Command Palette
Search for a command to run...
AutoFigure: Generierung und Verfeinerung publikationsreifer wissenschaftlicher Illustrationen
AutoFigure: Generierung und Verfeinerung publikationsreifer wissenschaftlicher Illustrationen
Minjun Zhu Zhen Lin Yixuan Weng Panzhong Lu Qiujie Xie Yifan Wei Sifan Liu Qiyao Sun Yue Zhang
Zusammenfassung
Hochwertige wissenschaftliche Illustrationen sind entscheidend für die effektive Vermittlung komplexer wissenschaftlicher und technischer Konzepte. Dennoch bleibt ihre manuelle Erstellung in der Wissenschaft und der Industrie allgemein als Engpass anerkannt. Wir präsentieren FigureBench, den ersten großflächigen Benchmark zur Generierung wissenschaftlicher Illustrationen aus langformatigen wissenschaftlichen Texten. Der Benchmark umfasst 3.300 hochwertige wissenschaftliche Text-Bild-Paare und deckt vielfältige Text-zu-Illustrations-Aufgaben aus wissenschaftlichen Artikeln, Übersichtsarbeiten, Blogs und Lehrbüchern ab.Darüber hinaus stellen wir AUTOFIGURE vor, den ersten agentic Framework zur automatischen Generierung hochwertiger wissenschaftlicher Illustrationen auf Grundlage langformatiger wissenschaftlicher Texte. Vor der Darstellung des Endergebnisses durchläuft AUTOFIGURE umfassende Denkprozesse, Rekombinations- und Validierungsschritte, um ein Layout zu erzeugen, das sowohl strukturell solide als auch ästhetisch anspruchsvoll ist. Dabei wird eine wissenschaftliche Illustration generiert, die strukturelle Vollständigkeit mit ästhetischer Attraktivität verbindet.Auf Basis der hochwertigen Daten aus FigureBench führen wir umfangreiche Experimente durch, um die Leistungsfähigkeit von AUTOFIGURE im Vergleich zu verschiedenen Baseline-Methoden zu testen. Die Ergebnisse zeigen, dass AUTOFIGURE alle Baseline-Methoden konsequent übertrifft und wissenschaftliche Illustrationen in Publikationsqualität erzeugt. Der Code, der Datensatz und der Hugging Face Space werden unter https://github.com/ResearAI/AutoFigure veröffentlicht.
One-sentence Summary
The authors present AUTOFIGURE, the first agentic framework generating publication-ready scientific illustrations from long-form scientific text through extensive thinking, recombination, and validation, alongside FigureBench, a large-scale benchmark containing 3,300 high-quality scientific text-figure pairs, where experiments demonstrate that AUTOFIGURE consistently surpasses all baseline methods, with code and resources publicly released.
Key Contributions
- This work introduces FigureBench, the first large-scale benchmark for generating scientific illustrations from long-form texts, which contains 3,300 high-quality text-figure pairs from diverse sources. The dataset supports various text-to-illustration tasks and provides a foundation for training and evaluating automated scientific visualization tools.
- The paper presents AUTOFIGURE, an agentic framework that automatically generates high-quality scientific illustrations by engaging in extensive thinking and validation before rendering the final result. This process ensures the output achieves both structural completeness and aesthetic appeal required for academic publishing.
- Extensive experiments grounded in VLM-as-a-judge paradigms and human expert assessments show that the method consistently surpasses baseline methods in producing publication-ready illustrations. The associated code, dataset, and Hugging Face space are released to enable further research into AI-driven scientific communication.
Introduction
High-quality scientific illustrations are essential for communicating complex concepts, yet their manual creation remains a major bottleneck for both human researchers and emerging AI scientists. Existing automated approaches typically rely on short captions or rearrange existing content, while mainstream text-to-image models struggle to maintain structural fidelity when processing long-form scientific texts. To overcome these challenges, the authors present FigureBench, the first large-scale benchmark designed for generating illustrations from long-form scientific documents. They further develop AutoFigure, an agentic framework that employs a Reasoned Rendering paradigm to separate layout planning from aesthetic rendering, ensuring the final output meets publication standards for both accuracy and visual appeal.
