Command Palette
Search for a command to run...
VisA-Datensatz Zur Industriellen Visuellen Anomalieerkennung
Datum
Größe
Veröffentlichungs-URL
Paper-URL
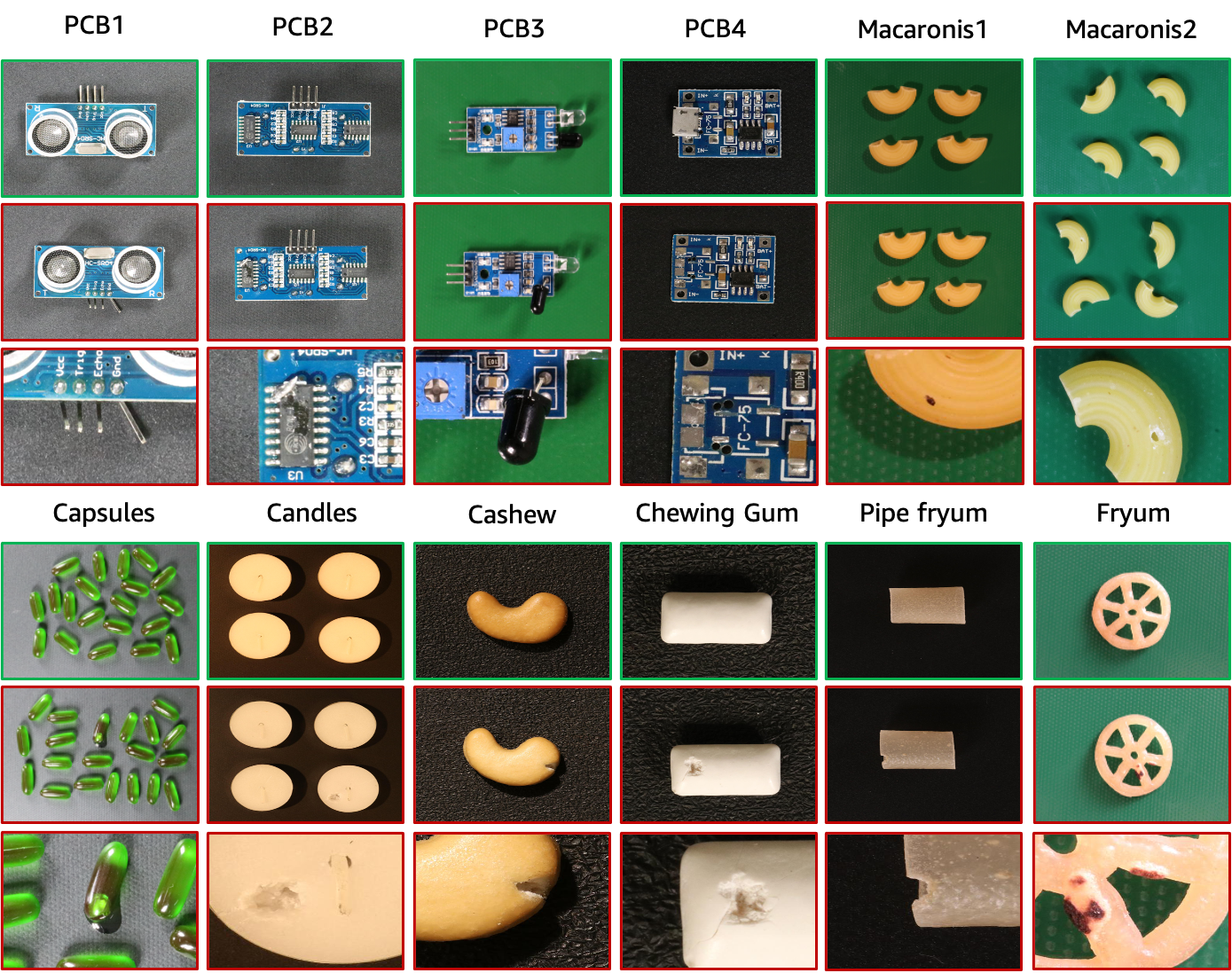
**Der VisA-Datensatz ist ein selbstüberwachter SPot-the-Difference-Vortrainingsdatensatz zur Anomalieerkennung und -segmentierung.**Es enthält 12 Teilmengen, die 12 verschiedenen Objekten entsprechen, wie in der Abbildung dargestellt. Es gibt 10.821 Bilder, darunter 9.621 normale Proben und 1.200 abnormale Proben. Bei den vier Teilmengen handelt es sich um unterschiedliche Arten von Leiterplatten (PCBs), die relativ komplexe Strukturen aufweisen und Transistoren, Kondensatoren, Chips usw. enthalten. Für den Fall mehrerer angezeigter Instanzen erfassen wir vier Teilmengen: Kapseln, Kerzen, Makkaroni1 und Makkaroni2. Die Instanzen in Capsules und Macaroni2 unterscheiden sich stark in Position und Pose. Darüber hinaus sammelte das Forschungsteam vier Untergruppen, darunter Cashewnüsse, Kaugummi, Pommes Frites und Pfeifenpommes, in denen die Objekte grob angeordnet waren. Zu den anormalen Bildern zählen eine Reihe von Defekten, darunter Oberflächenfehler wie Kratzer, Dellen, Farbflecken oder Risse sowie strukturelle Defekte wie falsch platzierte oder fehlende Teile.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.