Command Palette
Search for a command to run...
Über isolierte Wörter hinaus: Diffusion Brush für die Generierung von handschriftlichen Textzeilen
Über isolierte Wörter hinaus: Diffusion Brush für die Generierung von handschriftlichen Textzeilen
Gang Dai Yifan Zhang Yutao Qin Qiangya Guo Shuangping Huang Shuicheng Yan
Zusammenfassung
Bestehende Methoden zur Generierung von handschriftlichem Text konzentrieren sich primär auf isolierte Wörter. Die realistische handschriftliche Textgenerierung erfordert jedoch nicht nur die Berücksichtigung einzelner Wörter, sondern auch die Beziehungen zwischen ihnen, wie vertikale Ausrichtung und horizontaler Abstand. Daher stellt die Generierung kompletter Textzeilen eine vielversprechendere und umfassendere Aufgabe dar. Diese Aufgabe stellt jedoch erhebliche Herausforderungen dar, einschließlich der genauen Modellierung komplexer Stilmuster, die sowohl intra- als auch interwortliche Beziehungen umfassen, sowie der Aufrechterhaltung der Inhaltsrichtigkeit über viele Zeichen hinweg. Um diese Herausforderungen zu adressieren, schlagen wir DiffBrush vor, ein neues diffusionsbasiertes Modell für die Generierung von handschriftlichen Textzeilen. Im Gegensatz zu bestehenden Methoden glänzt DiffBrush sowohl in der Stilimitation als auch in der Inhaltsrichtigkeit durch zwei Schlüsselstrategien: (1) inhaltsentkoppeltes Stillelearning, das Stil von Inhalt trennt, um intra- und interwortliche Stilmuster durch Spalten- und Zeilenmaskierung besser zu erfassen; und (2) multiscale Inhaltslearning, das Zeilen- und Wortdiskriminatoren einsetzt, um globale Kohärenz und lokale Genauigkeit des textuellen Inhalts sicherzustellen. Umfangreiche Experimente zeigen, dass DiffBrush bei der Generierung hochwertiger Textzeilen, insbesondere bei der Stilverwandschaft und dem Inhaltserhalt, herausragende Leistungen bringt. Der Code ist verfügbar unter https://github.com/dailenson/DiffBrush
One-sentence Summary
DiffBrush, a diffusion-based model for handwritten text-line generation, decouples style from content via column- and row-wise masking and employs line and word discriminators for multi-scale content learning, surpassing prior isolated-word methods in style reproduction and content preservation.
Key Contributions
- A content-decoupled style learning strategy disentangles style from content via column- and row-wise masking, enabling the model to capture intra-word and inter-word handwriting patterns from a style reference.
- Multi-scale content learning employs line-level and word-level discriminators to supervise textual content, enforcing global coherence and local character accuracy while preserving style imitation.
- Experiments on three widely used handwritten datasets show that DiffBrush generates high-quality text lines with strong style reproduction and content preservation.
Introduction
Generating realistic handwritten text has advanced significantly, but most prior work is limited to producing isolated words, overlooking the inter-word relationships that define natural handwriting, such as vertical alignment and horizontal spacing. This narrow focus falls short for applications that require full text lines, where modeling both intra-word and inter-word style patterns and maintaining content accuracy across many characters pose significant challenges. The authors propose DiffBrush, a diffusion-based model that tackles these hurdles through content-decoupled style learning, which disentangles style from content using column- and row-wise masking to better capture comprehensive style patterns, and multi-scale content learning, which employs line-level and word-level discriminators to enforce global coherence and local textual fidelity.
Method
The authors propose DiffBrush, anovel conditional diffusion generation method designed to synthesize handwritten text lines with enhanced content accuracy and style fidelity. As shown in the figure below, the architecture comprises three main components: a content-decoupled style module, a conditional diffusion generator, and multi-scale content discriminators.
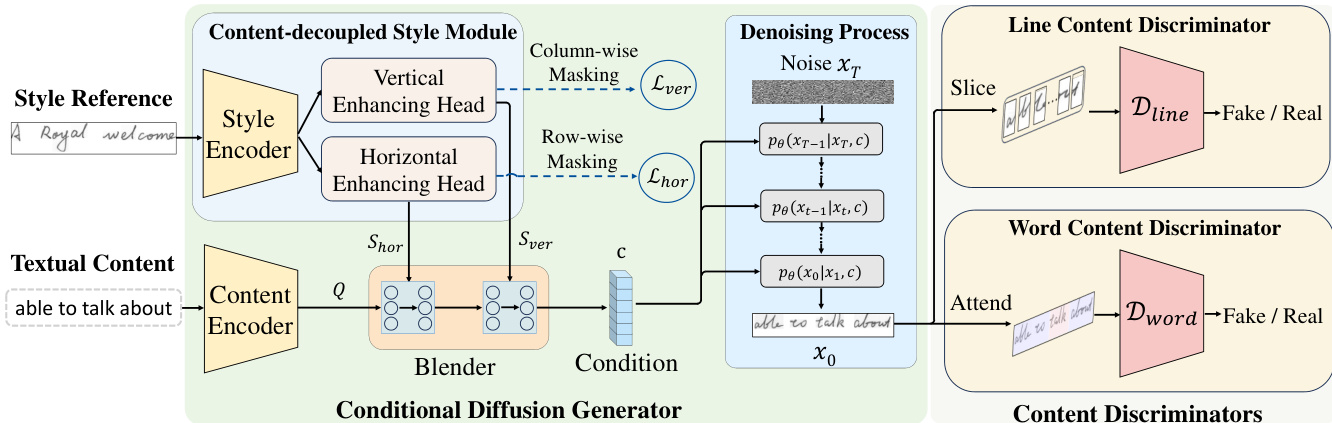
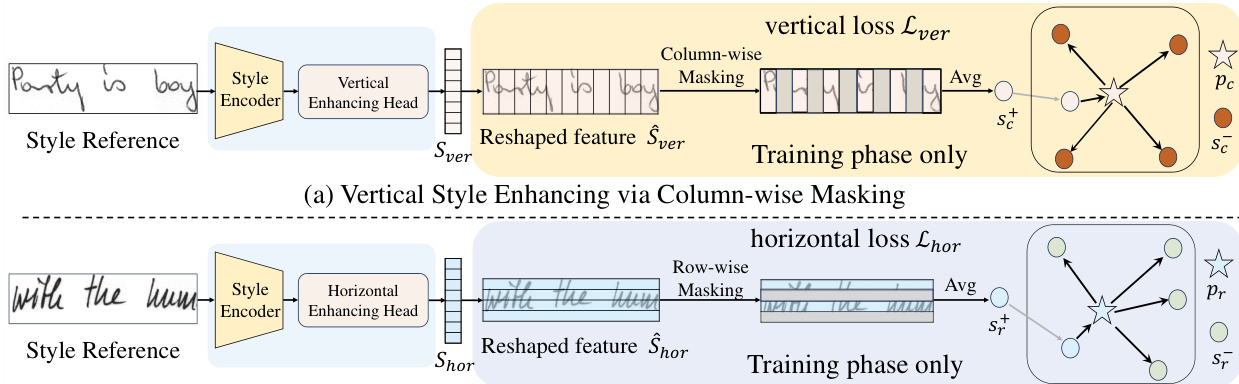
The content-decoupled style module aims to capture text-line styles from exemplar writers while eliminating content interference. The authors observe that naive random masking disrupts both content and key style features like word spacing and vertical alignment. To address this, they introduce column-wise and row-wise masking strategies, as illustrated in the figure below, which selectively disrupt content while preserving critical style patterns.

