Command Palette
Search for a command to run...
Überdenken der Trainingsziele, Architekturen und Datenqualität für universelle Spracher enhancement
Überdenken der Trainingsziele, Architekturen und Datenqualität für universelle Spracher enhancement
Szu-Wei Fu Rong Chao Xuesong Yang Sung-Feng Huang Ryandhimas E. Zezario Rauf Nasretdinov Ante Jukić Yu Tsao Yu-Chiang Frank Wang
Zusammenfassung
Universaler Sprachverbesserungsalgorithmus (Universal Speech Enhancement, USE) zielt darauf ab, die Sprachqualität unter verschiedenen Degradationsbedingungen wiederherzustellen, während die Signaltreue erhalten bleibt. Trotz jüngster Fortschritte bleiben wesentliche Herausforderungen in den Bereichen der Auswahl der Trainingsziele, des Trade-offs zwischen Verzerrung und Wahrnehmung sowie der Datenauswahl und -kuratierung weiterhin ungelöst. In dieser Arbeit adressieren wir systematisch diese drei vernachlässigten Probleme.Zunächst revidieren wir die konventionelle Praxis, reflektierte Frühreflexionen als Ziel für die Reverberationsunterdrückung zu verwenden. Wir zeigen, dass dieser Ansatz die wahrgenommene Qualität sowie die Leistung nachgelagerter Automatic-Speech-Recognition-(ASR)-Modelle beeinträchtigen kann. Stattdessen demonstrieren wir, dass zeitversetzte, aokustische Saufrausch-Referenzdaten (anechoic clean speech) ein überlegenes Lernziel darstellen.Zweitens schlagen wir, angeleitet durch die Theorie des Verzerrung-Wahrnehmung-Trade-offs, einen einfachen zweistufigen Framework vor, der bei einem gegebenen Niveau an wahrgenommener Qualität eine minimale Verzerrung erreicht.Drittens analysieren wir den Trade-off zwischen dem Umfang und der Qualität der Trainingsdaten für USE. Dabei stellen wir fest, dass das Training auf großen, nicht kuratierten Korpora eine Leistungsgrenze darstellt, da Modelle Schwierigkeiten haben, subtile Artefakte zu entfernen.Unsere Methode erzielt state-of-the-art Ergebnisse auf dem URGENT-2025-Testset (Non-Blind) und zeigt eine starke sprachenunabhängige Generalisierungsfähigkeit, wodurch sie sich effektiv zur Verbesserung von TTS-Trainingsdaten eignet. Die Model-Gewichte können unter folgender Adresse heruntergeladen werden: https://huggingface.co/nvidia/RE-USE.
One-sentence Summary
NVIDIA, Academia Sinica, and National Taiwan University introduce RE-USE, a universal speech enhancement method that uses time-shifted anechoic clean speech as the dereverberation target, a two-stage framework for minimal distortion at a given perceptual quality, and curated data to overcome the performance ceiling of large uncurated corpora, achieving state-of-the-art on the URGENT 2025 non-blind test set and language-agnostic generalization effective for improving TTS training data.
Key Contributions
- A systematic comparison of dereverberation learning targets reveals that time-shifted anechoic clean speech consistently outperforms the widely used early-reflected speech, improving both perceptual quality and downstream ASR performance across diverse degradation conditions.
- A two-stage framework grounded in distortion-perception tradeoff theory is introduced, which first applies a regression model and then uses a residual generative refinement to correct over-smoothed regions without hallucination, achieving state-of-the-art results on the URGENT 2025 non-blind test set.
- An analysis of training data scale versus quality demonstrates that large uncurated corpora impose a hard performance ceiling; rigorous curation and fine-tuning on the cleanest samples enable the model to remove subtle artifacts and yield better generalization to unseen real-world conditions.
Introduction
Universal speech enhancement (USE) targets restoring speech under diverse degradations—noise, reverberation, clipping, codec artifacts, and more—while preserving speaker identity and intelligibility, which is essential for applications like robust ASR and cleaning TTS training data. Prior work struggles with three under‑examined limitations: using early‑reflected speech as the dereverberation target, which can hurt perceptual quality; a persistent distortion‑perception trade‑off where purely regression‑based models oversmooth and generative models risk hallucinations; and a neglect of training data quality, where large uncurated corpora impose a performance ceiling and prevent removal of subtle artifacts. The authors tackle these bottlenecks by demonstrating that a time‑shifted anechoic clean speech target yields consistent gains over the conventional early‑reflection target, by proposing a theoretically‑grounded two‑stage framework that combines a regression model with a residual generative refiner to achieve minimal distortion at a given perceptual level, and by showing that rigorous data filtering and fine‑tuning on curated clean subsets are necessary to break the performance ceiling. Their method achieves state‑of‑the‑art results on the URGENT 2025 non‑blind test set and generalizes across languages, making it effective for improving downstream speech‑generation tasks.
