Command Palette
Search for a command to run...
RadImageNet-VQA: Ein großflächiger CT- und MRI-Datensatz für radiologische visuelle Fragen-und-Antworten-Aufgaben
RadImageNet-VQA: Ein großflächiger CT- und MRI-Datensatz für radiologische visuelle Fragen-und-Antworten-Aufgaben
Leo Butsanets Charles Corbiere Julien Khlaut Pierre Manceron Corentin Dancette
Zusammenfassung
In dieser Arbeit stellen wir RadImageNet-VQA vor, einen großskaligen Datensatz, der darauf abzielt, radiologische Visual Question Answering (VQA) für CT- und MRT-Untersuchungen voranzubringen. Bestehende medizinische VQA-Datensätze sind zwar in ihrer Skalierbarkeit begrenzt, konzentrieren sich überwiegend auf Röntgenbilder oder biomedizinische Illustrationen und neigen zu textbasierten Abkürzungen (text-based shortcuts). RadImageNet-VQA hingegen basiert auf von Experten kuratierten Annotationen und stellt 750.000 Bilder mit 7,5 Millionen QA-Paaren (Frage-Antwort-Doppelfelder) bereit. Der Datensatz umfasst drei Kernaufgaben – Erkennung von Abnormalitäten, Anatomieerkennung und Identifikation von Pathologien – und erstreckt sich über 8 anatomische Regionen sowie 97 Pathologiekategorien. Er unterstützt offene, geschlossene und Multiple-Choice-Fragen. Umfangreiche Experimente zeigen, dass State-of-the-Art Vision-Language-Modelle (VL-Modelle) weiterhin Schwierigkeiten bei der feinkörnigen Identifikation von Pathologien haben, insbesondere in offenen Fragestellungen und selbst nach Fine-Tuning. Analysen, die ausschließlich auf Text basieren, zeigen außerdem, dass die Genauigkeit der Modelle ohne Bildinputs auf nahezu zufällige Werte einbricht. Dies bestätigt, dass RadImageNet-VQA frei von linguistischen Abkürzungen ist. Der vollständige Datensatz und der Benchmark stehen öffentlich unter https://huggingface.co/datasets/raidium/RadImageNet-VQA zur Verfügung.
One-sentence Summary
The authors introduce RadImageNet-VQA, a large-scale CT and MRI dataset for radiologic visual question answering comprising 750,000 images paired with 7.5 million expert-curated QA samples spanning abnormality detection, anatomy recognition, and pathology identification across 8 anatomical regions and 97 pathology categories, which is confirmed free of linguistic shortcuts and reveals that state-of-the-art vision-language models still struggle with fine-grained pathology identification, particularly in open-ended settings and even after fine-tuning.
Key Contributions
- RadImageNet-VQA provides a large-scale radiologic VQA dataset with 750K CT and MRI images, 7.5M question-answer pairs, three tasks (abnormality detection, anatomy recognition, pathology identification), eight anatomical regions, 97 pathology categories, and open-ended, closed-ended, and multiple-choice formats.
- State-of-the-art vision-language models still struggle with fine-grained pathology identification, especially in open-ended settings, and text-only analysis shows near-random accuracy without image inputs, confirming the dataset is free of linguistic shortcuts.
- Fine-tuning on RadImageNet-VQA produces substantial gains across all model families, while medical-pretrained vision encoders do not improve downstream performance.
Introduction
The authors introduce RadImageNet-VQA, a large-scale radiologic dataset for visual question answering that pairs 750,000 CT and MRI images with 7.5 million generated question-answer samples. This resource targets a gap in the field: while visual question answering offers a controlled and interpretable way to evaluate clinical reasoning in vision-language models, existing benchmarks lack sufficient coverage of cross-sectional imaging modalities like CT and MRI. Prior work has focused heavily on chest X-rays and report generation, where automatic evaluation metrics correlate poorly with clinical correctness, leaving few robust options for probing fine-grained radiological understanding. The authors’ main contribution is the release of this dataset spanning eight anatomical regions and 97 pathologies, along with a systematic evaluation showing that state-of-the-art vision-language models handle anatomy and basic abnormality detection but struggle with precise pathology identification, and that fine-tuning on their data yields substantial performance gains.