Dataset
- Dataset Composition and Sources
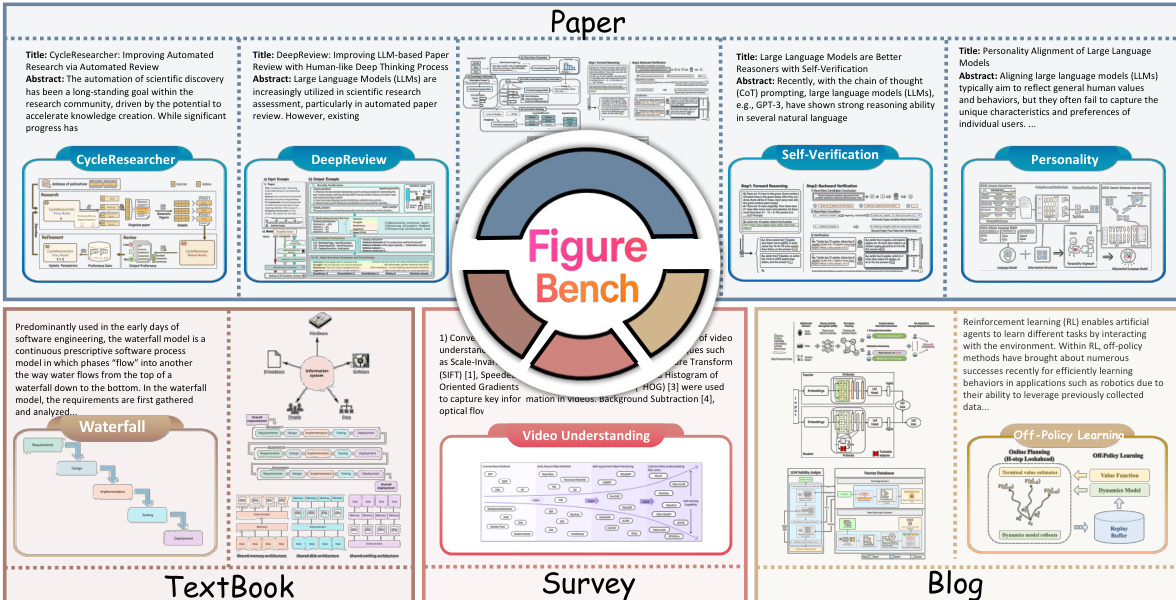
- The authors introduce FigureBench, a benchmark constructed from four distinct sources: research papers, surveys, technical blogs, and textbooks.
- All data strictly adheres to open-source licenses, with papers sourced from the Research-14K dataset and textbooks drawn from platforms like OpenStax.
- Key Details for Each Subset
- The Test Set consists of 300 high-quality samples.
- 200 samples originate from the Research-14K dataset. GPT-5 selected illustrations representing core methodology, and two independent annotators retained only conceptual figures with unanimous approval.
- An additional 100 samples were manually curated from AI surveys on arXiv, technical blogs, and educational textbooks to ensure domain diversity.
- The Development Set contains 3,000 samples. The authors fine-tuned a vision-language model on the Test Set to serve as an automated filter for the larger Research-14K corpus.
- Data Usage and Training Splits
- The Test Set is reserved strictly for evaluation purposes.
- The Development Set is designed for training and development, though the proposed AUTOFIGURE pipeline operates as an inference-only system.
- The authors provide the Development Set to facilitate future exploration of end-to-end or trainable methods by the community.
- Processing and Metadata Construction
- The curation process filters out data-driven charts to focus on conceptual illustrations where visual elements are explicitly described in the text.
- Statistical metadata includes text density, color counts, and structural components, calculated automatically using the InternVL 3.5 model.
- A human sanity check on 21 random samples verified the reliability of these automated measurements against manual annotations.
Method
The authors introduce AutoFigure, a decoupled generative paradigm designed to produce high-fidelity scientific illustrations by separating the reasoning and rendering processes. This approach addresses the challenge of creating semantically accurate and visually coherent figures through a three-stage pipeline.
The overall framework is illustrated in the architecture diagram below, which outlines the transition from unstructured text to a final publication-ready illustration.
