Command Palette
Search for a command to run...
PE3R: perceptionseffiziente 3D-Rekonstruktion
PE3R: perceptionseffiziente 3D-Rekonstruktion
Jie Hu Shizun Wang Xinchao Wang
PE3R: Ein Framework für effiziente 3D-Rekonstruktion
Zusammenfassung
Neuere Fortschritte in der 2D-zu-3D-Wahrnehmung haben die Interpretation von 3D-Szenen aus 2D-Bildern erheblich verbessert. Dennoch stehen bestehende Methoden vor kritischen Herausforderungen, darunter begrenzte Generalisierbarkeit über Szenen hinweg, suboptimale Wahrnehmungsgenauigkeit und langsame Rekonstruktionsgeschwindigkeiten. Um diese Einschränkungen zu überwinden, stellen wir PE3R (Perception-Efficient 3D Reconstruction) vor – einen neuartigen Ansatz, der darauf abzielt, sowohl Genauigkeit als auch Effizienz zu steigern. PE3R nutzt eine feed-forward-Architektur, um eine schnelle Rekonstruktion von 3D-Semantikfeldern zu ermöglichen. Das Framework zeigt eine robuste Zero-Shot-Generalisierung über vielfältige Szenen und Objekte hinweg und verbessert gleichzeitig deutlich die Rekonstruktionsgeschwindigkeit. Umfangreiche Experimente im Bereich der 2D-zu-3D-open-vocabulary-Segmentierung und 3D-Rekonstruktion bestätigen die Wirksamkeit und Vielseitigkeit von PE3R. Das Verfahren erreicht eine Mindestbeschleunigung um den Faktor 9 bei der Rekonstruktion von 3D-Semantikfeldern, gleichzeitig mit erheblichen Verbesserungen hinsichtlich Wahrnehmungsgenauigkeit und Rekonstruktionspräzision, wodurch neue Maßstäbe in der Forschungslandschaft gesetzt werden. Der Quellcode ist öffentlich verfügbar unter: https://github.com/hujiecpp/PE3R.
One-sentence Summary
The authors propose PE3R, a feed-forward framework for perception-efficient 3D reconstruction that achieves zero-shot generalization and up to 9-fold speedup by operating solely on 2D images without requiring 3D data, enabling fast, accurate, and scalable semantic scene reconstruction for real-time and large-scale applications.
Key Contributions
- Existing 2D-to-3D reconstruction methods struggle with poor generalization, low accuracy, and slow speeds due to reliance on scene-specific training and explicit 3D data like camera poses or depth, limiting their scalability and real-time applicability.
- PE3R introduces a feed-forward architecture with three key modules—pixel embedding disambiguation, semantic field reconstruction, and global view perception—that enable zero-shot generalization and efficient 3D semantic reconstruction using only 2D images and language guidance.
- Experiments on datasets including Mipnerf360, Replica, ScanNet, and KITTI demonstrate PE3R achieves at least a 9-fold speedup in reconstruction while significantly improving segmentation accuracy and reconstruction precision, setting new benchmarks in the field.
Introduction
The authors address the challenge of reconstructing semantically rich 3D scenes from unstructured 2D images without relying on 3D annotations, camera calibration, or depth data—common bottlenecks in real-world applications like robotics, autonomous driving, and augmented reality. Prior methods, while effective, often depend on scene-specific training, suffer from slow reconstruction speeds due to iterative optimization (e.g., NeRF, 3DGS), and struggle with generalization across diverse scenes. To overcome these limitations, the authors propose PE3R, a feed-forward framework that achieves perception-efficient 3D reconstruction by integrating three key components: pixel embedding disambiguation for cross-view semantic consistency, semantic field reconstruction that embeds semantics directly into the 3D representation, and global view perception for text-guided, holistic scene understanding. The result is a system that enables zero-shot generalization, supports natural language queries, and delivers a minimum 9-fold speedup over prior approaches while improving accuracy and precision, establishing a new benchmark for efficient 2D-to-3D perception.
Dataset
- The dataset comprises three primary components: Mipnerf360 (extended with open-vocabulary capabilities via Qu et al., 2024), Replica (Straub et al., 2019), and ScanNet++ (Yeshwanth et al., 2023), used for 2D-to-3D open-vocabulary segmentation.
- Mipnerf360 and Replica provide diverse indoor scenes with 3D scene reconstructions and associated 2D image annotations, while ScanNet++ is used for large-scale generalization evaluation.
- For 3D reconstruction, the model is trained and evaluated on multi-view depth estimation datasets: KITTI (outdoor urban scenes), ScanNet (indoor environments), DTU (structured indoor scenes), ETH3D (mixed indoor/outdoor), and Tanks and Temples (varied real-world scenes).
