Command Palette
Search for a command to run...
Demo Des Pusa-VidGen-Videogenerierungsmodells
Datum
Paper-URL
Lizenz
Apache 2.0
GitHub
1. Einführung in das Tutorial

Pusa V1, am 25. Juli 2025 vom Team um Yaofang-Liu vorgestellt, ist ein hocheffizientes multimodales Videogenerierungsmodell. Basierend auf der Vectorized Temporal Adaptation (VTA)-Technologie löst es die Kernprobleme traditioneller Videogenerierungsmodelle: hohe Trainingskosten, geringe Inferenzeffizienz und mangelnde zeitliche Konsistenz. Im Gegensatz zu herkömmlichen Methoden, die auf große Datenmengen und hohe Rechenleistung angewiesen sind, erzielt Pusa V1 durch eine ressourcenschonende Feinabstimmungsstrategie bahnbrechende Optimierungen auf Basis von Wan2.1-T2V-14B: Die Trainingskosten betragen lediglich 500 US-Dollar (nur 1/200 vergleichbarer Modelle), der Datensatz benötigt nur 4.000 Samples (nur 1/2500 vergleichbarer Modelle), und das Training kann auf acht 80-GB-GPUs durchgeführt werden. Dadurch wird die Anwendungsschwelle für Videogenerierungstechnologien deutlich gesenkt. Gleichzeitig verfügt es über leistungsstarke Multitasking-Fähigkeiten und unterstützt neben textgesteuertem Video (T2V) und bildgesteuertem Video (I2V) auch Zero-Shot-Aufgaben wie Videovervollständigung, Generierung des ersten und letzten Frames sowie Szenenübergänge, ohne dass zusätzliches Training für spezifische Szenen