Specifically, style samples are processed by a CNN-Transformer style encoder to obtain an initial style feature. Two dedicated style-enhancing heads then extract fine-grained vertical and horizontal style features. As shown in the figure below, for vertical style enhancement, the sequential feature is reshaped into a spatial feature and subjected to column-wise masking. This maintains vertical alignment while removing horizontal content information. A Proxy-NCA loss is applied to enforce style consistency within writers while distinguishing different writers. Similarly, for horizontal style enhancement, row-wise masking is performed to preserve word and character spacing while disrupting vertical content. The overall content-decoupled style loss is the sum of the vertical and horizontal enhancing losses.
The extracted style features are fused with content features from a content encoder to form a condition vector, which guides the conditional diffusion generator in the denoising process to synthesize realistic handwritten text-line images. However, training the generator solely with diffusion loss is insufficient for content readability. To address this, the authors introduce a multi-scale content learning strategy that provides fine-grained content supervision at both global and local levels.
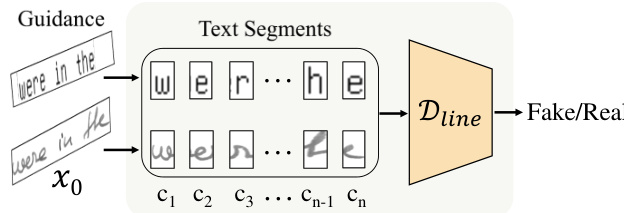
At the global level, a line content discriminator evaluates the overall character order. As shown in the figure below, the generated text-line image and content guidance are concatenated and sliced into segments. A 3D CNN-based discriminator processes these segments to incorporate global context information and determines whether the output is real or fake, providing feedback for the overall character order.
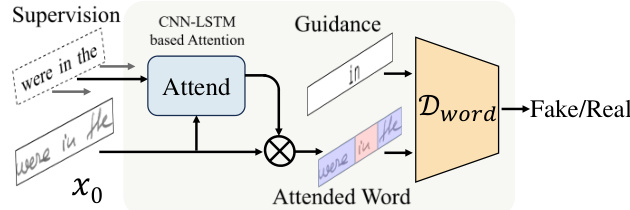
At the local level, a word content discriminator ensures character-level accuracy. As illustrated in the figure below, an attention module with a CNN-LSTM architecture is utilized to obtain word positions within the generated text line. The character-level attention maps are concatenated into word-level attention maps to extract attended words. Each attended word and its corresponding content guidance are fed into the word discriminator for realism discrimination, providing word-level content feedback for the generator.
The overall training objective of DiffBrush combines the diffusion loss, the content-decoupled style loss, and the multi-scale content loss:
LG=Ldiff+Lstyle+λLcontent,where λ serves as a trade-off factor, empirically set to 0.05 during training.
Experiment
Experiments evaluate DiffBrush on the IAM, CVL, and CASIA-HWDB datasets against state-of-the-art handwritten text-line and word-level generation methods using style similarity, content readability, and visual quality metrics, complemented by user studies. The results show that DiffBrush achieves superior style imitation and more accurate character content, with generated text-lines that are nearly indistinguishable from real handwriting. Ablation studies verify that the content‑decoupled style module with vertical and horizontal masking and the multi‑scale line and word discriminators together improve both style fidelity and readability, while additional analyses demonstrate robust generalization to complex backgrounds, Chinese scripts, direct line generation benefits, and smooth style interpolation.
The authors conduct an ablation study on the style module components, comparing a single style encoder against variants with vertical or horizontal enhancing heads. Results show that incorporating either enhancing head individually improves style imitation and content readability over the baseline. The full style module, which integrates both heads, achieves the best performance across all evaluation metrics, demonstrating its effectiveness in replicating reference writing styles while maintaining accurate content. The single style encoder baseline performs worst across style and content metrics compared to the enhanced variants. Incorporating either the vertical or horizontal enhancing head individually improves style imitation and content readability. The full style module combining both heads achieves the best overall performance in style replication and content accuracy.

