Command Palette
Search for a command to run...
TADA: Ein generativer Rahmenwerk für die Sprachmodellierung durch text-akustische Dualausrichtung
TADA: Ein generativer Rahmenwerk für die Sprachmodellierung durch text-akustische Dualausrichtung
Trung Dang Sharath Rao Ananya Gupta Christopher Gagne Panagiotis Tzirakis Alice Baird Jakub Piotr Cłapa Peter Chin Alan Cowen
Zusammenfassung
Moderne Text-to-Speech-Systeme (TTS) setzen zunehmend auf Architekturen basierend auf Large Language Models (LLMs), um skalierbare und hochauflösende Zero-Shot-Generierung zu erreichen. Diese Systeme basieren jedoch typischerweise auf einer akustischen Tokenisierung mit fester Frame-Rate, was zu Sprachsequenzen führt, die deutlich länger sind und asynchron zu dem entsprechenden Text verlaufen. Neben der Rechenineffizienz führt diese Diskrepanz in der Sequenzlänge häufig zu Halluzinationen im TTS und verstärkt die Lücke zwischen den Modalitäten in der gesprochenen Sprachmodellierung (SLM). In diesem Artikel präsentieren wir ein neues Tokenisierungsschema, das eine synchronisierte Eins-zu-Eins-Beziehung zwischen kontinuierlichen akustischen Merkmalen und Text-Tokens etabliert und damit eine einheitliche, single-stream Modellierung innerhalb eines LLM ermöglicht. Wir zeigen, dass diese synchronisierten Tokens eine hochwertige Rekonstruktion des Audios gewährleisten und effektiv in einem latenten Raum von einem Large Language Model mit einem Flow-Matching-Kopf modelliert werden können. Darüber hinaus ermöglicht die Fähigkeit, die Sprachmodalität nahtlos im Kontext umzuschalten, die textbasierte Guidance – eine Technik, die Logits aus dem textbasierten und dem Text-Sprach-Modus kombiniert, um die Lücke zur rein textbasierten LLM-Intelligenz flexibel zu überbrücken.
One-sentence Summary
TADA, a generative speech modeling framework, introduces a synchronous tokenization scheme that aligns acoustic features one-to-one with text tokens for unified single-stream LLM modeling, employing a flow matching head and text-only guidance to bridge the modality gap toward text-only LLM intelligence while achieving high-fidelity zero-shot TTS with reduced hallucinations and computational inefficiency.
Key Contributions
- A synchronous tokenization method enforces one-to-one alignment between acoustic features and text tokens, enabling unified single‑stream processing within a large language model and avoiding the sequence‑length mismatch of fixed‑rate acoustic tokens.
- These synchronous tokens preserve high‑fidelity audio reconstruction and are effectively learnable in a latent space by a large language model augmented with a flow matching head.
- Text‑only guidance is introduced, a technique that blends logits from text‑only and joint text‑speech modes to bridge the modality gap and incorporate text‑only large language model intelligence into spoken language modeling.
Introduction
The authors tackle speech generation, where aligning linguistic content with acoustic realizations remains a core challenge. Prior approaches typically treat text-to-speech as a sequential mapping or rely on separate alignment modules, often leading to brittle prosody and limited expressiveness. They introduce TADA, a generative framework that jointly models text and acoustic representations through a dual-alignment mechanism, enabling more natural and controllable speech synthesis.
Dataset
The authors construct a large multilingual speech corpus from three sources and process it for training. Key details are outlined below.
- LibriLight corpus: a public English audiobook collection.
- English proprietary dataset: curated specifically for conversational speech.
- Multilingual proprietary dataset: speech in seven languages (Chinese, French, Italian, Japanese, Portuguese, Polish, German).
All raw audio is segmented with voice activity detection (VAD) into utterances not exceeding 30 seconds. This yields 270k hours of English data and 635k hours of non-English data, for a total exceeding 900k hours.
Processing pipeline and filtering:
- Automatic transcription: Parakeet-TDT-0.6b-v2 transcribes English and European languages; Whisper-V3 transcribes Chinese and Japanese.
- Alignment and token vectors are pre-extracted from the transcripts before training begins.
- Hallucination filtering is based on alignment metrics. A segment is discarded if the aligned positions span more than three consecutive frames, or if a gap between aligned positions exceeds 150 frames (3 seconds). Such patterns tend to indicate hallucinated text, non-speech background, or missing transcription. Filtering can be performed dynamically during training, using the alignment information.
The data is used directly for model training with on-the-fly hallucination filtering. No further cropping or special mixture ratios are reported.