erforderlich ist. Besonders hervorzuheben ist seine herausragende Generierungsleistung. Durch den Einsatz einer Kurzschritt-Inferenzstrategie (die das Basismodell in nur 10 Schritten übertrifft) erreichte es auf der VBench-I2V-Plattform eine Gesamtpunktzahl von 87,32% und demonstrierte damit eine exzellente Leistung bei der Wiedergabe dynamischer Details (wie Gliedmaßenbewegungen und Lichtveränderungen) sowie bei der zeitlichen Kohärenz. Darüber hinaus integriert der durch die VTA-Technologie implementierte nicht-destruktive Anpassungsmechanismus zeitliche Dynamikfähigkeiten in das Basismodell, während die Bildgenerierungsqualität des ursprünglichen Modells erhalten bleibt, wodurch ein „1+1>2“-Effekt erzielt wird. Auf der Ebene des Einsatzes erfüllt die geringe Latenzzeit bei der Inferenz vielfältige Anforderungen, von der schnellen Vorschau bis zur hochauflösenden Ausgabe, und macht es somit geeignet für kreatives Design, Kurzvideoproduktion und andere Anwendungsbereiche. Ergebnisse der zugehörigen Veröffentlichung sind... PUSA V1.0: Übertreffen von Wan-I2V bei den $500-Trainingskosten durch vektorisierte Zeitschrittanpassung .
Dieses Tutorial verwendet Dual-Card-RTX-A6000-Ressourcen.
2. Projektbeispiele
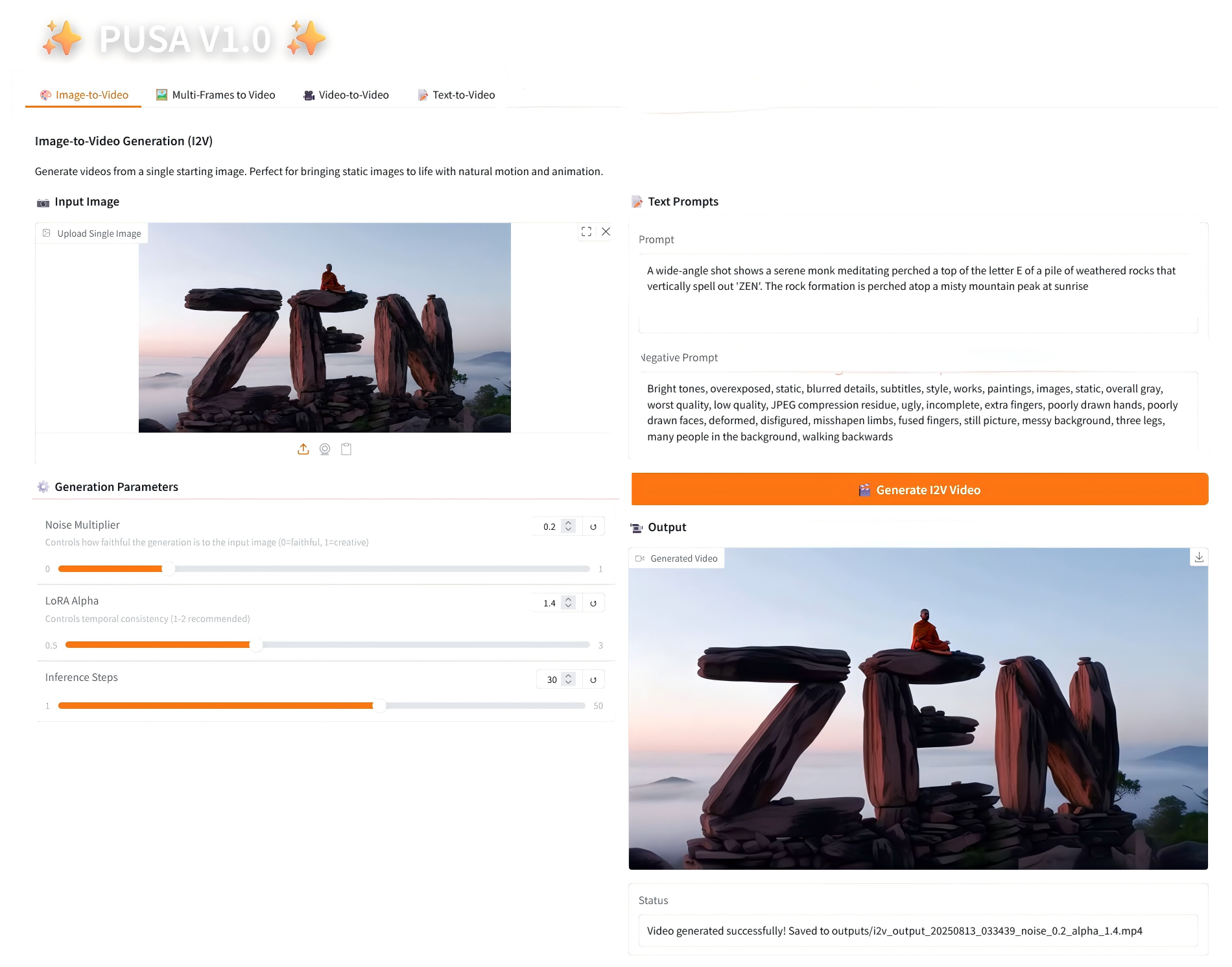
1. Bild-zu-Video
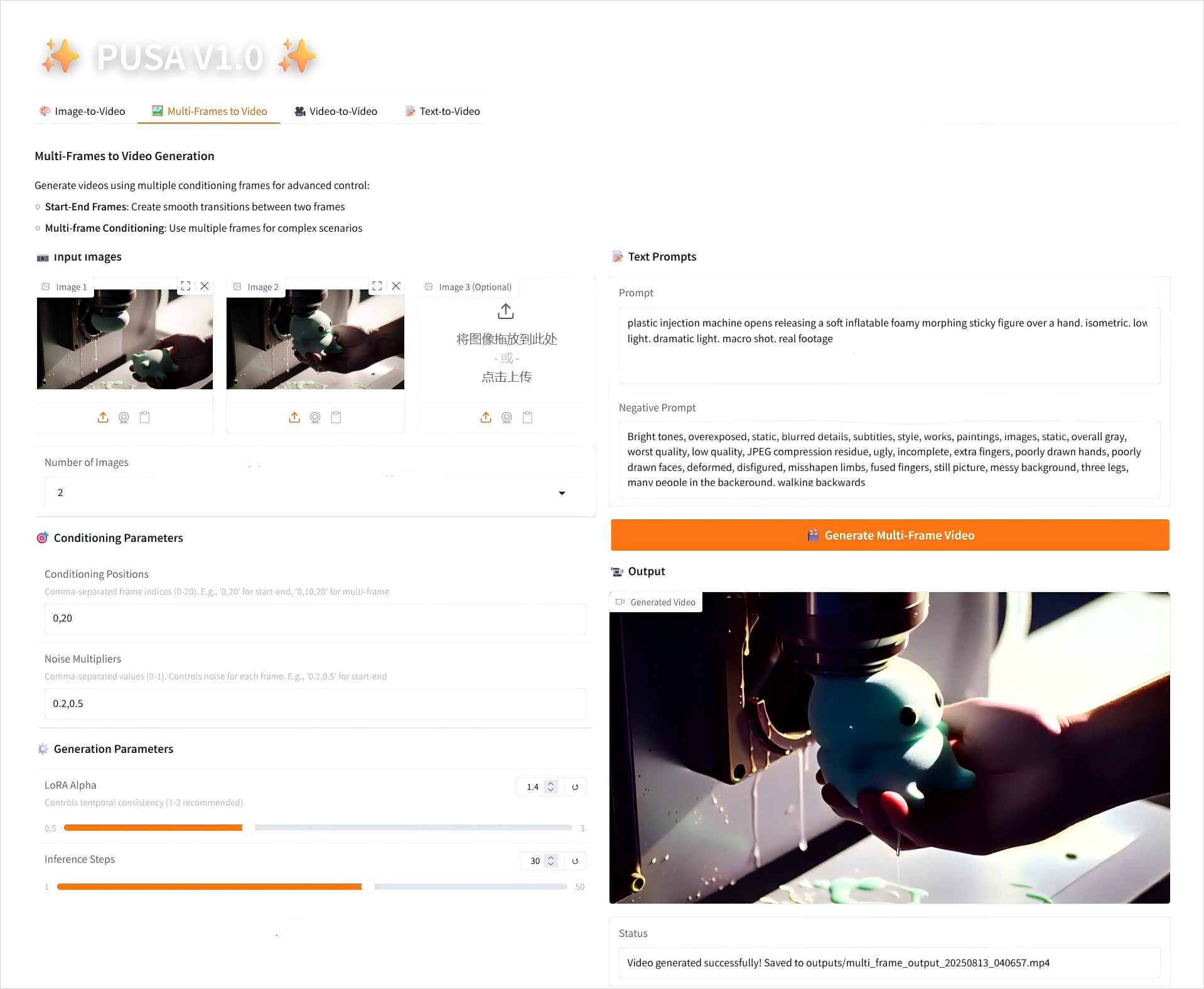
2. Mehrere Frames zu Video
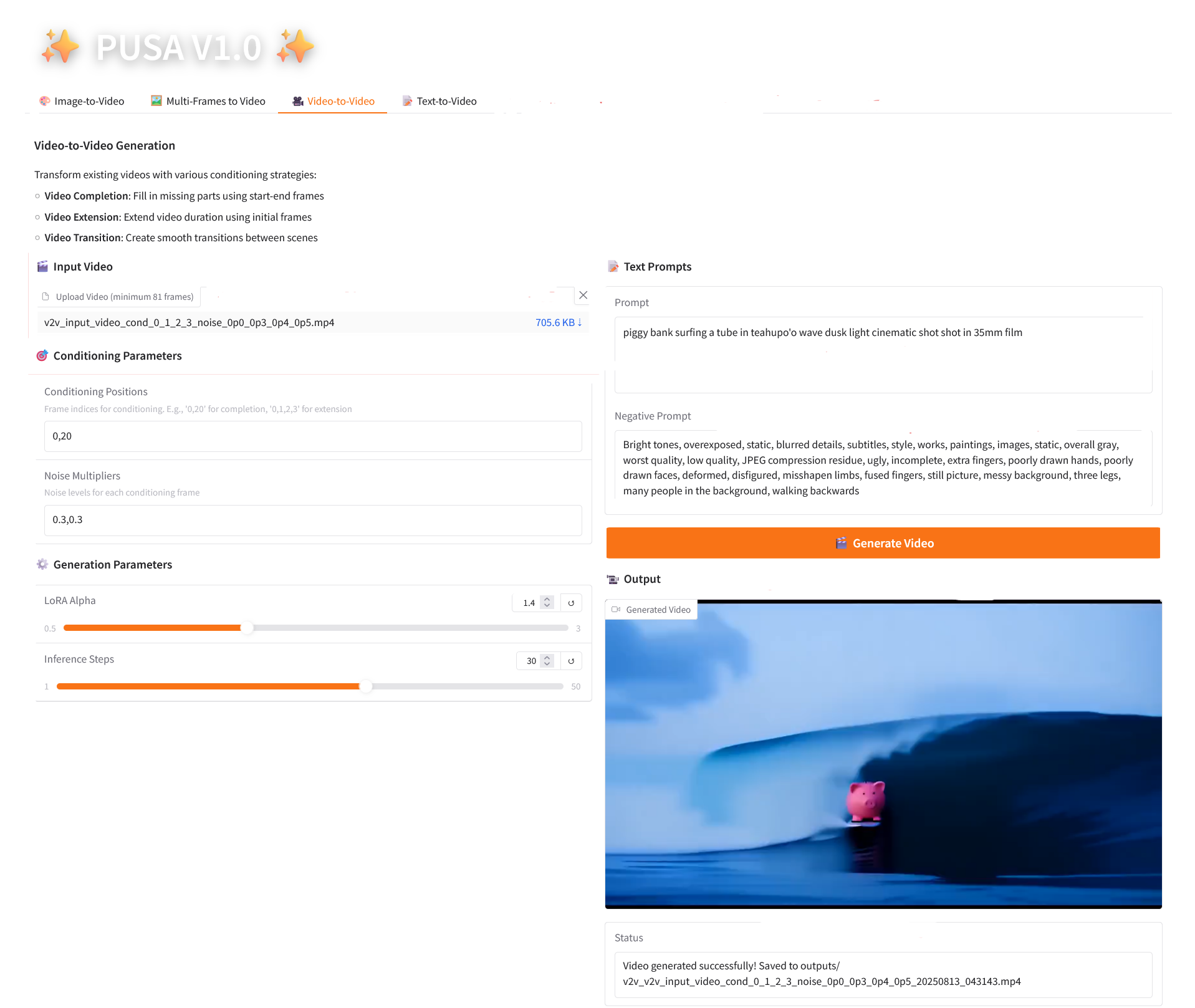
