Command Palette
Search for a command to run...
Capybara-OMNI: Ein effizientes Paradigma für die Entwicklung von OMNI-MODAL Language Models
Capybara-OMNI: Ein effizientes Paradigma für die Entwicklung von OMNI-MODAL Language Models
Xingguang Ji Jiakang Wang Hongzhi Zhang Jingyuan Zhang Haonan Zhou Chenxi Sun Yahui Liu Qi Wang Fuzheng Zhang
Ein-Klick-Bereitstellung des einheitlichen visuellen Kreativmodells „Capybara"
Zusammenfassung
Mit der Weiterentwicklung von Multimodalen Large Language Models (MLLMs) sind in der Open-Source-Community zahlreiche herausragende Ergebnisse entstanden. Aufgrund der Komplexität bei der Erstellung und dem Training multimodaler Datenpaare bleibt der Aufbau leistungsfähiger MLMs jedoch ein rechenintensiver und zeitaufwändiger Prozess. In dieser Arbeit stellen wir Capybara-OMNI vor, ein MLM, das auf eine leichte und effiziente Weise trainiert wird und die Modalitäten Text, Bild, Video und Audio unterstützt. Wir erläutern detailliert das Framework-Design, den Aufbau der Daten sowie die Trainingsrezepte, um schrittweise ein MLM mit wettbewerbsfähiger Leistung zu entwickeln. Zudem stellen wir einen exklusiven Benchmark vor, der in unseren Experimenten verwendet wurde, um nachzuweisen, wie Verständnisfähigkeiten über verschiedene Modalitäten hinweg angemessen validiert werden können. Die Ergebnisse zeigen, dass sich durch die Befolgung unserer Anleitung effizient ein MLM entwickeln lässt, das auf verschiedenen multimodalen Benchmarks im Vergleich zu Modellen gleicher Skalierung wettbewerbsfähige Leistungen erzielt. Um darüber hinaus die Fähigkeiten des Modells zur Befolgung multimodaler Anweisungen und zur Konversation zu verbessern, diskutieren wir zusätzlich, wie eine Chat-Version auf Basis eines MLM-Verständnismodells trainiert werden kann, die besser mit den Benutzergewohnheiten für Aufgaben wie die Echtzeit-Interaktion mit Menschen übereinstimmt. Wir veröffentlichen das Capybara-OMNI-Modell sowie seine chat-basierte Version öffentlich.
One-sentence Summary
The authors introduce Capybara-OMNI, an efficient paradigm for building omni-modal language models that supports understanding text, image, video, and audio modalities through a lightweight training recipe, framework design, and data construction to achieve competitive performance among models of the same scale on various multimodal benchmarks, while publicly disclosing both the base model and a chat-based version for real-time interaction with humans.
Key Contributions
- This work introduces Capybara-OMNI, an omni-modal language model that supports text, image, video, and audio understanding through a lightweight and efficient training process.
- The paper details a framework design and training recipe that enhances instruction-following capabilities, enabling the development of a chat-based version for real-time interaction.
- Experimental results demonstrate competitive performance on various multimodal benchmarks, utilizing an exclusive benchmark provided to verify understanding capabilities across different modalities.
Introduction
Multimodal Large Language Models are critical for advancing human-computer interaction by enabling systems to process text, images, video, and audio simultaneously. Despite their potential, training these models remains computationally expensive due to the complexity of aligning diverse data modalities. Prior work often faces challenges with mutual interference where adding audio capabilities substantially degrades visual understanding without careful design. The authors introduce Capybara-OMNI to resolve these issues through a lightweight training paradigm that supports full-modality input. Their approach utilizes optimized data construction and training recipes to achieve competitive performance across modalities while significantly reducing resource requirements.
