HyperAI
Command Palette
Search for a command to run...
PaddleOCR-VL:多模态文档解析
一、教程简介

PaddleOCR-VL 是一款专为文档解析任务设计的、达到业界领先水平(SOTA)且资源高效的模型。其核心组件是 PaddleOCR-VL-0.9B,这是一个紧凑而强大的视觉语言模型(VLM),它集成了 NaViT 风格的动态分辨率视觉编码器与 ERNIE-4.5-0.3B 语言模型,从而能够实现精准的元素识别。这一创新模型高效地支持 109 种语言,并在识别复杂元素(例如文本、表格、公式和图表)方面表现卓越,同时保持了极低的资源消耗。通过在广泛使用的公共基准测试和内部基准测试上进行综合评估,PaddleOCR-VL 在页面级文档解析和元素级识别任务上均实现了 SOTA 性能。 该模型显著优于现有解决方案,在与顶尖视觉语言模型的对比中展现出强大的竞争力,并能提供快速的推理速度。这些优势使其非常适合于实际场景中的部署应用。相关论文成果为 PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model 。
该教程算力资源采用单卡 RTX 5090 。
二、效果示例
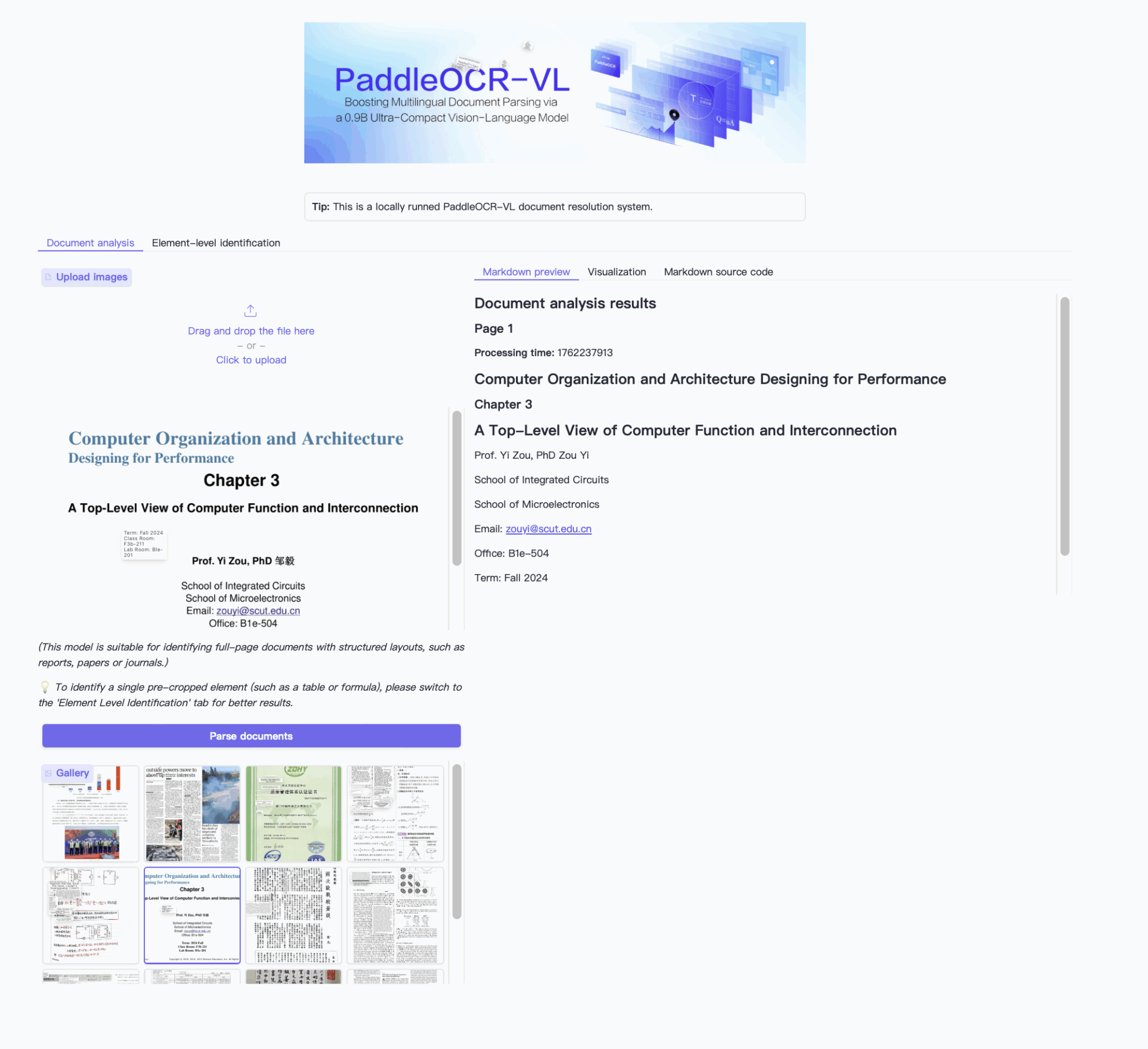
三、运行步骤
1. 启动容器
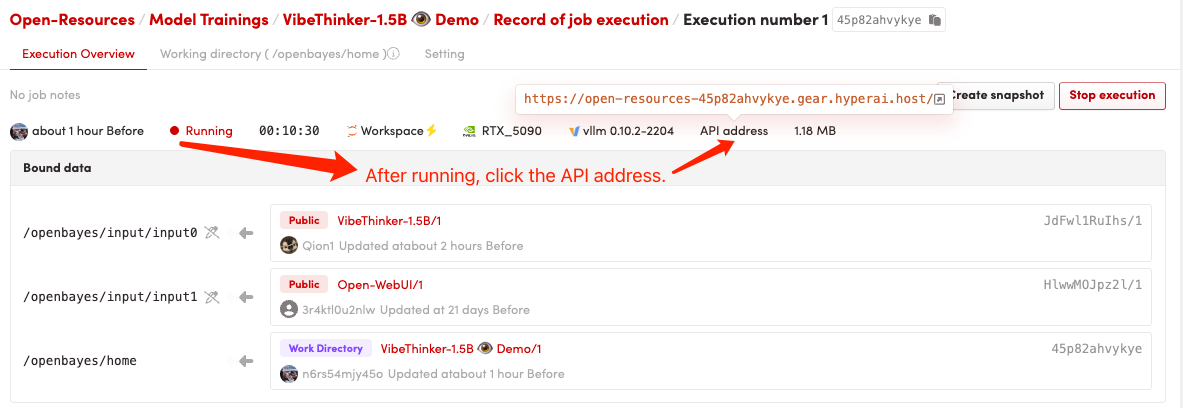
2. 进入网页后,即可与模型展开对话
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
使用步骤
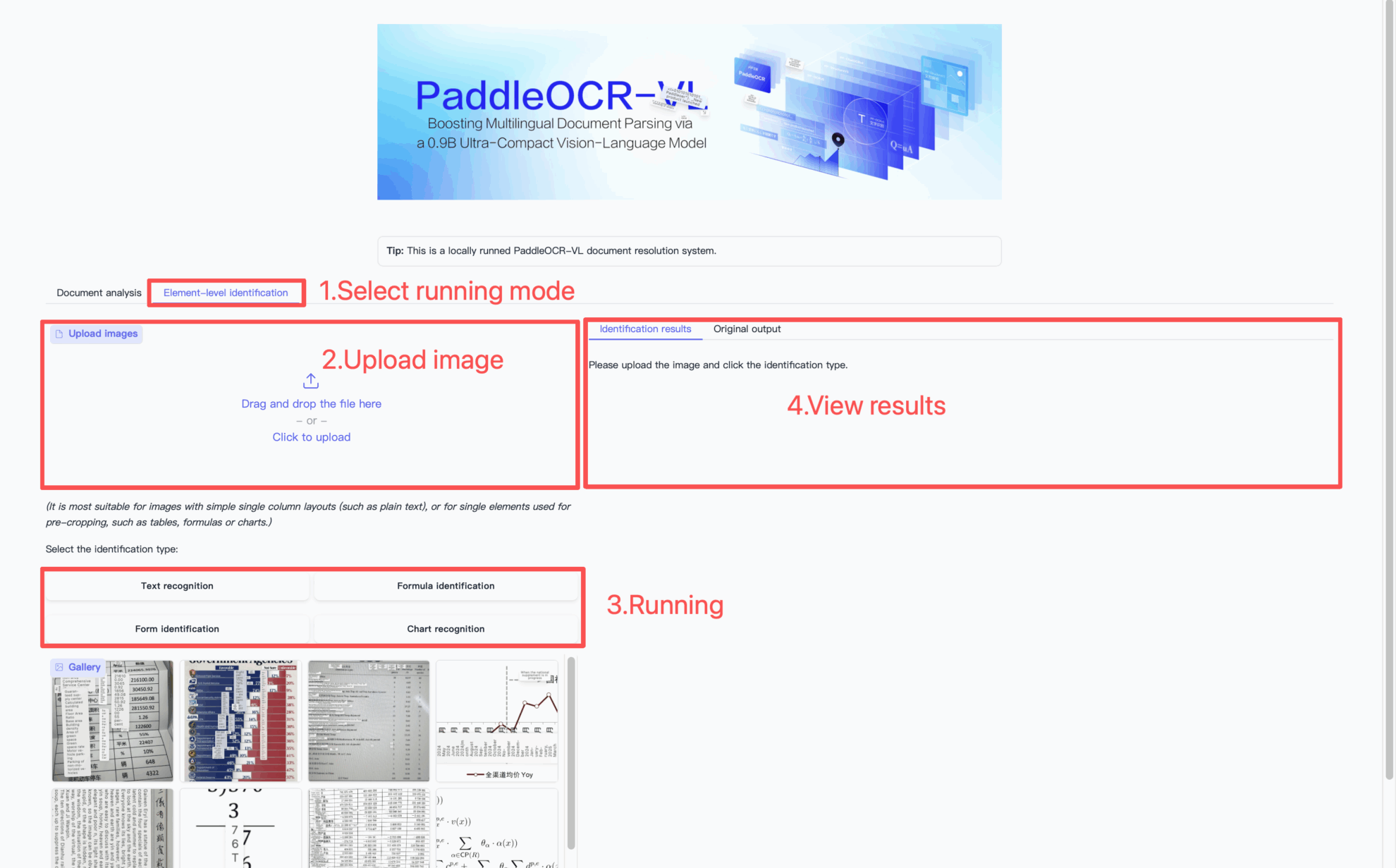
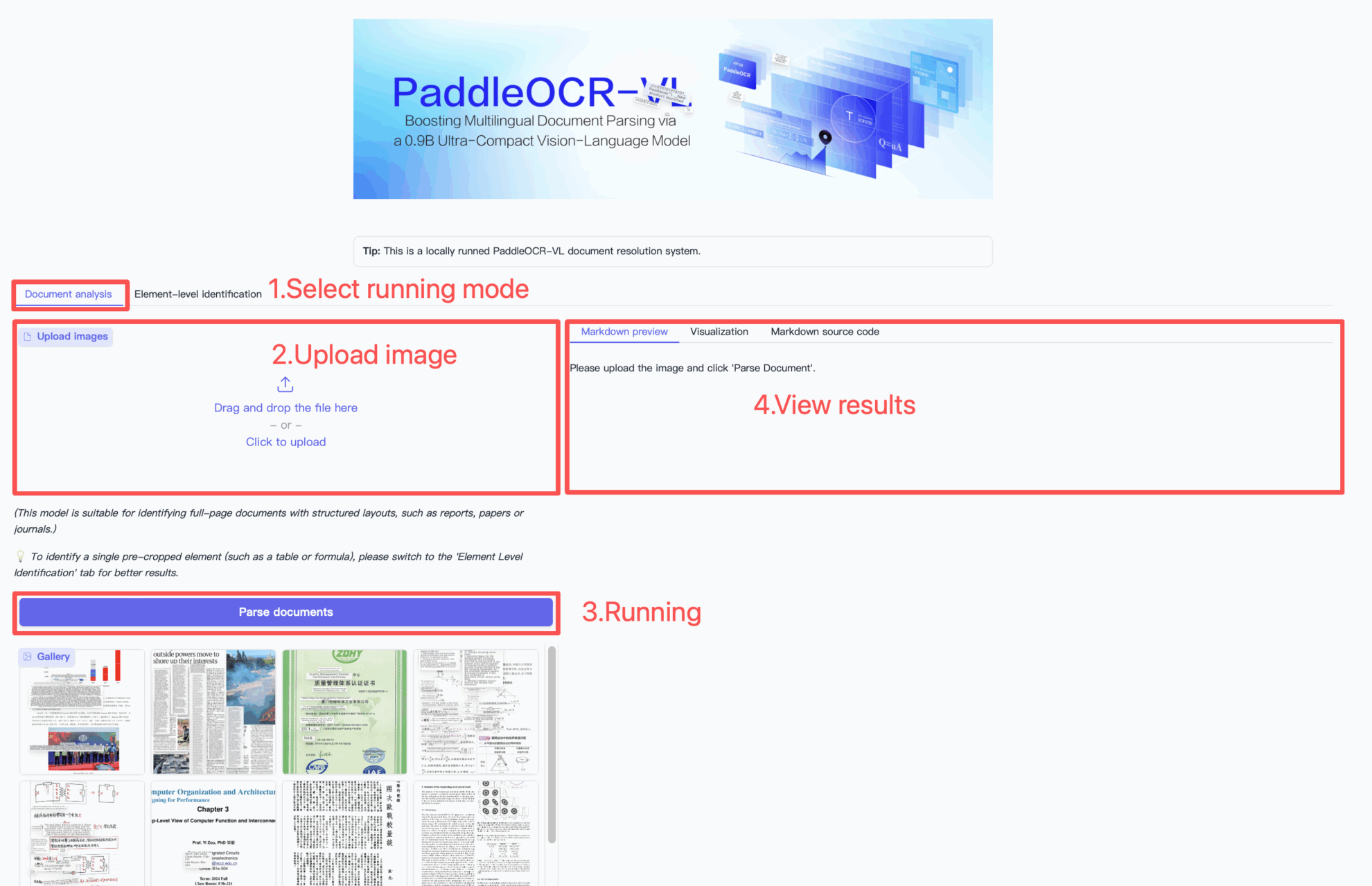
引用信息
@misc{cui2025paddleocrvlboostingmultilingualdocument,
title={PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model},
author={Cheng Cui and Ting Sun and Suyin Liang and Tingquan Gao and Zelun Zhang and Jiaxuan Liu and Xueqing Wang and Changda Zhou and Hongen Liu and Manhui Lin and Yue Zhang and Yubo Zhang and Handong Zheng and Jing Zhang and Jun Zhang and Yi Liu and Dianhai Yu and Yanjun Ma},
year={2025},
eprint={2510.14528},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.14528},
}本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。