3. Video-zu-Video
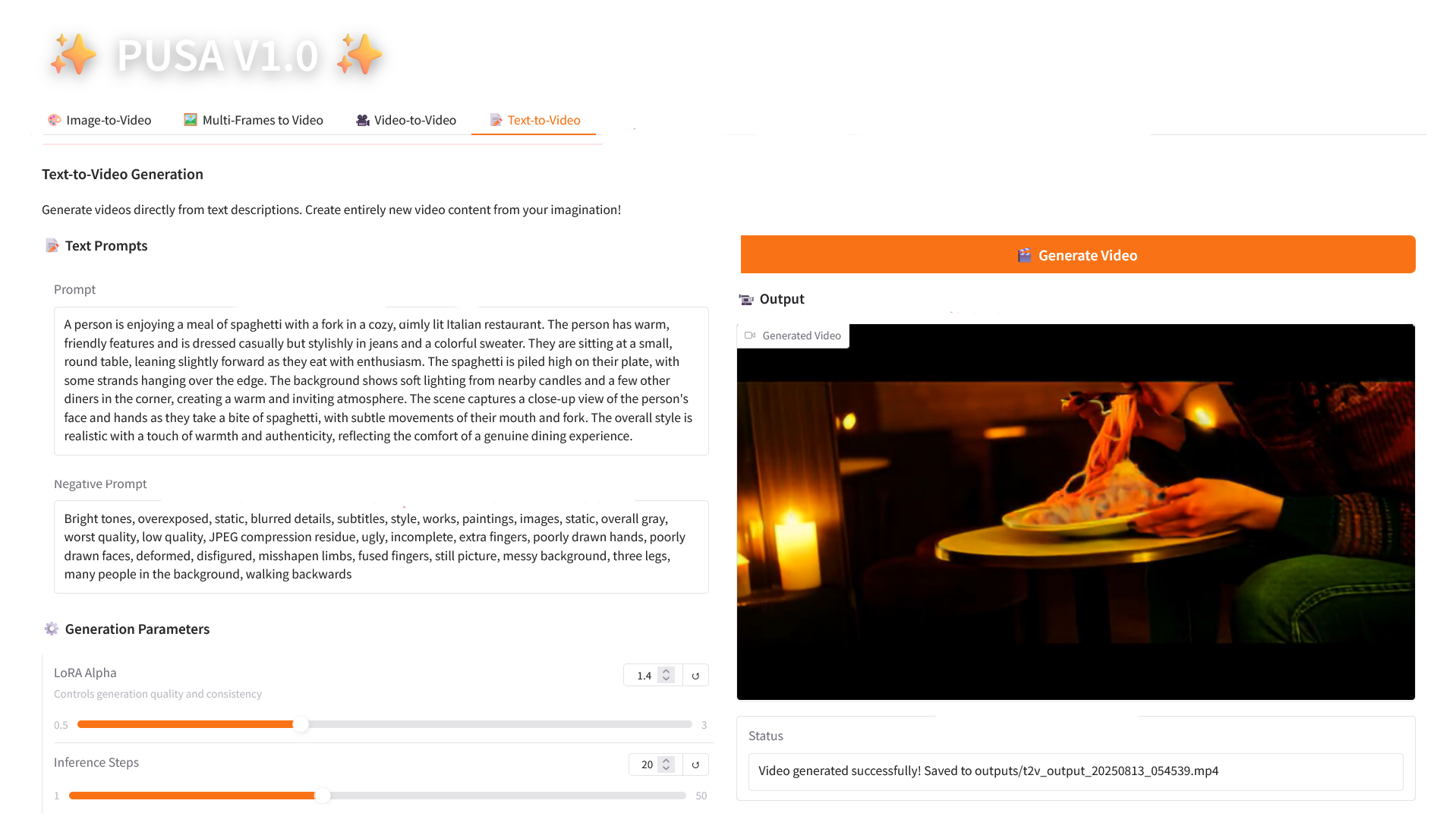
4. Text-zu-Video
3. Bedienungsschritte
1. Klicken Sie nach dem Starten des Containers auf die API-Adresse, um die Weboberfläche aufzurufen
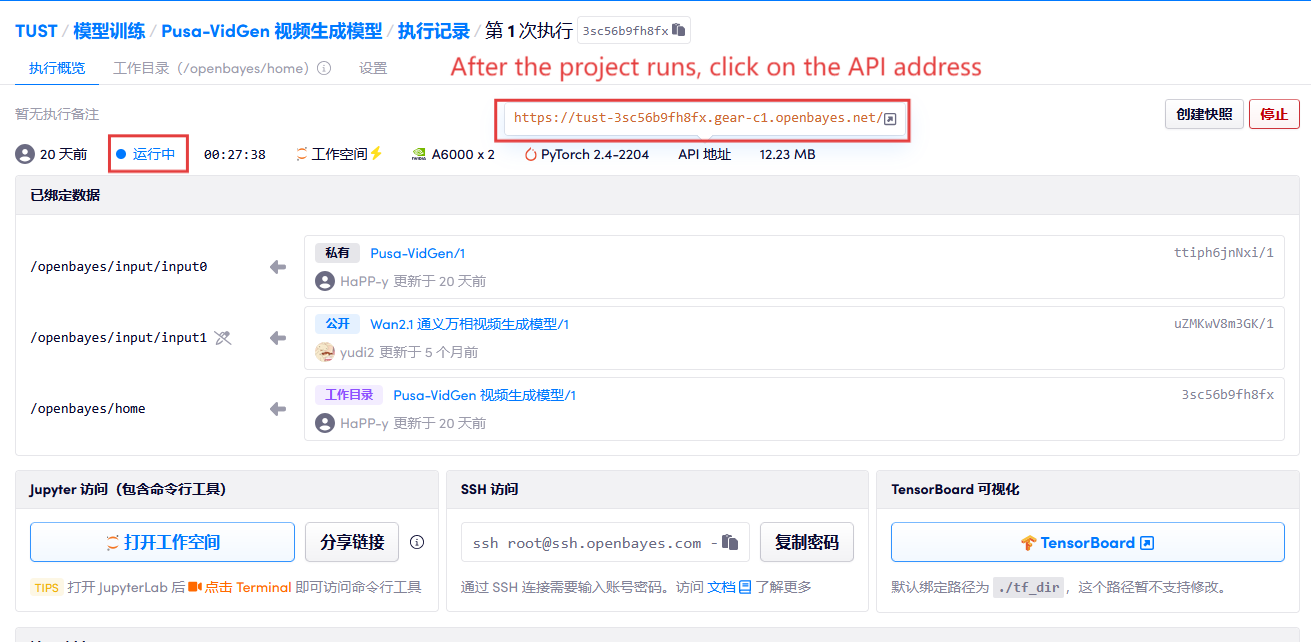
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
2.1 Bild-zu-Video
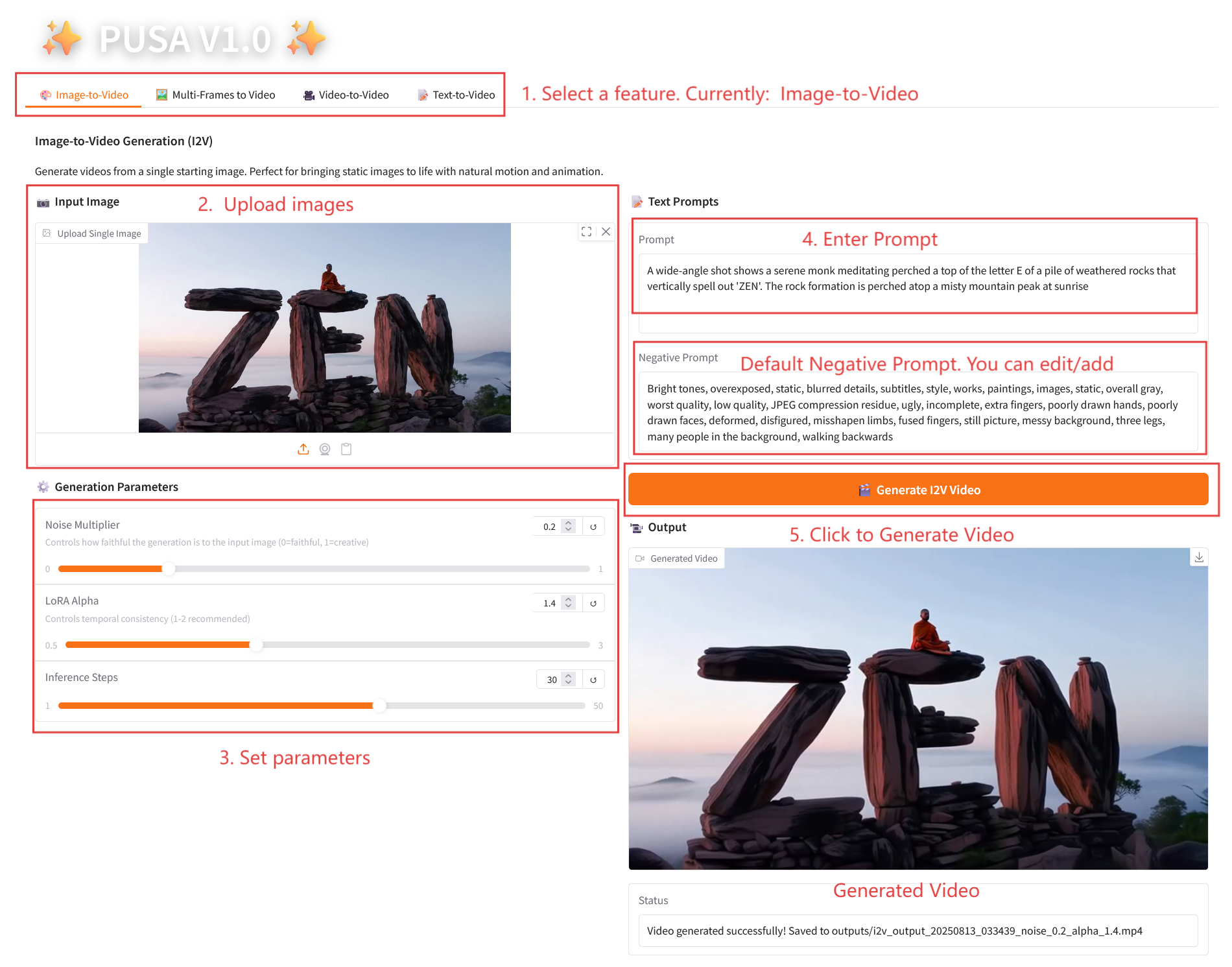
Parameterbeschreibung
- Generierungsparameter
- Rauschmultiplikator: Einstellbar von 0,0 bis 1,0, Standard 0,2 (niedrigere Werte entsprechen dem Eingabebild getreuer, höhere Werte sind kreativer).
- LoRA Alpha: 0,1–5,0 einstellbar, Standard 1,4 (steuert die Stilkonsistenz, zu hoch und es wird steif, zu niedrig und es verliert an Kohärenz).