- The training split combines data from Mipnerf360, Replica, and ScanNet++ using a mixture ratio that balances scene diversity and object coverage, with each subset filtered to ensure consistent resolution and annotation quality.
- The authors apply a cropping strategy to focus on object-centric regions during training, particularly for segmentation tasks, to improve localization accuracy.
- Metadata is constructed by aligning 2D image labels with 3D scene coordinates using pre-trained 3D reconstruction pipelines, enabling cross-modal semantic mapping.
- The model leverages pre-trained components: MobileSAMv2 for lightweight 2D segmentation, SAM2 for object tracking, and DUSt3R for feed-forward depth prediction, all integrated into the training and inference pipeline.
- Evaluation uses mIoU, mPA, and mP for segmentation, and Absolute Relative Error (rel) and Inlier Ratio (τ = 1.03) for depth estimation, reported per dataset and averaged across all test sets.
Method
The authors present PE3R, an efficient feed-forward framework for 2D-to-3D semantic reconstruction, which operates through a modular pipeline designed to address key challenges in semantic understanding and spatial alignment. The overall framework begins with multi-view 2D images as input, which are processed through three primary modules: Pixel Embedding Disambiguation, Semantic Field Reconstruction, and Global View Perception. These modules are sequentially connected to generate a coherent 3D semantic field from the input images.
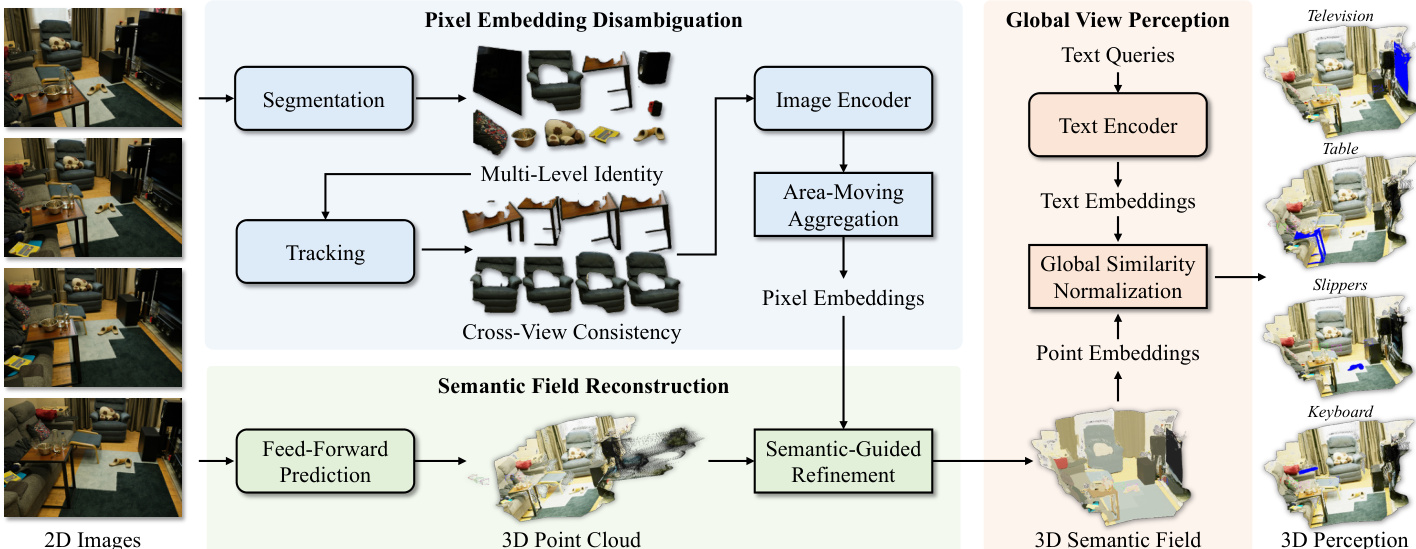
Refer to the framework diagram for an overview of the system architecture. The first module, Pixel Embedding Disambiguation, addresses semantic ambiguities arising from object-level overlaps and perspective inconsistencies. It starts by segmenting and tracking objects across all input views using foundational segmentation models, such as SAM1 and SAM2, to generate consistent multi-level masks. These masks are then used to extract image embeddings via an image encoder, such as CLIP, producing embeddings that are normalized using L2 normalization. To ensure cross-view consistency and resolve ambiguities, the framework employs an area-moving aggregation technique. This method constructs spherical unit vectors to combine embeddings from different views, where the interpolation parameter is determined by the area ratio of the corresponding objects. The aggregation process is designed to preserve vector normalization and effectively integrate semantic information, as proven by the authors through mathematical analysis. The resulting embeddings are then assigned to pixels in the original images, forming pixel embeddings that are both object-distinguishable and view-consistent.