Method
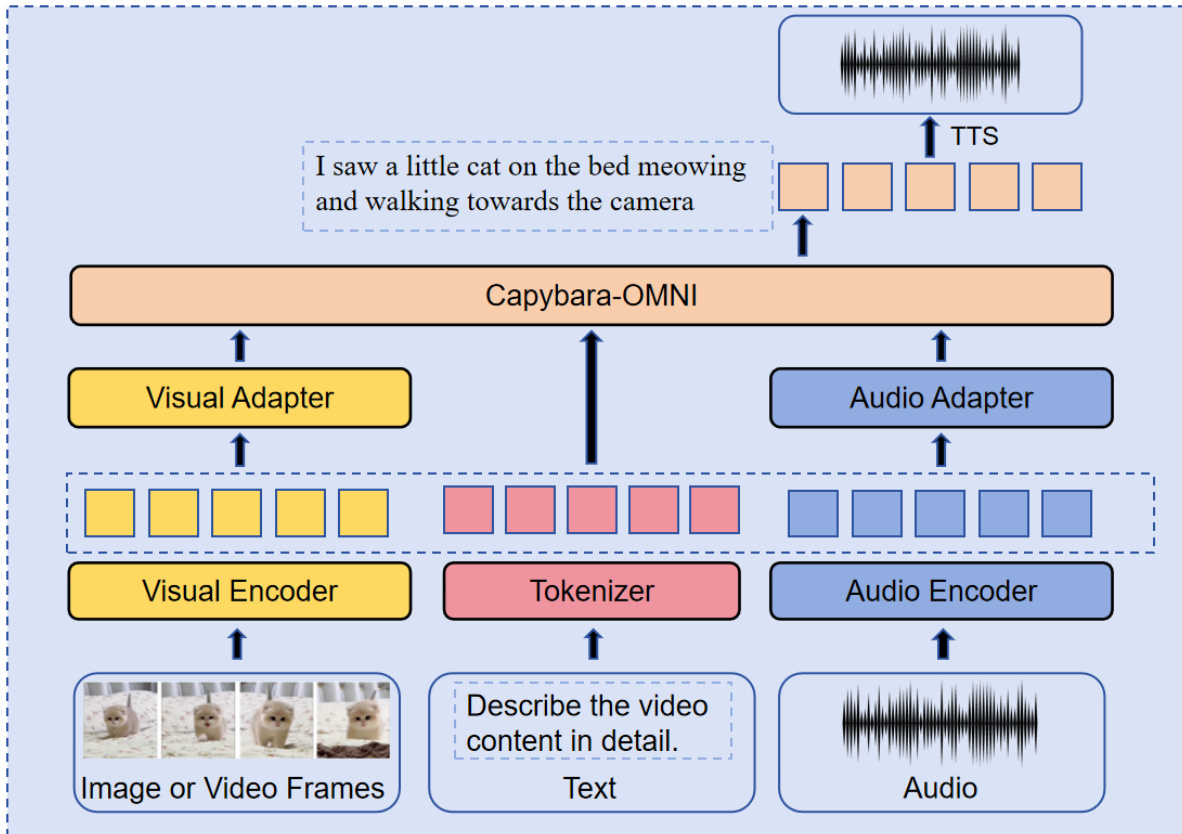
The authors construct the Capybara-OMNI model based on the Capybara-VL-7B architecture, integrating visual, audio, and text modalities into a unified framework. Refer to the framework diagram for the detailed system structure. The visual module employs a SigLIP vision encoder connected to the Large Language Model (LLM) via a two-layer MLP adapter. To accommodate variable aspect ratios and high-resolution images, the system interpolates position embeddings and segments images into sub-images, reducing visual tokens from 1024 to 256 through 2×2 bilinear interpolation. The audio module utilizes an encoder initialized from Whisper-large-v3, projecting audio features into the LLM space via a single-layer MLP. The core LLM is Qwen2.5-7B, which processes the unified token sequences.
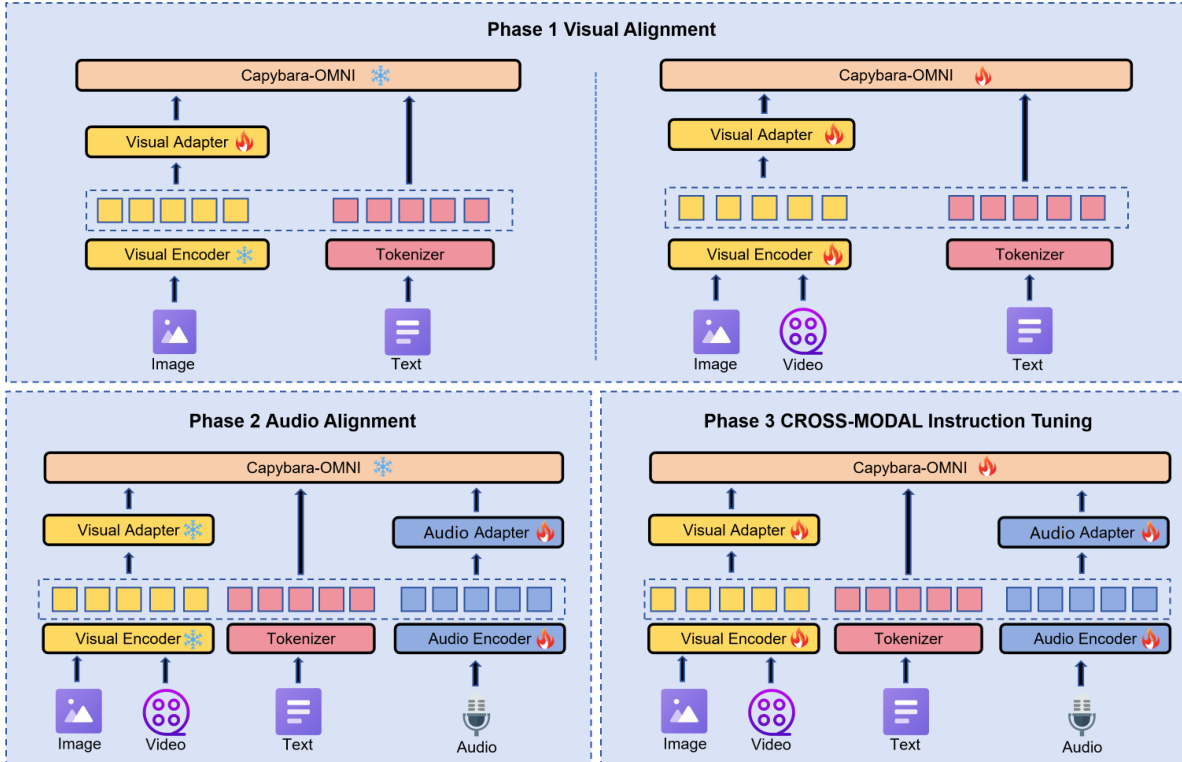