- Inferenzschritte: Einstellbar von 1 bis 50, Standard ist 10 (je höher die Anzahl der Schritte, desto detaillierter die Ergebnisse, aber der Zeitaufwand steigt linear an).
2.2 Multiframes zu Video
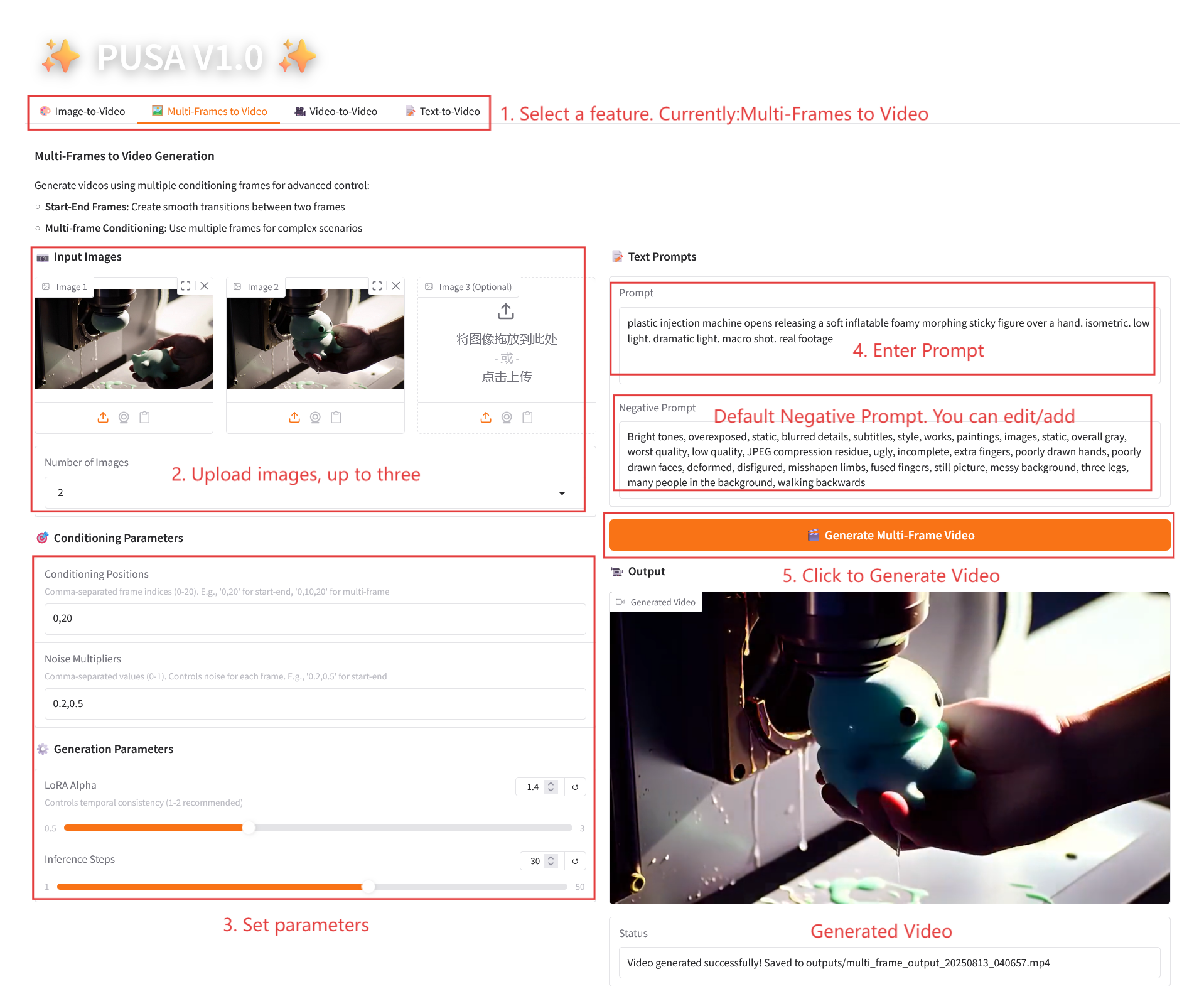
Parameterbeschreibung
- Konditionierungsparameter
- Konditionierungspositionen: Durch Kommas getrennte Frame-Indizes (z. B. definiert „0,20“ die Zeitpunkte der Keyframes im Video).
- Rauschmultiplikatoren: Durch Komma getrennte Werte von 0,0–1,0 (z. B. „0,2,0,5“, entsprechend der kreativen Freiheit jedes Keyframes, niedrigere Werte sind dem Frame treuer, höhere Werte sind abwechslungsreicher).
- Generierungsparameter
- LoRA Alpha: 0,1–5,0 einstellbar, Standard 1,4 (steuert die Stilkonsistenz, zu hoch und es wird steif, zu niedrig und es verliert an Kohärenz).
- Inferenzschritte: Einstellbar von 1 bis 50, Standard ist 10 (je höher die Anzahl der Schritte, desto detaillierter die Ergebnisse, aber der Zeitaufwand steigt linear an).