Dataset
The authors use the URGENT 2025 Challenge Track 1 dataset, which supplies approximately 2,500 hours of multi‑condition speech, noise samples, and room impulse responses.
-
Composition and sources
- Speech comes from CommonVoice, DNS5, MLS, LibriTTS, VCTK, WSJ, and EARS, spanning five languages (English, German, French, Spanish, Chinese).
- Original recordings exist at sampling rates from 8 kHz to 48 kHz.
- Noise and RIR material is also provided by the challenge.
-
Key details for each subset
- CommonVoice is the largest subset (1 300 h) but shows the lowest quality owing to its crowdsourced nature.
- WSJ, EARS, and VCTK are consistently the three cleanest corpora.
- The challenge organisers already applied voice activity detection and DNSMOS‑based filtering to remove non‑speech and extremely noisy segments, yet many samples with audible background noise remain.
- To further improve training data quality, the authors compute VQScore for every utterance. Samples that fall below a VQScore threshold are discarded; manual inspection confirms that low‑score items often carry stationary background noise or non‑speech artifacts.
- The EARS subset is kept as the cleanest source overall, despite some expressive recordings (e.g., whispering) receiving low VQScore ratings, and is later used for a dedicated fine‑tuning stage.
-
How the data is used in the model
- The quality‑filtered speech is combined with the provided noise and RIRs to simulate seven distortion types: additive noise, reverberation, clipping, bandwidth limitation, codec artifacts, packet loss, and wind noise.
- The training mixture follows the challenge simulation recipe for multi‑condition data.
- A separate validation set is created from the official validation splits of the corpora using the same simulation procedure.
- The non‑blind challenge test set (1 000 utterances with noise and RIRs from unseen sources) serves for final evaluation.
- After the main multi‑condition training, the model is fine‑tuned exclusively on the high‑quality EARS portion.
-
Cropping, metadata, and other processing
- No additional cropping beyond the organisers’ VAD pre‑processing is mentioned.
- The main quality‑control step is the VQScore‑based filtering, which runs on the full 2 500 h in under eight hours on a single NVIDIA A100 GPU.
- Metadata such as VQScore distributions are analysed to confirm the quality hierarchy among sources, but no further metadata construction is described.
Method
The authors proposea novel approach to universal speech enhancement that addresses the fundamental trade-off between signal fidelity and perceptual quality. First, they identify limitations in conventional dereverberation targets. Instead of using early-reflected speech or unshifted anechoic clean speech, they propose using time-shifted anechoic clean speech s[n−n0] as the learning target. This choice effectively bypasses the alignment issue caused by the implicit estimation of the direct-path time shift n0, leading to superior performance in both fidelity and quality metrics.
To resolve the fidelity-quality dilemma, the authors leverage the distortion-perception tradeoff theory and introduce a streamlined two-stage framework. As shown in the figure below:
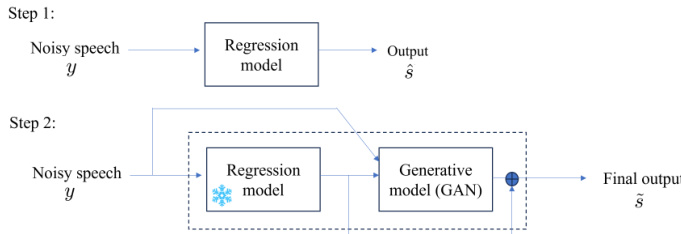
In the first step, a regression model is trained to convergence to estimate the posterior mean, thereby maximizing fidelity. Once trained, its weights are frozen. In the second step, the frozen regression model and the noisy input serve as conditional inputs to a generative model, specifically a Generative Adversarial Network. A crucial design element is the residual connection between the regression model output and the final output. This forces the generative model to focus primarily on correcting the over-smoothed regions where characteristics diverge from real data, effectively restoring perceptual details while preserving the linguistic content and speaker identity established in the first stage.