Dataset
Dataset Description: RadImageNet-VQA
The authors introduce RadImageNet-VQA, a large-scale dataset for radiologic visual question answering built from expert-curated CT and MRI images. It is designed to address the limited scale and narrow anatomical coverage of existing medical VQA benchmarks while eliminating linguistic shortcuts that let models answer without relying on images.
Dataset Composition and Sources
- The source data comes from RadImageNet, an expert-annotated medical imaging dataset where each image carries modality (CT or MRI), body part, and pathology labels.
- From this resource, the authors use only the CT and MRI subsets.
- The final training corpus contains roughly 750K images paired with 7.5M samples, consisting of 750K image-caption pairs and 6.75M QA pairs.
- A separate curated benchmark subset contains 1,000 CT/MRI images and 9,000 QA pairs.
Key Details for Each Subset
- Training set: Created by applying the full captioning and VQA generation pipeline to the entire RadImageNet training split. It covers 8 anatomical regions and 97 pathology categories.
- Benchmark subset: A curated evaluation set with 1,000 images and 9,000 QA pairs, balanced across anatomy, abnormality, and pathology tasks in open-ended, closed-ended, and multiple-choice formats.
How the Data Is Used
- The training set serves two purposes: radiologic captions for medical visual-text alignment and VQA data for instruction tuning.
- The benchmark subset is used to evaluate state-of-the-art vision-language models across three tasks:
- Anatomy recognition (identifying the imaged region)
- Abnormality detection (determining whether any abnormal finding exists)
- Pathology identification (distinguishing specific diseases within an anatomical context)
Processing and Construction Details
- Caption generation: Metadata fields (modality, anatomical region, pathology category) are converted into structured radiologic captions by sampling randomly from a diverse set of radiology-aware templates, producing formulations like "A [modality] scan of the [anatomy] showing [pathology]."
- VQA sample generation: Each image is converted into structured VQA samples using task-specific question-answer templates. For each task and question type, 2 to 7 linguistic variations are defined to prevent models from exploiting textual shortcuts.
- Closed-ended design: For anatomy and pathology questions, both positive and negative variants are generated, where the expected answer is "yes" (present) or "no" (absent). This probes whether models hallucinate organs or pathologies when they are not present.
- Multiple-choice distractors: For anatomy recognition, distractors are sampled from other anatomical regions in the dataset. For pathology identification, distractors are restricted to clinically plausible diseases from the same anatomical region, preventing models from solving questions by matching anatomy alone. The option "no pathology seen" is included in every pathology multiple-choice to reduce the bias of models assuming pathology is always present.
Experiment
The RadImageNet-VQA benchmark assesses vision-language models on CT and MRI images across three tasks—anatomy recognition, abnormality detection, and pathology identification—using open-ended, closed-ended, and multiple-choice questions. Zero-shot evaluation shows that anatomy is nearly solved but fine-grained pathology identification remains a severe bottleneck, especially in open-ended responses, where even the best models score low. Fine-tuning on radiologic data brings large improvements, nearly saturating anatomy and abnormality detection, yet pathology discrimination stays challenging, and standard vision encoders match or outperform medically pretrained ones. Text-only ablations demonstrate that the dataset effectively removes linguistic shortcuts, forcing models to rely on visual evidence rather than textual priors.
The authors evaluate state-of-the-art general-purpose and medical-oriented vision-language models on a radiologic visual question answering benchmark. Results indicate that while anatomy recognition is largely solved, fine-grained pathology identification remains a significant bottleneck, particularly for open-ended questions. General-purpose models generally achieve higher overall accuracy than medical-oriented variants, though the latter show specific advantages in open-ended pathology tasks. Anatomy recognition scores are consistently high across models, especially in multiple-choice and closed-ended formats, whereas open-ended pathology identification yields the lowest performance. General-purpose models lead in average accuracy and excel in abnormality detection and closed-ended pathology questions, suggesting broad pretraining provides a strong foundation. Medical-oriented models demonstrate superior performance specifically on open-ended pathology questions but do not consistently outperform general-purpose models across all tasks.
