchmark. Multimodal mathematics performance remains robust when additional computer-use data is included. A single model configuration can achieve strong performance across diverse reasoning domains.
The authors evaluate Phi-4-reasoning-vision-15B against various open-weight models on vision-language benchmarks. Results indicate strong performance across math, science, and computer-use tasks, showing competitive results against larger models. The model demonstrates a balanced capability between reasoning and non-reasoning modes. The model demonstrates strong performance on math and science reasoning benchmarks. It shows competitive results against larger models in computer-use tasks. Default mixed-reasoning behavior generally yields better accuracy than forced modes.
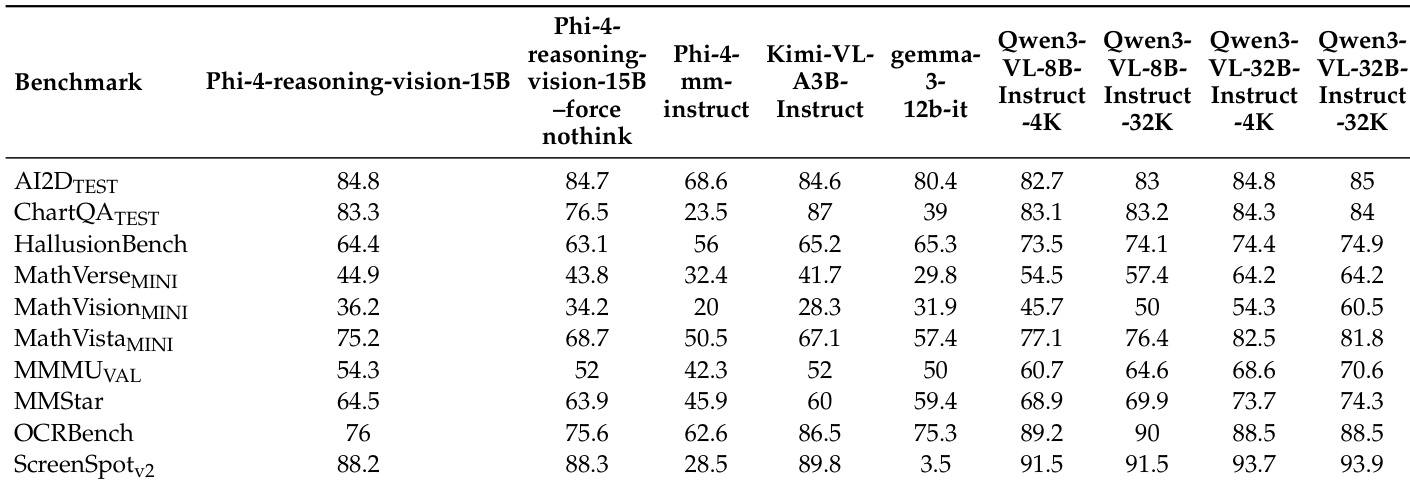
The the the table compares Phi-4-reasoning-vision-15B against various open-weight models across diverse benchmarks including math, science, and computer use. Results indicate that the model achieves competitive performance in computer-use tasks while maintaining strong capabilities in mathematical reasoning relative to its size. The data suggests that forcing a specific reasoning mode yields mixed results, improving math tasks but potentially hindering general visual understanding. Phi-4-reasoning-vision-15B outperforms larger thinking models on computer-use benchmarks while remaining competitive on math tasks Enforcing a thinking mode improves performance on specific reasoning benchmarks but lowers scores on general visual understanding tasks The model maintains strong performance across diverse categories including OCR, chart analysis, and visual grounding
The authors evaluate various resolution and token strategies for multimodal reasoning tasks. Dynamic resolution methods generally achieve superior performance on math and screen spotting tasks compared to multi-crop baselines. Increasing token limits further improves specialized grounding capabilities. Dynamic resolution at 2048 tokens achieves the highest scores on MathVista and ScreenSpot Multi-crop with S^2 demonstrates strong performance on ScreenSpot-Pro and V*Bench benchmarks Expanding token limits to 3600 significantly boosts performance on ScreenSpot-Pro
The authors evaluate the model through experiments on data proportions, competitive benchmarking, and resolution strategies. Results indicate that increasing computer-use data enhances GUI grounding without compromising mathematical reasoning, while default mixed-reasoning modes yield better accuracy than forced configurations. Additionally, dynamic resolution methods and expanded token limits significantly improve performance on specialized grounding and math tasks compared to baseline strategies.