Stage I: Conceptual Grounding and Layout Generation Given a long-form scientific document T, the first stage produces a machine-readable symbolic layout S0 (e.g., SVG/HTML) and a style descriptor A0. A Concept-Extraction agent processes the input text to distill a methodology summary Tmethod and identifies entities and relations to be visualized as nodes and directed edges. This structure is serialized into a markup-based symbolic layout S0, where S0 encodes a directed graph G0=(V0,E0).
Stage II: Critique-and-Refine The core innovation of the method lies in a self-refinement loop that simulates a dialogue between an AI "designer" and an AI "critic" to optimize the blueprint for structural coherence and logical consistency. The initial layout (S0,A0) is evaluated to get an initial score q0, setting the current best version (Sbest,Abest). In each iteration i, the system generates a superior solution through the following process:
Fbest(i)=Feedback(Φcritic(Sbest,Abest))(Scand(i),Acand(i))=Φgen(Tmethod,Fbest(i)),The critic Φcritic evaluates the best-performing layout for alignment, balance, and overlap avoidance, producing textual feedback Fbest(i). The generator Φgen then uses this feedback to reinterpret Tmethod and produce a candidate layout (Scand(i),Acand(i)). If the candidate score qcand(i) exceeds the current best, it replaces the best version. This loop continues until convergence or a preset iteration limit, yielding a logically consistent and aesthetically balanced conditioning layout (Sfinal,Afinal).
Stage III: Rendering Strategy The final stage translates the optimized symbolic blueprint into a high-fidelity illustration Ifinal. A transformation function Φprompt converts the layout and style into an exhaustive text-to-image prompt, which is fed into a multimodal generative model to render an image Ipolished. To ensure textual accuracy, the system employs an erase-and-correct process. A non-LLM eraser Φerase removes text pixels from Ipolished to create a clean background Ierased. An OCR engine Φocr extracts preliminary strings, and a multimodal verifier Φverify aligns these with ground-truth labels Tgt parsed from Sfinal. Finally, the corrected text map Tcorr is rendered as vector-text overlays on top of Ierased to obtain the final illustration.
The effectiveness of this pipeline is demonstrated by comparing the generated output against other methods. As shown in the figure below, AutoFigure produces a high-fidelity scientific diagram with crisp details and a pleasing color scheme, outperforming alternatives like SVG generation or direct diagram agents.

Experiment
This study evaluates AUTOFIGURE through automated benchmarks on FigureBench, a domain expert study involving paper authors, and controlled ablation experiments to isolate key modules. The framework consistently outperforms baseline methods by effectively balancing scientific accuracy with visual aesthetics, resulting in figures that experts consider suitable for publication. Qualitative case studies highlight superior handling of complex scientific structures compared to existing approaches, while ablation analyses validate the necessity of symbolic layouts and refinement loops for achieving high quality outputs.
The study evaluates the system's ability to adapt to different visual styles while maintaining overall quality. Results indicate that while overall performance remains stable across styles, specific dimensions like visual design appeal and communication effectiveness vary depending on the chosen aesthetic prompt. The 'Comic' style prompt achieves the highest visual design ratings but results in lower scores for communication clarity and flow. The 'Minimalist' style prompt outperforms other styles in communication effectiveness and content sophistication, despite lower visual design scores. Overall quality scores remain consistent across all tested style variations, demonstrating the system's robustness to aesthetic changes.

The authors evaluate the AUTOFIGURE framework using different open-source reasoning backbones, specifically Qwen3-VL-235B, GLM-4.5V, and ERNIE-4.5-VL. The results indicate that GLM-4.5V achieves the highest overall win rate, demonstrating superior performance in communication and content fidelity compared to the other models. In contrast, Qwen3-VL-235B shows strong capabilities in visual design aspects like aesthetics and polish, while ERNIE-4.5-VL underperforms significantly across all measured dimensions. GLM-4.5V achieves the highest overall win rate, outperforming Qwen3-VL-235B and ERNIE-4.5-VL in blind pairwise comparisons. Qwen3-VL-235B demonstrates superior visual design quality, achieving the highest scores in aesthetics, expressiveness, and polish. ERNIE-4.5-VL exhibits the lowest performance across all metrics, particularly in communication clarity and content fidelity.