The authors compare their directly generated text-line method, DiffBrush, against an assembled text-line approach using One-DM with post-processing. Results show that DiffBrush significantly outperforms the assembled baseline across all evaluated metrics, including style imitation, content readability, and visual quality. DiffBrush achieves lower Handwriting Distance scores, indicating superior style imitation compared to the assembled text-line method. The proposed method yields substantially lower character and word error rates, demonstrating better content readability. DiffBrush attains a much lower Fréchet Inception Distance, reflecting higher visual quality in the generated images.

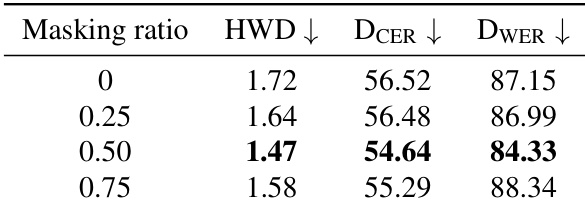
The authors analyze the effect of the masking ratio on the model's performance by evaluating different values on the IAM test set. Results show that a masking ratio of 0.5 yields the best performance across all evaluated metrics, including style similarity and content readability. Setting the ratio too low or too high leads to degraded performance in both style imitation and content accuracy. A masking ratio of 0.5 achieves the lowest Handwriting Distance, indicating superior style imitation compared to other tested ratios. This same ratio also results in the lowest character and word error rates, demonstrating optimal content readability. Performance degrades when the masking ratio is increased significantly or removed entirely, highlighting the importance of the masking strategy.
The authors compare their proposed DiffBrush method against state-of-the-art word-level generation approaches that utilize an assembling strategy to create text lines. The results demonstrate that directly generating text lines with DiffBrush yields superior performance across style imitation, content readability, and overall visual quality compared to concatenating isolated words. DiffBrush achieves the lowest Handwriting Distance score, indicating it most accurately imitates the reference handwriting style. The method significantly reduces character and word error rates, proving its advantage in maintaining content readability over assembling-based baselines. DiffBrush obtains the best Fréchet Inception Distance, reflecting the highest visual quality among the compared generation strategies.

The authors evaluate their method on Chinese handwritten text-line generation and compare it with a state-of-the-art baseline. The results demonstrate that their approach achieves superior performance in style imitation and content fidelity, effectively handling the complex structures of Chinese characters. The proposed method generates Chinese text-lines with more accurate character structures and better character spacing compared to the baseline. Quantitative evaluations show the method outperforms the baseline across style imitation, content accuracy, and visual quality metrics. Visual comparisons indicate the baseline occasionally produces incorrect character structures, whereas the proposed method preserves structural integrity.

The experiments validate the design of DiffBrush through ablation of the style module, showing that integrating both vertical and horizontal enhancing heads yields the best style imitation and content readability. Comparisons against assembled text-line baselines and word-level methods confirm that direct text-line generation consistently achieves superior handwriting style replication, lower error rates, and higher visual quality. A masking ratio of 0.5 proves optimal for balancing style and content, while evaluation on Chinese text lines demonstrates the method's ability to handle complex character structures with accurate spacing and structural integrity.