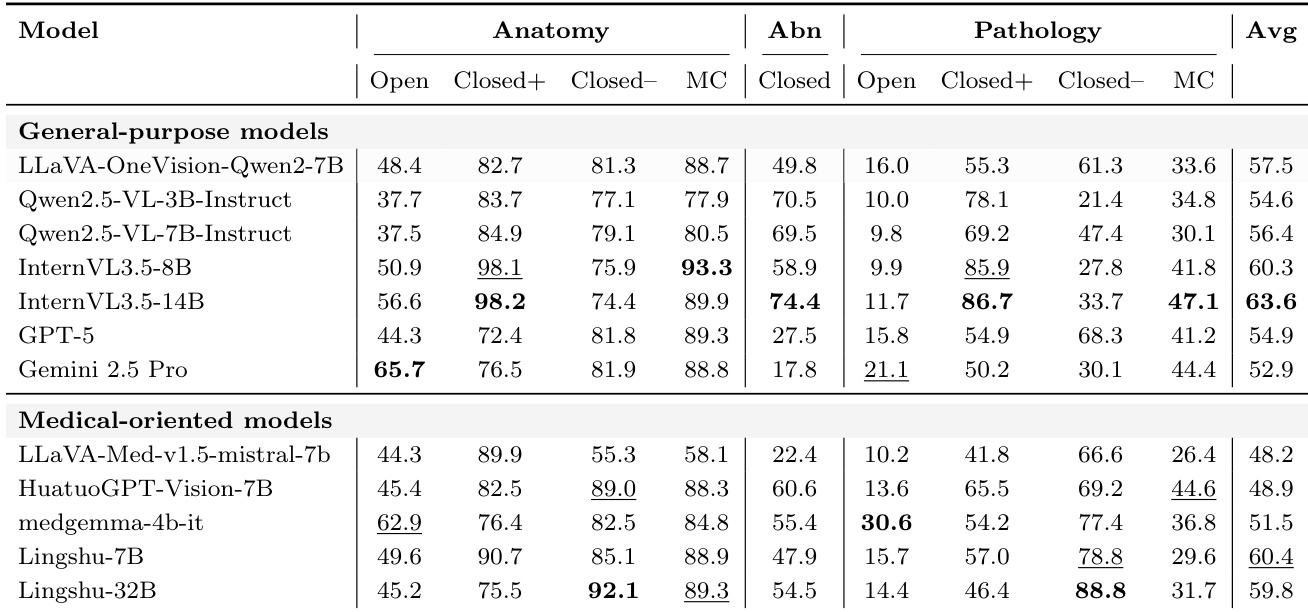
Thetable compares general-purpose and medical specialized models across 0%, 30%, and 100% conditions. Medical specialized models initially show significantly higher values than general-purpose models at 0%, but these values decrease as the percentage increases. The performance gap between the two model types narrows at 100%, suggesting convergence in capability under that condition. Medical specialized models like medgemma-4b-it and Lingshu-7B start with higher values at 0% compared to general-purpose models. There is a consistent downward trend in the values for medical specialized models as the percentage increases to 100%. General-purpose models maintain relatively stable values across all conditions, leading to a narrower gap with medical models at 100%.
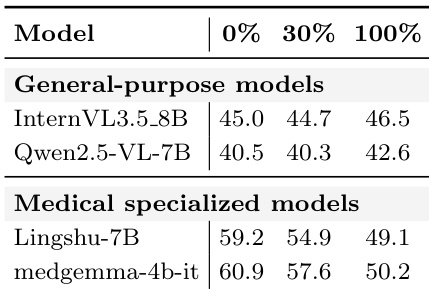
The authors fine-tune multiple vision-language models on a radiologic corpus and observe consistent performance gains across all architectures. Anatomy recognition reaches near-saturation levels after training, while abnormality detection shows significant relative improvements. However, pathology identification remains the primary bottleneck, achieving lower accuracy even after fine-tuning. Fine-tuning yields substantial accuracy improvements across most evaluated models and task categories. Anatomy recognition tasks are nearly solved post-training, with models achieving very high accuracy across all question formats. Pathology identification remains challenging, showing the lowest performance among the three tasks despite the gains from fine-tuning.