Method
The authorspropose a novel framework that establishes a one-to-one synchronization between continuous acoustic features and text tokens, enabling unified, single-stream modeling within a Large Language Model (LLM). This approach consists of two primary stages: a joint speech-text tokenization module and the TADA (Text-Acoustic Dual-Alignment) modeling architecture.
The tokenization module comprises a temporal aligner, a token encoder, and an acoustic decoder. The aligner processes a speech waveform and its corresponding text token IDs to generate a precise mapping between text tokens and audio frames using Connectionist Temporal Classification (CTC) and the Viterbi algorithm.
The encoder and decoder operate within a Variational Autoencoder (VAE) framework. As shown in the figure below:
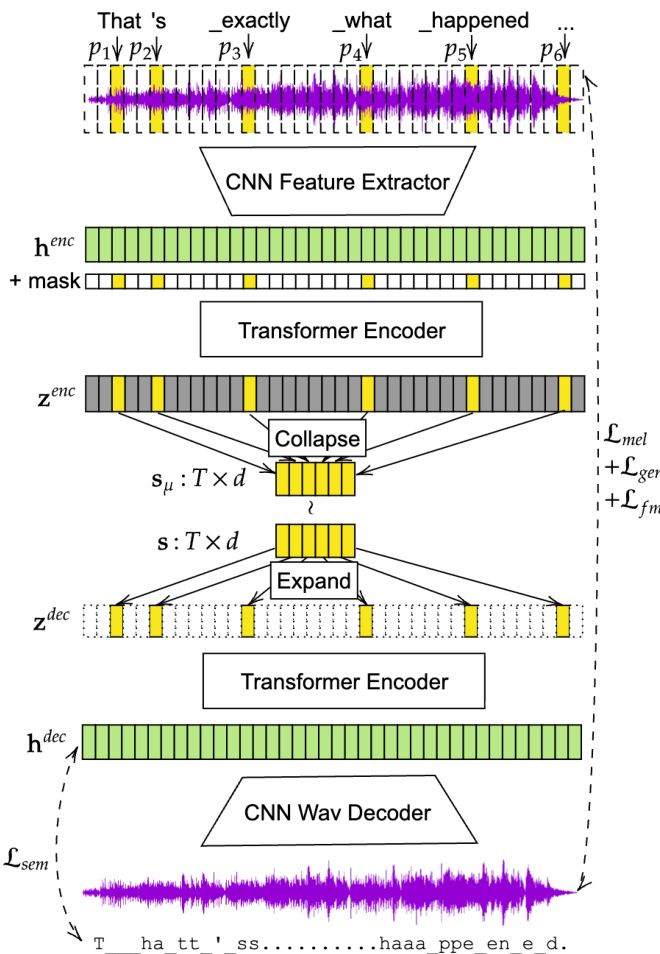
The encoder utilizes a CNN-based feature extractor to project raw audio into frame-level representations, followed by a transformer-based encoder that incorporates alignment positions. A binary indicator mask guides the multi-head attention mechanism to concentrate acoustic information into text-aligned positions. The sequence is then collapsed to extract latent mean vectors for each linguistic token. To ensure robust autoregressive modeling, the reparameterization trick is applied to sample the latent representation. The decoder performs feature expansion on these tokens, guided by alignment positions, to produce a dense sequence that is transformed via a Transformer and a multi-layer CNN-based module to synthesize the final raw waveform. The VAE is optimized using a composite objective function including multi-scale mel-spectrogram loss, adversarial losses, feature matching loss, semantic loss, and KL divergence.
To model these synchronized tokens, the authors introduce TADA, which integrates an LLM backbone with a flow matching head. Refer to the framework diagram:
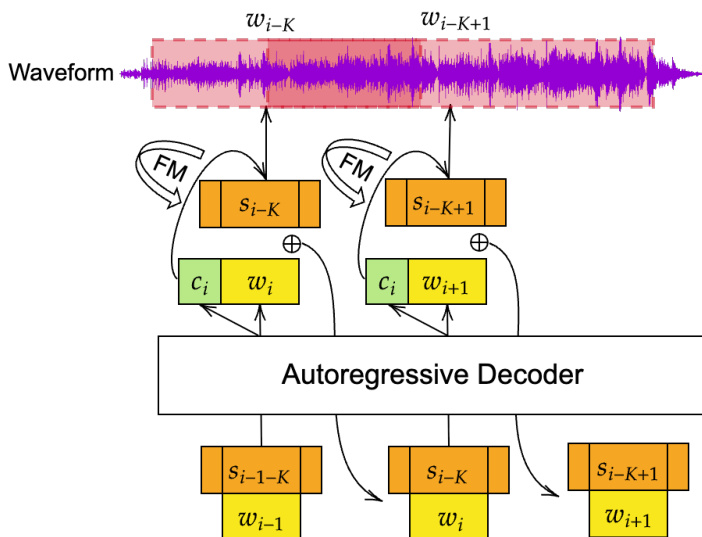
The architecture modifies a conventional LLM by additively fusing text and acoustic input embeddings. To allow for text lookahead, acoustic features are shifted by K positions, coupling the text token at position i with the acoustic features for the token at position i−K. This synchronous modeling maximizes audio temporal context for a fixed sequence length. The last hidden state of each LLM step is fed into both a language modeling head and a flow matching head.