The training process is partitioned into three phases: visual alignment, audio alignment, and cross-modal instruction tuning. As shown in the figure below, the authors utilize specific freezing strategies in each phase to manage parameter updates effectively.
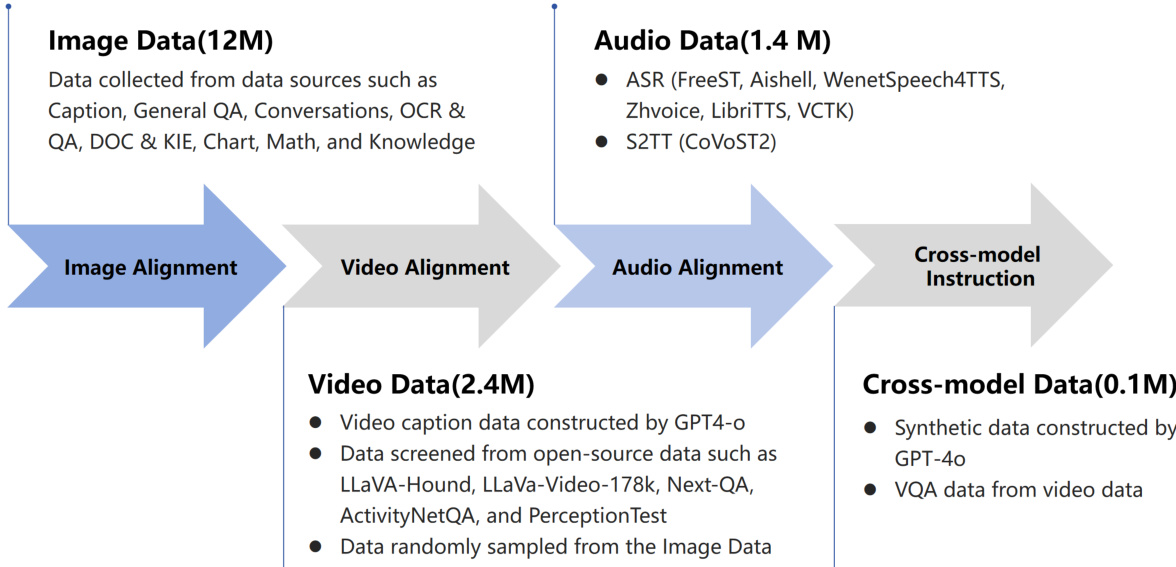
In the visual alignment phase, the model acquires image and video understanding capabilities. The training data construction process is illustrated in the figure below. The authors collect approximately 12 million image samples and 2.4 million video samples from diverse sources. This phase consists of three sub-stages. Initially, the LLM and vision encoder are frozen while the adapter is trained for coarse-grained alignment. Subsequent stages unfreeze all parameters to refine fine-grained visual concepts and handle high-resolution inputs split into up to nine sub-images.