2.3 Video-zu-Video
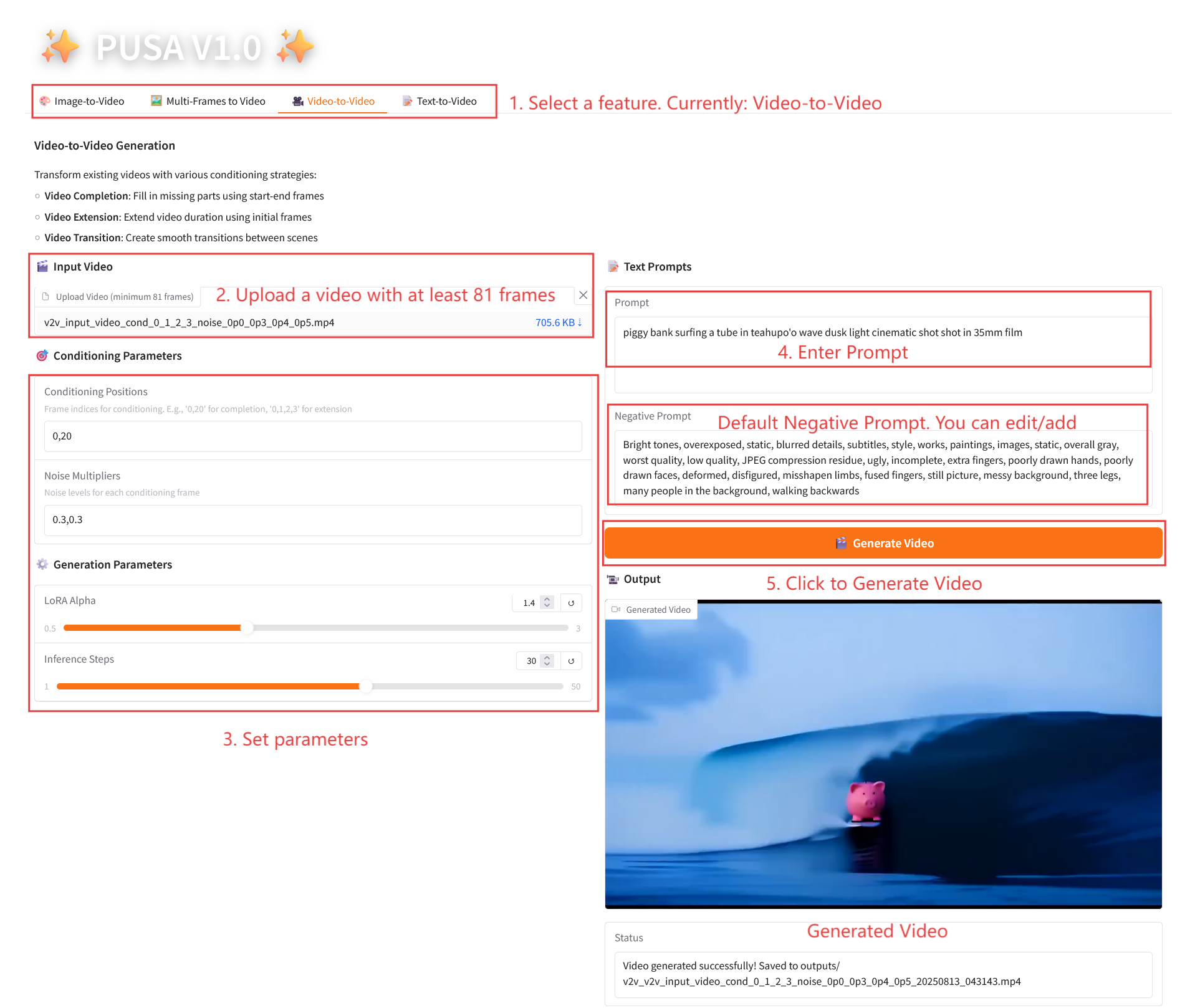
Parameterbeschreibung
- Konditionierungsparameter
- Konditionierungspositionen: Durch Kommas getrennte Frame-Indizes (z. B. „0,1,2,3“, die die Keyframe-Positionen im Originalvideo angeben, die für die Einschränkungsgenerierung verwendet wurden, erforderlich).
- Rauschmultiplikatoren: Durch Kommas getrennte Werte von 0,0–1,0 (z. B. „0,0,0,3“, entsprechend dem Einflussgrad jedes bedingten Frames, niedrigere Werte liegen näher am Originalframe, höhere Werte sind flexibler).
- Generierungsparameter
- LoRA Alpha: 0,1–5,0 einstellbar, Standard 1,4 (steuert die Stilkonsistenz, zu hoch und es wird steif, zu niedrig und es verliert an Kohärenz).
- Inferenzschritte: Einstellbar von 1 bis 50, Standard ist 10 (je höher die Anzahl der Schritte, desto detaillierter die Ergebnisse, aber der Zeitaufwand steigt linear an).