The flow matching head jointly predicts the acoustic features and the temporal duration associated with each text token. It employs Bit Diffusion with gray coding to model discrete frame durations, specifically the number of preceding and successive blank frames relative to the token. Conditioned on the LLM hidden state ci, the head learns a vector field vθ(yt,t∣ci) that transforms a Gaussian noise distribution to the target distribution. The training objective minimizes the flow matching loss, optionally combined with text cross-entropy and knowledge distillation losses.
To mitigate the modality gap often caused by introducing audio to language models, the authors propose Speech Free Guidance (SFG). This technique blends logits from text-only and text-speech modes by adjusting the logit scale, allowing the model to seamlessly toggle speech modality within the context and bridge the capability gap toward text-only LLM intelligence with minimal inference overhead. Additionally, streamable rejection sampling is employed at the step level to steer generation away from low-quality outputs and ensure speaker consistency by ranking flow-matching candidates based on cosine similarity to a reference speaker embedding.
Experiment
The evaluation covers voice cloning on SeedTTS-Eval, LibriTTS, and EARS using objective and subjective metrics, and spoken language modeling via conversational perplexity and story cloze tasks. TADA’s synchronous tokenization achieves zero hallucinations and competitive speaker similarity, with long-form expressiveness improved by text-free guidance and rejection sampling. In spoken language modeling, text-only guidance enables the model to surpass text-speech baselines and approach text-only accuracy, while speech context can further boost story understanding. Analysis confirms robust fixed-rate reconstruction at low frame rates, efficient inference despite diffusion overhead, and the importance of knowledge distillation for preserving linguistic ability.
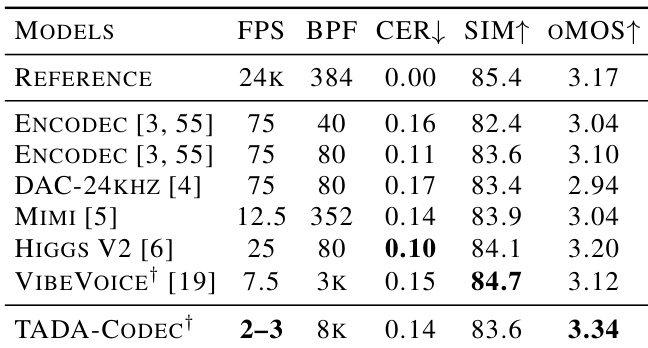
The authors evaluate the language capabilities of their TADA models on conversational perplexity and spoken narrative understanding benchmarks. Results show that while incorporating speech modality slightly impacts pure text performance, the model effectively handles text-speech tasks and outperforms larger baselines on specific benchmarks. Applying text-only guidance further boosts performance, allowing the model to surpass other text-speech baselines and closely match text-only accuracy. TADA models achieve strong text-only perplexity scores, outperforming base Llama models due to fine-tuning on spoken text distributions. In text-speech mode, TADA-3B-ML outperforms the larger SpiritLM-7B on the tSC benchmark despite having fewer parameters. The application of text-only guidance enables TADA-3B-ML to surpass all text-speech baselines, closely approaching its text-only performance levels.