During the audio alignment phase, the focus shifts to speech comprehension while preserving visual performance. Following the Freeze-Omni strategy, the LLM and visual components remain frozen. Only the audio encoder and adapter are trained on approximately 1.4 million ASR and S2TT data instances. This approach prevents catastrophic forgetting of the visual capabilities learned in the previous stage.
Finally, the cross-modal instruction tuning phase integrates all modalities for complex interaction. The authors generate synthetic data using GPT-4o and convert text-based VQA data into audio using Text-to-Speech (TTS). In this final stage, all model parameters are activated and updated to optimize cross-modal understanding and dialogue capabilities.
Experiment
Capybara-OMNI's multimodal understanding is evaluated across image, video, and audio tasks using standard open-source benchmarks to ensure realistic comparisons. The model demonstrates competitive performance in visual domains, frequently surpassing larger open-source models and rivaling closed-source systems, while video results underscore the efficacy of its training strategies in retaining capabilities. Additionally, audio experiments confirm strong performance against specialized models, with ablation studies validating that high-quality encoder initialization and data screening significantly improve audio understanding.
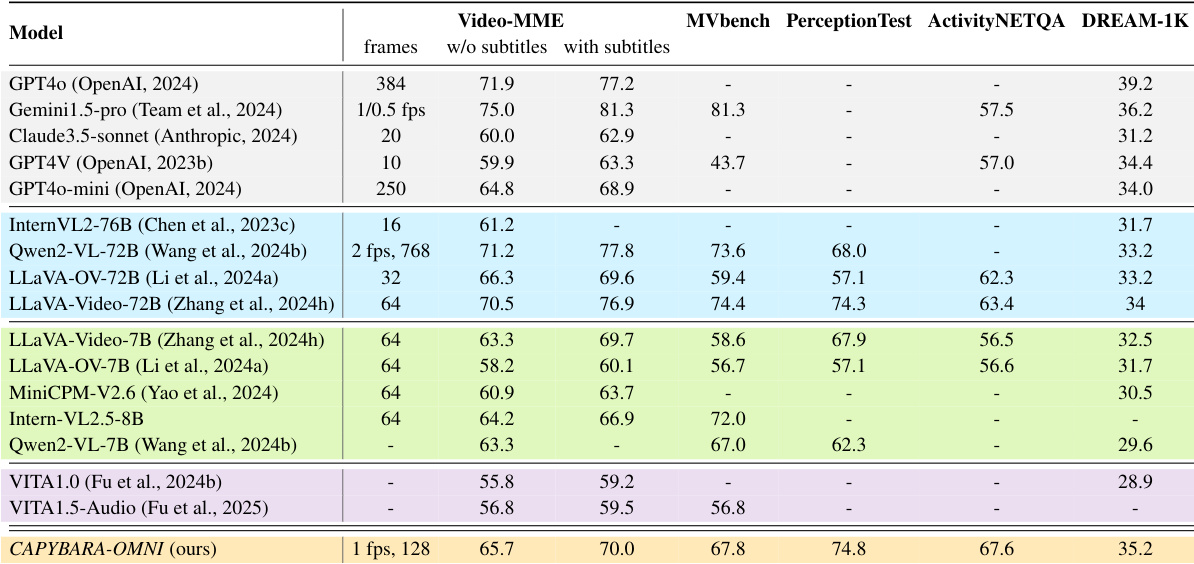
The the the table compares Capybara-OMNI against various private and open-source models across multiple video understanding benchmarks. Results indicate that the proposed model achieves competitive performance, frequently surpassing similarly sized open-source models and previous omni architectures. Capybara-OMNI outperforms comparable open-source models on Video-MME and MVbench. The model achieves superior scores on PerceptionTest compared to larger 72B models. Performance exceeds previous omni models like VITA1.5 across all listed metrics.