Regarding the model architecture, the authors employ a sampling frequency-independent Short-Time Fourier Transform to dynamically adjust the FFT window and hop size, ensuring consistent feature frame lengths across different sampling rates. For the regression model, they adopt USEMamba with 30 layers, which alternates between sequence modeling modules applied to frequency and time features. For the generative stage, a 6-layer USEMamba serves as the generator. To account for distinct feature patterns across frequency bands, they propose an adaptive multi-band discriminator. This discriminator uses a 5-layer 2-D convolutional network for local feature extraction within specific sub-bands corresponding to the input sampling rate, followed by concatenation and further convolutional layers to produce the final output. All components are trained using the AdamW optimizer.
Experiment
The evaluation uses a comprehensive suite of reference-based and non-intrusive metrics, subjective listening tests, and downstream ASR and TTS assessments. Filtering training data with a VQScore threshold of 0.65, adopting time-shifted anechoic clean speech as the dereverberation target, and applying a GAN correction to the regression output consistently improve perceptual quality and fidelity while avoiding the hallucinations often seen in purely generative models, significantly outperforming early-reflected targets and other open-source systems. Subjective ratings align with these objective gains, and the model remains language-agnostic, with fine-tuning on the cleanest data further boosting performance on unseen languages. Moreover, cleaning multilingual TTS training data with the proposed method substantially raises synthesis accuracy and speaker similarity, demonstrating its effectiveness for unlocking noisy, large-scale speech resources.
The authors compare the performance of their proposed speech enhancement model using time-shifted anechoic clean speech as the learning target against a baseline using early-reflected speech, both combined with GAN correction. Results indicate that the shifted anechoic approach consistently outperforms the early-reflected baseline across various perceptual, intelligibility, and similarity metrics. This demonstrates that using anechoic targets avoids the degradation in output quality associated with early-reflected targets. The shifted anechoic target with GAN correction yields superior perceptual quality and intelligibility scores compared to the early-reflected baseline. Using shifted anechoic targets improves speech representation and phoneme sequence similarity over the early-reflected approach. The proposed method maintains or slightly improves speaker similarity while enhancing other quality metrics.

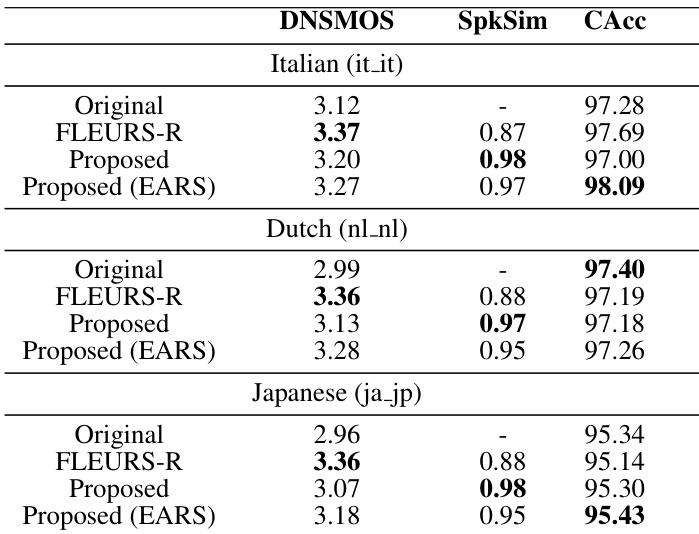
The authors compare their proposed speech enhancement model against other open-source models on different sampling rates to evaluate relative strengths. Results show that the proposed method consistently outperforms the baselines across non-intrusive, intrusive, and task-dependent metrics. While purely generative models improve perceptual quality, they suffer from hallucination, whereas the proposed approach maintains high fidelity and downstream task performance. The proposed method achieves the highest scores across non-intrusive quality metrics compared to both noisy inputs and other open-source models. Unlike the generative baseline which shows a significant drop in character accuracy indicating hallucination, the proposed model improves ASR performance. The proposed approach consistently outperforms the regression-based baseline across all evaluated metrics at 48 kHz, demonstrating superior overall enhancement quality.