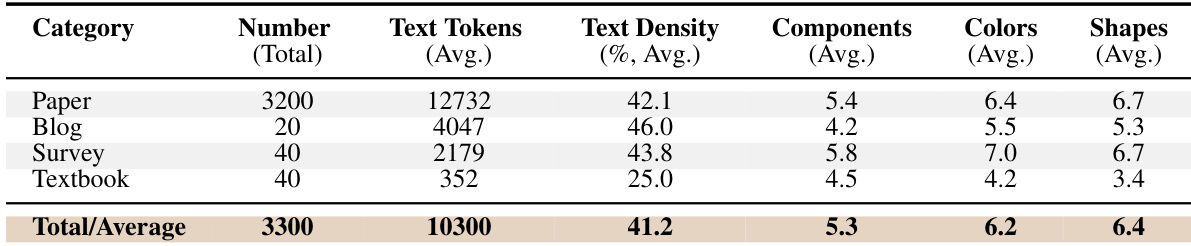
The the the table details the statistical composition of the FigureBench dataset across four distinct document categories. It compares categories based on sample volume, text volume, text density, and visual complexity metrics such as the average number of components, colors, and shapes. The data reveals that academic papers are the most prevalent and text-heavy category, while textbooks represent the least text-dense and visually simplest group. Academic papers dominate the dataset in sample count and average text token volume. Textbook entries exhibit the lowest text density and the simplest visual structure with fewer components and colors. Survey documents demonstrate the highest visual complexity, containing the most components and colors on average.
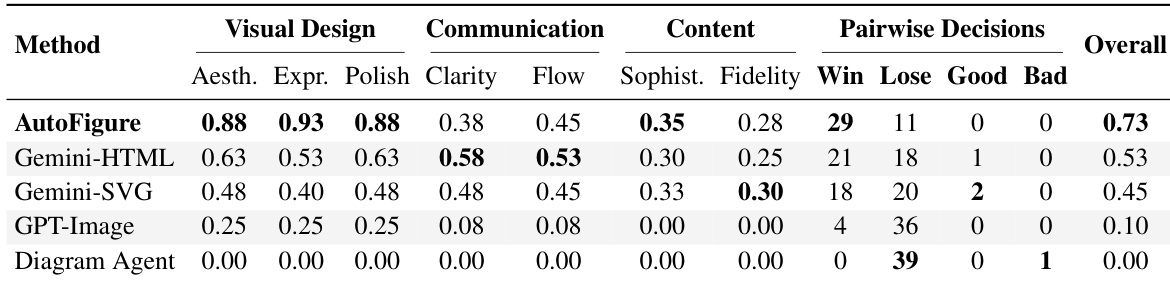
The study compares AutoFigure against multiple baseline methods, including code-generation and end-to-end models, to evaluate figure generation quality. Results demonstrate that AutoFigure achieves the highest overall performance, particularly excelling in visual design dimensions such as aesthetics and expressiveness. While code-based baselines show moderate strength in communication clarity, AutoFigure dominates in pairwise comparisons, indicating a strong preference for its outputs. AutoFigure achieves the highest overall score and wins the majority of pairwise comparisons against other models. Visual design metrics, including aesthetics and polish, are significantly higher for AutoFigure compared to baselines. Code-based baselines like Gemini-HTML perform better on communication clarity but lag significantly in visual appeal and overall quality.
The authors conduct an ablation study to isolate the impact of the Text Refinement module on the final output quality. Results demonstrate that the full model outperforms the variant without refinement, particularly in visual design dimensions such as aesthetics and professional polish. This confirms that the refinement stage is essential for eliminating artifacts and achieving publication-ready standards. The complete model achieves a higher overall score than the version lacking the text refinement module. Visual design metrics including aesthetics and expressiveness show the most notable improvement with the refinement step. The refinement process effectively enhances professional polish, ensuring the figures meet high-quality standards.

The study evaluates the AUTOFIGURE framework through assessments of visual style adaptation, backbone model performance, and comparisons against baseline methods. Results demonstrate that while overall quality remains consistent across aesthetic variations, specific styles present trade-offs between visual design appeal and communication clarity. The full framework significantly outperforms baselines and ablated versions, confirming that the GLM-4.5V backbone and Text Refinement module are essential for achieving high visual fidelity and professional polish.