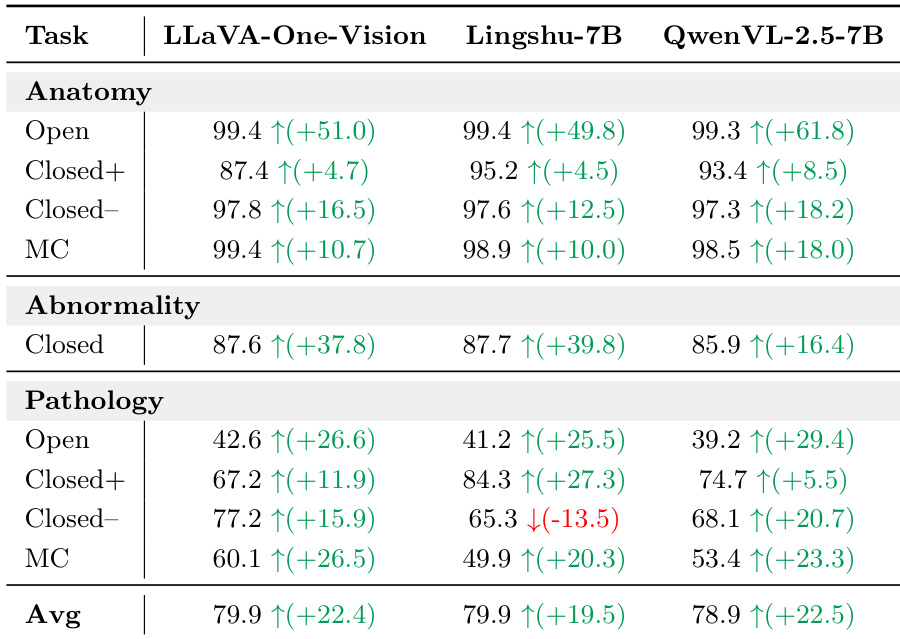
The authors validate the reliability of the LLM-as-a-judge evaluation framework for open-ended responses by comparing it against human annotations. The results demonstrate substantial agreement between the automated system and human reviewers, supporting its use for benchmarking. Notably, the alignment is stronger for anatomy recognition tasks than for pathology identification, reflecting the varying difficulty of the tasks. Human reviewers exhibit high agreement with the LLM judge across both anatomy and pathology categories. The automated evaluation shows higher consistency for anatomy recognition compared to the more challenging pathology identification. Cohen's kappa scores indicate substantial reliability, validating the LLM-as-a-judge approach for open-ended assessment.
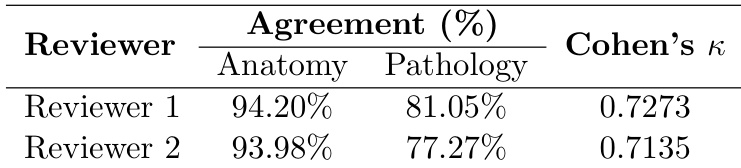
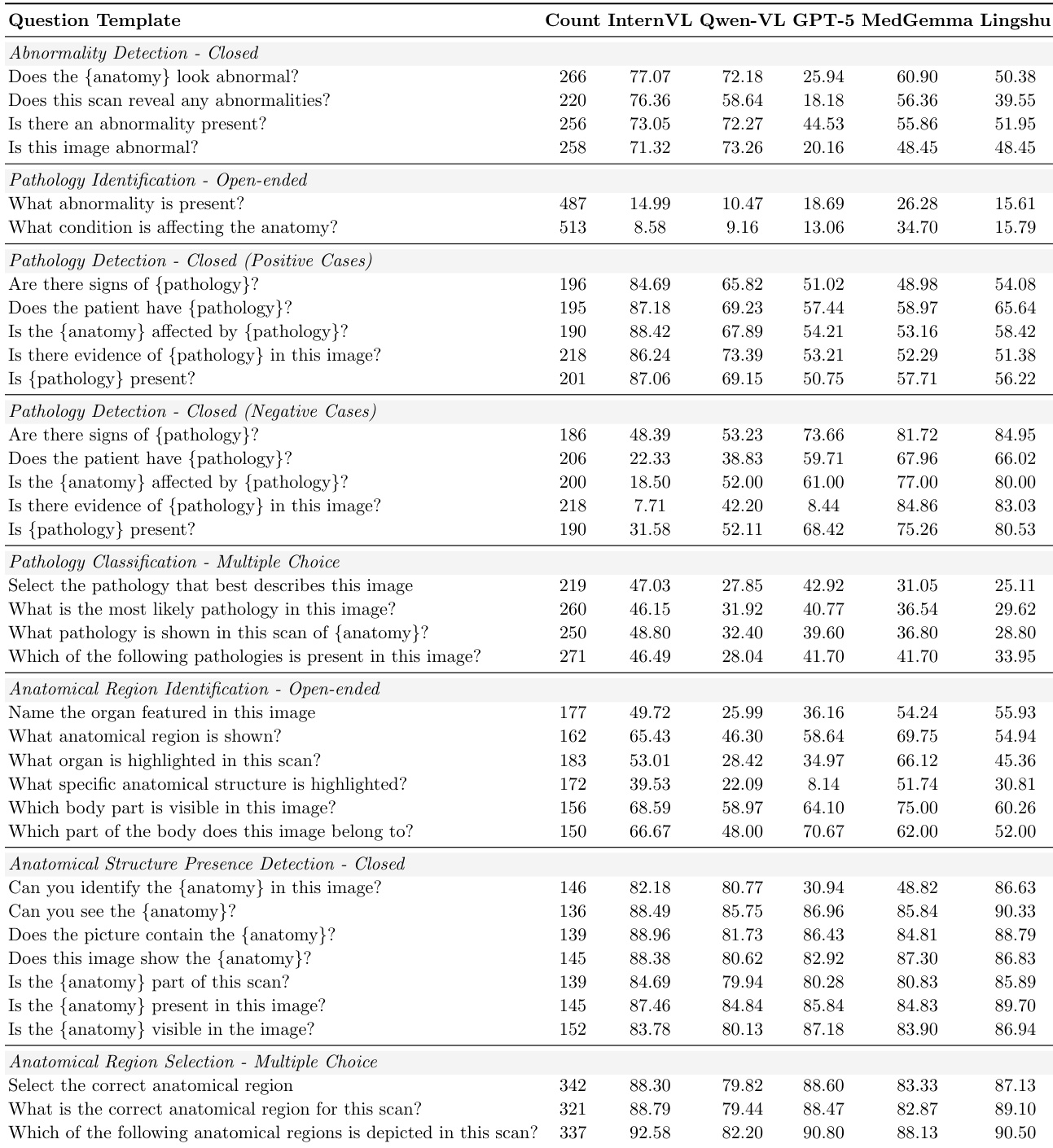
The authors present a detailed breakdown of zero-shot accuracy across different question templates and radiologic tasks. The data confirms that anatomical recognition and structure presence detection are highly accurate for most models, particularly in multiple-choice formats. In contrast, open-ended pathology identification proves extremely difficult, with all models scoring poorly, though medical-specific models like MedGemma show a slight edge. General-purpose models like InternVL generally outperform others in closed-ended pathology tasks for positive cases, while GPT-5 exhibits notably low performance on abnormality detection questions. Anatomical region selection and structure presence detection consistently yield high accuracy across models, suggesting these tasks are nearly solved. Open-ended pathology identification remains the most challenging task, with accuracy scores remaining very low across all evaluated models. General-purpose models like InternVL achieve high accuracy on positive pathology detection cases, whereas medical-oriented models perform significantly better on negative cases.
The authors evaluate general-purpose and medical-specific vision-language models on a radiologic visual question answering benchmark covering anatomy, abnormality detection, and pathology tasks across multiple-choice, closed-ended, and open-ended formats. Anatomy recognition is nearly solved across all models, while fine-grained pathology identification, especially in open-ended settings, remains the primary bottleneck even after fine-tuning. General-purpose models generally achieve higher overall accuracy, but medical-oriented models demonstrate specific advantages on open-ended pathology questions and in low-data regimes, though their edge narrows as training data increases. An LLM-as-a-judge evaluation protocol is validated against human annotations, showing strong agreement particularly for anatomy tasks and confirming the reliability of automated open-ended assessment.