2.4 Text-zu-Video
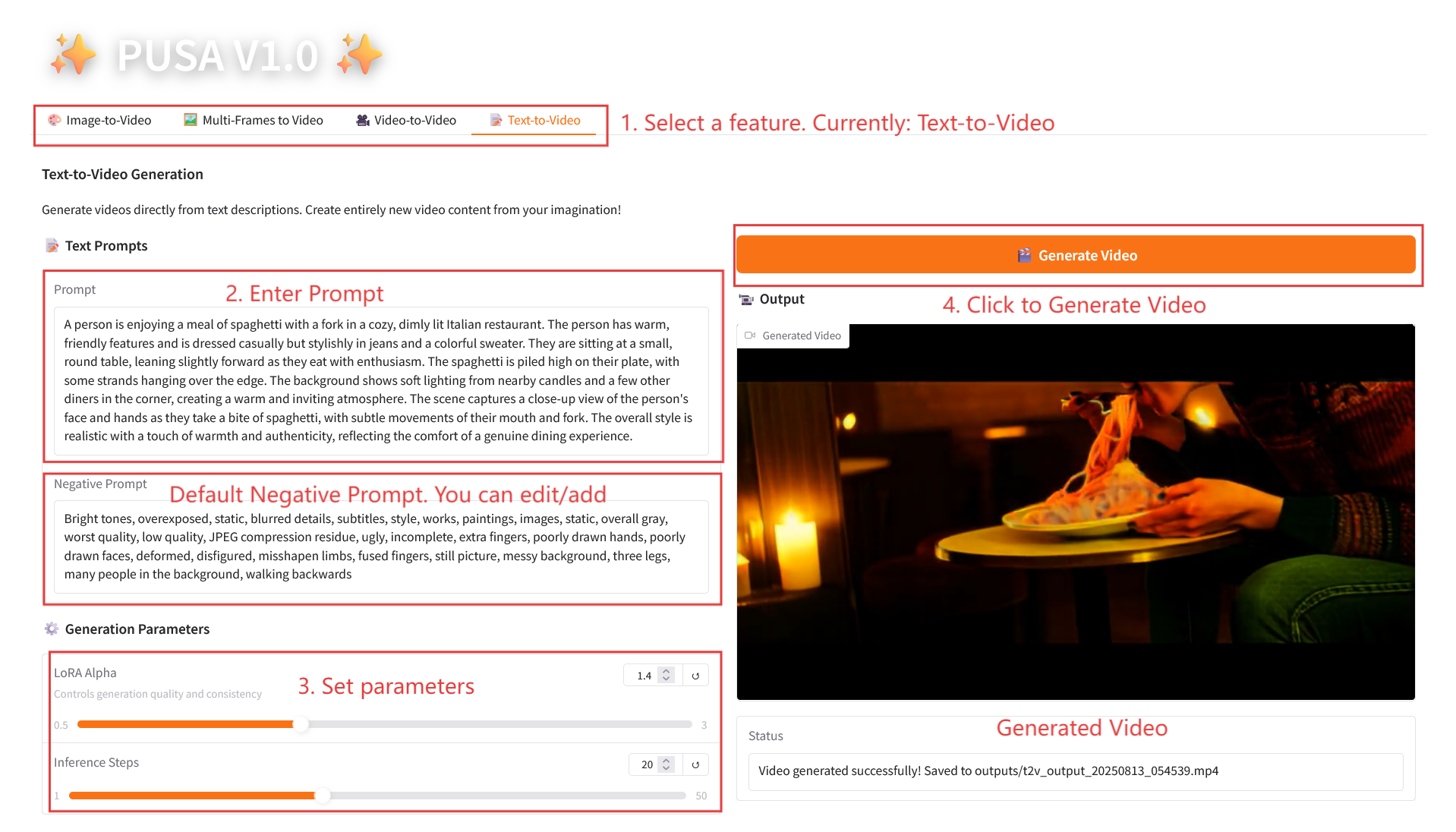
Parameterbeschreibung
- Generierungsparameter
- LoRA Alpha: 0,1–5,0 einstellbar, Standard 1,4 (steuert die Stilkonsistenz, zu hoch und es wird steif, zu niedrig und es verliert an Kohärenz).
- Inferenzschritte: Einstellbar von 1 bis 50, Standard ist 10 (je höher die Anzahl der Schritte, desto detaillierter die Ergebnisse, aber der Zeitaufwand steigt linear an).
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{liu2025pusa,
title={PUSA V1. 0: Surpassing Wan-I2V with $500 Training Cost by Vectorized Timestep Adaptation},
author={Liu, Yaofang and Ren, Yumeng and Artola, Aitor and Hu, Yuxuan and Cun, Xiaodong and Zhao, Xiaotong and Zhao, Alan and Chan, Raymond H and Zhang, Suiyun and Liu, Rui and others},
journal={arXiv preprint arXiv:2507.16116},
year={2025}
}
@misc{Liu2025pusa,
title={Pusa: Thousands Timesteps Video Diffusion Model},
author={Yaofang Liu and Rui Liu},
year={2025},
url={https://github.com/Yaofang-Liu/Pusa-VidGen},
}
@article{liu2024redefining,
title={Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach},
author={Liu, Yaofang and Ren, Yumeng and Cun, Xiaodong and Artola, Aitor and Liu, Yang and Zeng, Tieyong and Chan, Raymond H and Morel, Jean-michel},
journal={arXiv preprint arXiv:2410.03160},
year={2024}
}Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.