The second module, Semantic Field Reconstruction, leverages feed-forward predictors, such as DUST3R, to estimate spatial coordinates for each pixel across all views, generating initial point maps. However, these predictions often contain noise due to scene complexities like reflections and occlusions. To mitigate this, the framework introduces an anomaly detection step that computes the average 3D distance between each pixel and its neighbors within the same semantic category. Pixels with distances exceeding a predefined threshold are identified as anomalies. These noisy points are then refined by smoothing the input images using their semantic masks, replacing the RGB values of anomaly pixels with the mean RGB of their corresponding semantic region. This semantic-guided refinement produces more accurate point maps, which are subsequently aligned globally to form a consistent 3D point cloud.
The final module, Global View Perception, enables open-vocabulary semantic understanding by processing the refined point embeddings alongside a given text query. The text query is encoded into a text embedding using a text encoder, such as CLIP. The cosine similarity between the text embedding and the point embeddings is computed, and the resulting similarity scores are globally normalized using min-max normalization. A similarity threshold is then applied to identify points in the 3D point cloud that semantically match the input text, enabling the system to perform 3D perception tasks such as object localization and segmentation. This modular design ensures that each component contributes to the overall goal of efficient and accurate 2D-to-3D semantic reconstruction.
Experiment
- 2D-to-3D open-vocabulary segmentation: PE3R outperforms GOI on Mipnerf360 and Replica across mIoU, mPA, and mP, and achieves a 9x speedup in semantic field construction (5 minutes vs. 43–45 minutes for LERF and GOI). On ScanNet++, PE3R shows competitive performance, demonstrating strong generalization. Visualizations confirm robustness across diverse scenes and object semantics.
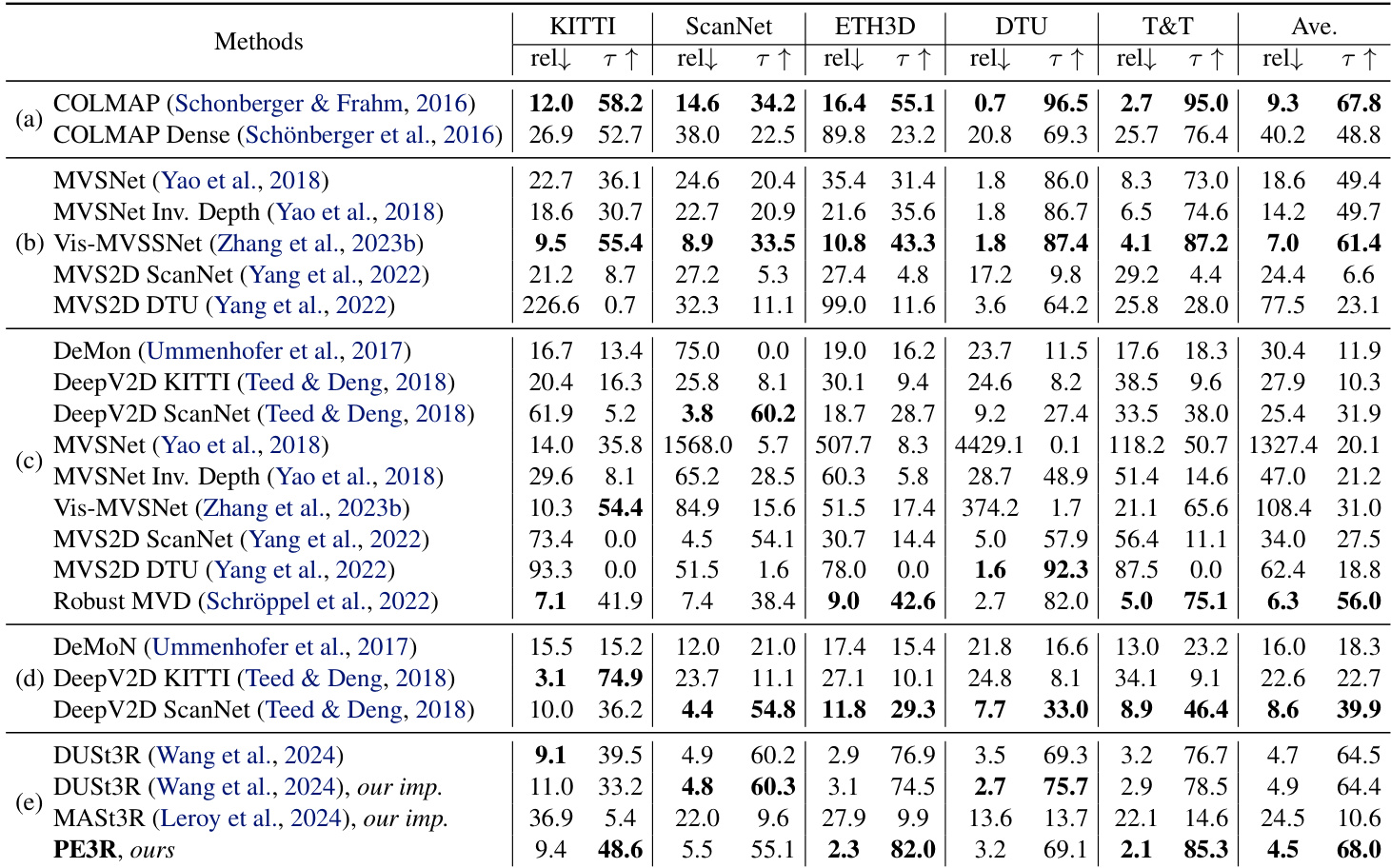
- Multi-view depth estimation: PE3R surpasses DUST3R and MAS3R on most datasets, achieving the highest average performance, highlighting its effectiveness in 3D reconstruction without relying on 3D priors.