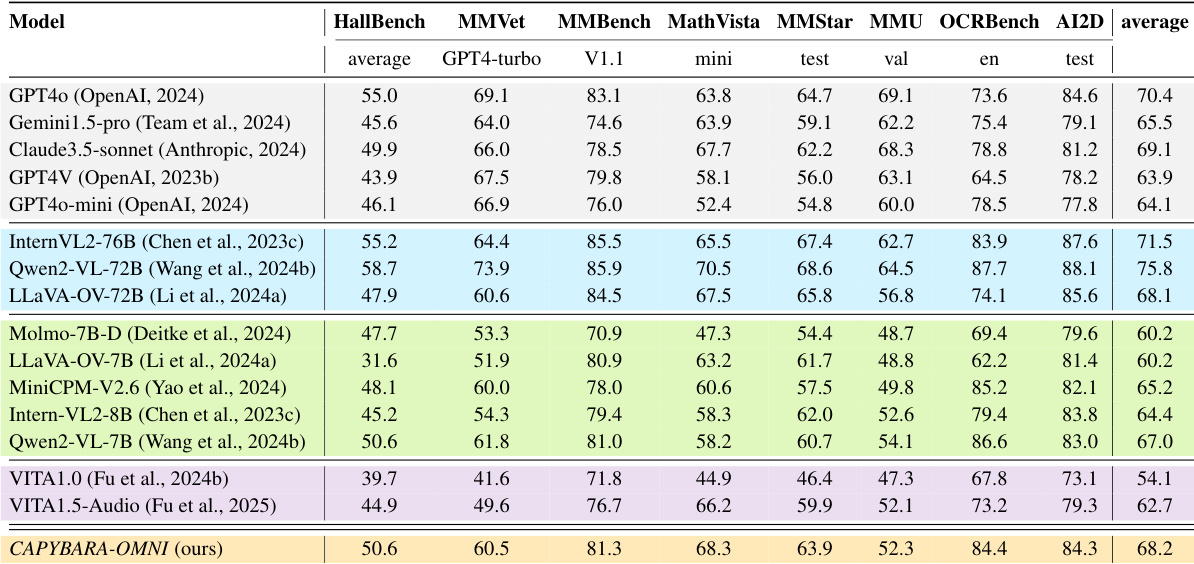
The the the table compares Capybara-OMNI against various private and open-source vision-language models across eight diverse benchmarks. Results indicate that the proposed model achieves competitive average performance, notably surpassing several larger open-source models and closed-source baselines. It demonstrates particular strength in scientific diagram understanding and mathematical reasoning, often matching the performance of significantly larger parameter models. Capybara-OMNI outperforms GPT4o-mini and LLaVA-OV-72B in overall average score. The model achieves top-tier results on AI2D and MathVista benchmarks. Performance remains competitive against much larger 72B and 76B parameter models.
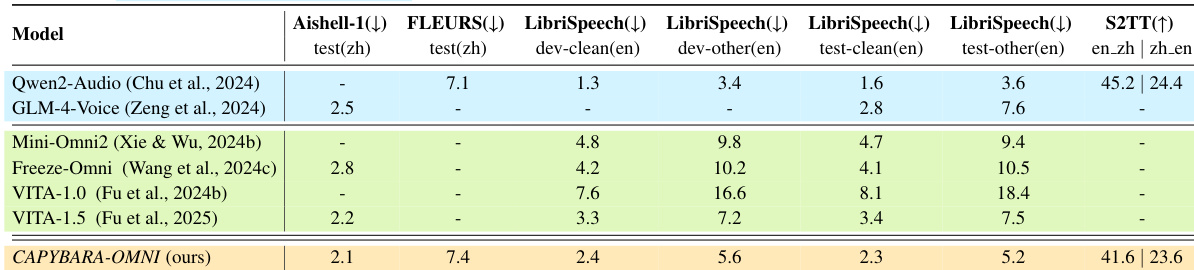
The the the table evaluates audio understanding capabilities across Chinese and English ASR tasks and speech-to-text translation. Capybara-OMNI demonstrates competitive performance, particularly in Chinese ASR where it outperforms specialized models like GLM-4-Voice. While slightly trailing behind the initialization model Qwen2-Audio, it surpasses other open-source omni models in several English benchmarks. Capybara-OMNI achieves top-tier performance on the Aishell-1 Chinese ASR benchmark. The model outperforms other omni competitors like VITA-1.5 on English LibriSpeech tasks. Results indicate strong competitiveness in speech-to-text translation compared to open-source alternatives.
The the the table illustrates the progressive enhancement of audio understanding capabilities through specific architectural and data modifications. Initializing the model with the Qwen2-Audio encoder yields substantial performance gains over the baseline. Further improvements are observed after applying data augmentation, which lowers error rates across multiple benchmarks. Initializing with Qwen2-Audio encoder yields substantial improvements over the baseline. Data augmentation further enhances audio capabilities across all tested benchmarks. The final configuration achieves the best performance on both ASR and translation tasks.

The experiments evaluate Capybara-OMNI across video, image, and audio understanding benchmarks against a range of private and open-source baselines. Results indicate the model achieves competitive performance in video and image tasks, often surpassing similarly sized open-source architectures and matching larger models in scientific and mathematical reasoning. Audio assessments show strong capabilities in speech recognition and translation, while ablation studies validate that initializing with a specialized encoder and applying data augmentation significantly enhance these features.