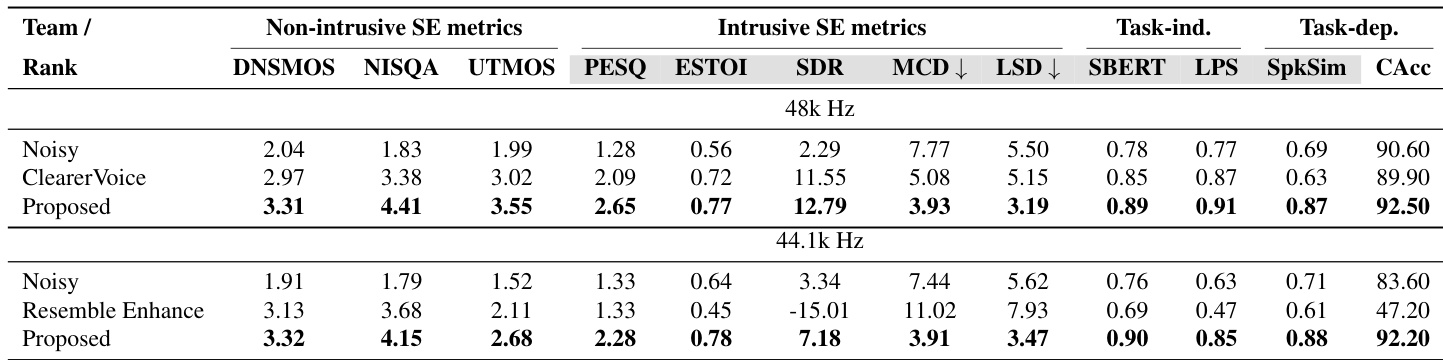
The authors evaluate their speech enhancement model on unseen languages from the FLEURS dataset to demonstrate language agnosticism. Results indicate that while a baseline generative restoration method achieves the highest perceptual quality scores, it significantly compromises speaker identity preservation. In contrast, the authors' proposed approach, particularly when fine-tuned on high-quality data, maintains high speaker similarity and generally improves automatic speech recognition accuracy. The baseline restoration method achieves the highest perceptual quality scores across all languages but yields the lowest speaker similarity. The proposed method preserves speaker identity much better than the baseline, achieving the highest speaker similarity scores. Fine-tuning the model on a high-quality subset improves character accuracy for Italian and Japanese compared to the original audio.
The authors apply their speech enhancement model to clean training data for a zero-shot text-to-speech system on unseen languages. The results demonstrate that enhancing both the context prompt and the training audio substantially reduces character and word error rates compared to using original audio. Enhancing both the context and training audio results in the lowest character and word error rates for the evaluated languages. Enhancing the training audio alone leads to significant reductions in error rates compared to the baseline condition. Enhancing the context audio consistently improves speaker similarity metrics and often improves codec distance scores.
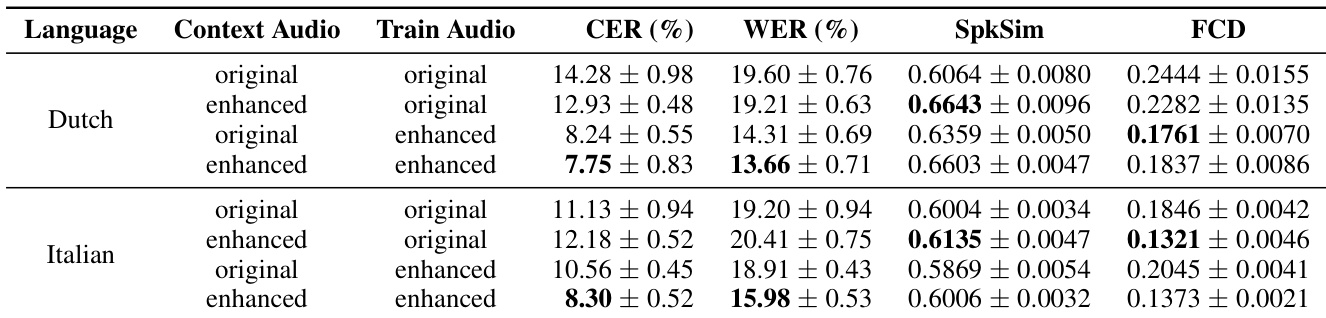
Theauthors investigate the application of their speech enhancement model for cleaning training data in zero-shot text-to-speech tasks for unseen languages. Results demonstrate that enhancing both the context and training audio leads to substantial improvements in downstream TTS performance. Specifically, the method reduces error rates and acoustic distance metrics while maintaining speaker similarity. Enhancing both context and training audio significantly lowers character and word error rates for Dutch and Italian text-to-speech models. The Fréchet codec distance improves markedly when the model utilizes enhanced audio inputs for both context and training. Speaker similarity is preserved or slightly improved, showing the enhancement process effectively maintains speaker identity.

The evaluation first demonstrates that a shifted anechoic clean target with GAN correction consistently beats early-reflected targets in perceptual quality and intelligibility. Compared with open-source models and tested on unseen languages, the proposed enhancer attains top perceptual scores without hallucination, preserves speaker identity far better than generative restoration, and improves downstream ASR. Using the model to clean context and training audio for zero-shot TTS substantially lowers word error rates and acoustic distances while maintaining speaker similarity.