- Ablation studies: Multi-level disambiguation preserves fine-grained and composite object semantics; cross-view disambiguation mitigates perspective and occlusion issues; global min-max normalization reduces noise. Semantic field reconstruction improves depth estimation under challenging conditions with minimal time overhead.
The authors use PE3R to evaluate 2D-to-3D open-vocabulary segmentation on Mipnerf360 and Replica datasets, showing that their method outperforms state-of-the-art approaches across all metrics, including mIoU, mPA, and mP. Results show PE3R achieves the highest scores on both datasets, with 0.8951 mIoU and 0.9617 mPA on Mipnerf360, and 0.6531 mIoU and 0.8377 mPA on Replica.
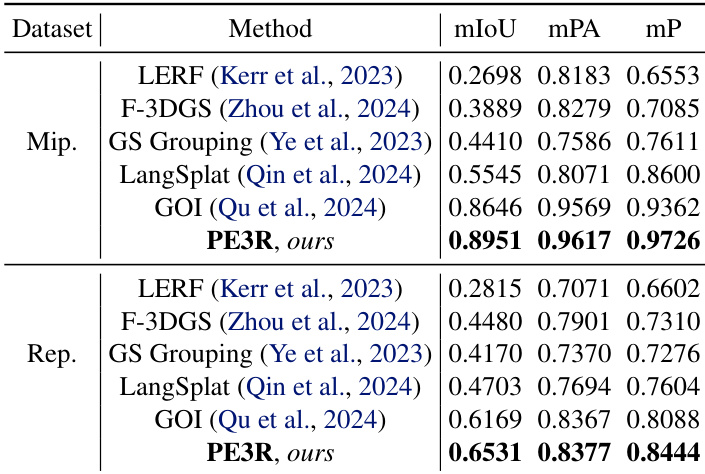
Results show that PE3R outperforms the state-of-the-art methods LERF and GOI across all metrics—mIoU, mPA, and mP—on the Mipnerf360 and Replica datasets. The authors use this table to demonstrate that their method achieves higher segmentation accuracy while also being significantly faster in constructing 3D semantic fields.

Results show that semantic field reconstruction significantly improves performance, reducing the relative error from 5.3 to 4.5 and increasing the τ score from 60.2 to 68.0, while only slightly increasing the run time from 10.4021s to 11.1934s. The authors use this ablation study to demonstrate that incorporating semantic field reconstruction enhances robustness in challenging conditions such as transparency and occlusion.

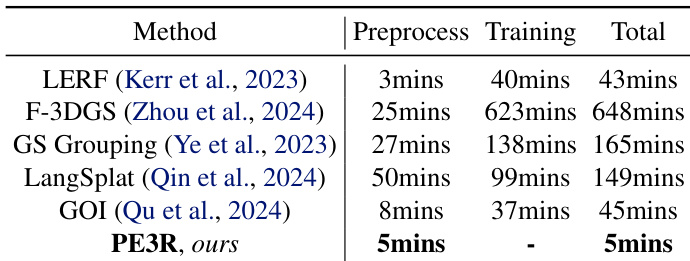
The authors use Table 2 to compare the time efficiency of different methods for constructing 3D semantic fields. Results show that PE3R completes the process in 5 minutes, which is significantly faster than the next fastest method, GOI, at 45 minutes, making it approximately nine times faster.
The authors use the table to compare the performance of various methods on multi-view depth estimation tasks across multiple datasets. Results show that PE3R achieves the highest average performance, outperforming baseline methods such as DUST3R and MAS3R on most datasets, particularly in terms of relative and absolute error metrics.