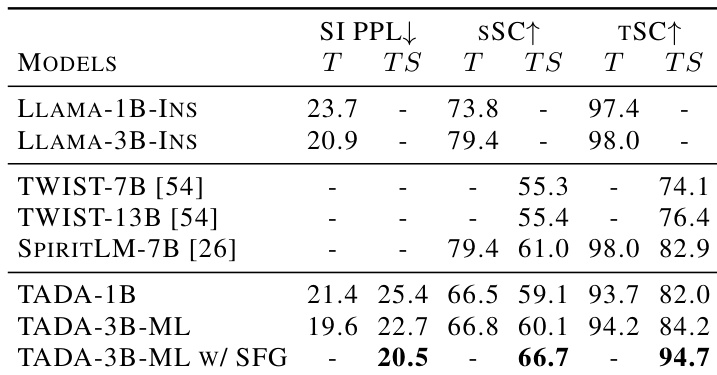
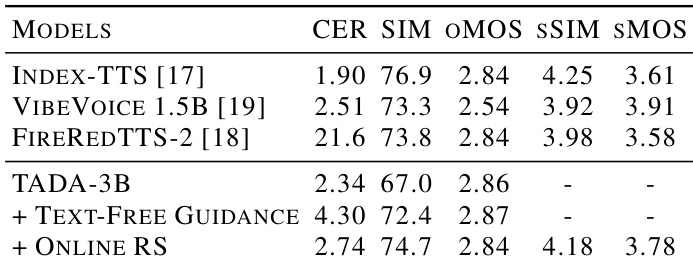
The authors compare the reconstruction performance of TADA-Codec against various discrete and continuous baselines to assess its viability as a modeling target. Results indicate that despite utilizing a significantly lower frame rate, TADA-Codec achieves reconstruction quality comparable to fixed-rate tokenizers. Notably, it attains the highest perceptual audio quality score among the evaluated models. TADA-Codec operates at a substantially lower frame rate than baselines like EnCodec and DAC while maintaining competitive reconstruction fidelity. TADA-Codec achieves the highest objective mean opinion score, outperforming the reference and other models in perceptual quality. While other models lead in specific metrics such as character error rate or speaker similarity, TADA-Codec remains competitive across all dimensions.
Theauthors conduct an ablation study to analyze the trade-off between language preservation and audio quality using different language preservation loss configurations. Results show that text-to-speech performance remains consistent across all variants, while the inclusion of knowledge distillation loss achieves the best language preservation. Text-to-speech quality metrics remain stable across different loss weight configurations. Increasing the cross-entropy loss weight improves perplexity compared to the base configuration. Combining cross-entropy and knowledge distillation losses yields the lowest perplexity, indicating the best language preservation.
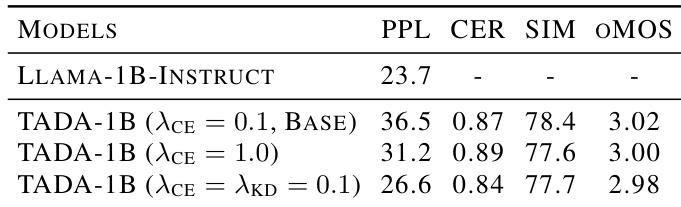
Results from the EARS dataset evaluation show that the TADA-3B model benefits significantly from text-free guidance and online rejection sampling to counteract speaker drifting in long-form generation. The enhanced model achieves competitive subjective performance, ranking second in both speaker similarity and naturalness among the compared systems. The addition of text-free guidance and online rejection sampling to TADA-3B substantially improves speaker similarity, bringing it close to the top-performing baseline. In subjective evaluations, the enhanced TADA model ranks second for both speaker similarity and naturalness, indicating high expressiveness. FireRedTTS-2 exhibits a much higher character error rate than the other models, suggesting lower reliability in content preservation despite comparable similarity scores.
The authors evaluate the computational overhead and text-to-speech performance of TADA-1B across varying flow matching sampling steps. Results indicate that speech quality converges at a moderate number of sampling steps, which provides the optimal balance of low error rates and high similarity and naturalness scores. Despite the increased latency per token associated with more sampling steps, the model maintains a low real-time factor and achieves significant overall inference speedup due to its reduced frame rate. Speech generation quality converges at a moderate number of flow matching sampling steps, yielding the best performance across all quality metrics. Increasing the number of sampling steps increases the per-token latency for the flow matching component, but the overall real-time factor remains highly efficient. The model achieves substantial inference speedup compared to baselines despite the diffusion head overhead, owing to its significantly lower frame rate.
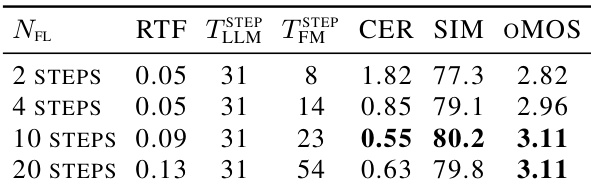
The experiments evaluate TADA on conversational language understanding, codec reconstruction, loss configuration ablations, long-form generation, and inference efficiency. The model preserves language capabilities while effectively handling speech modalities, and a low-frame-rate codec achieves the highest perceptual quality among tested tokenizers. Text-free guidance with online rejection sampling improves speaker similarity in long-form synthesis, and a moderate number of flow matching steps yields an optimal balance of quality and speed, leveraging the model’s reduced frame rate for significant inference acceleration.