HyperAI
Command Palette
Search for a command to run...
VoxCPM:无分词器的 TTS 技术
一、教程简介
VoxCPM 是由面壁智能与清华大学深圳国际研究生院于 2025 年 9 月联合开发的 0.5B 参数语音生成模型。在语音合成的自然度、音色相似度及韵律表现力方面达到了业界顶尖水平。 VoxCPM 采用端到端的扩散自回归架构,直接从文本生成连续语音表示,突破了传统离散分词的局限。通过分层语言建模和有限状态量化约束,实现了语义与声学的隐式解耦,显著提升了语音的表达力和生成稳定性。 VoxCPM 支持零样本声音克隆,仅需一段参考音频,能精准复刻说话者的音色、口音、情感语调等特征,生成高度逼真的语音。
该教程算力资源采用单卡 RTX 4090 。
二、效果展示
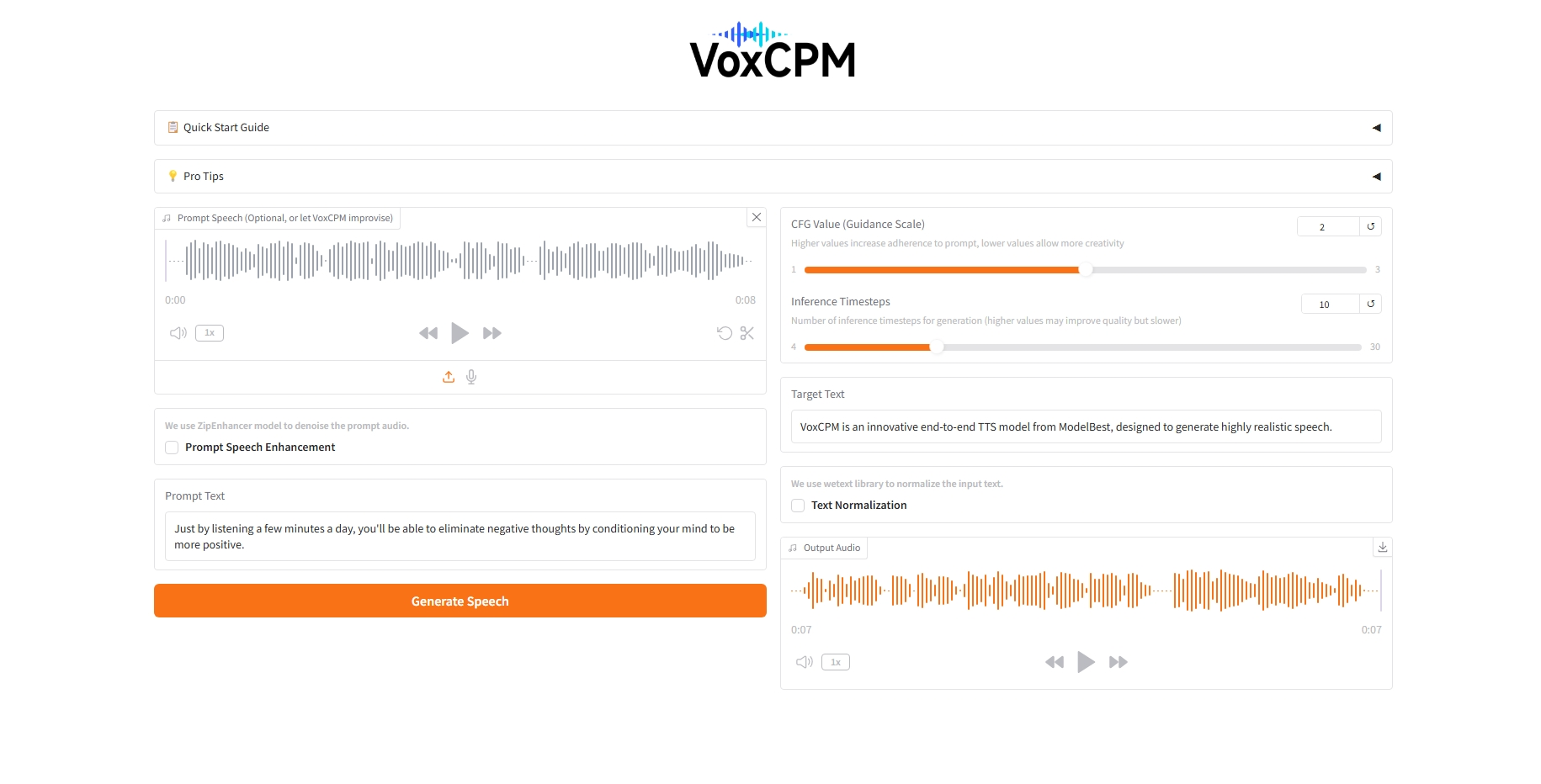
三、运行步骤
1. 启动容器
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
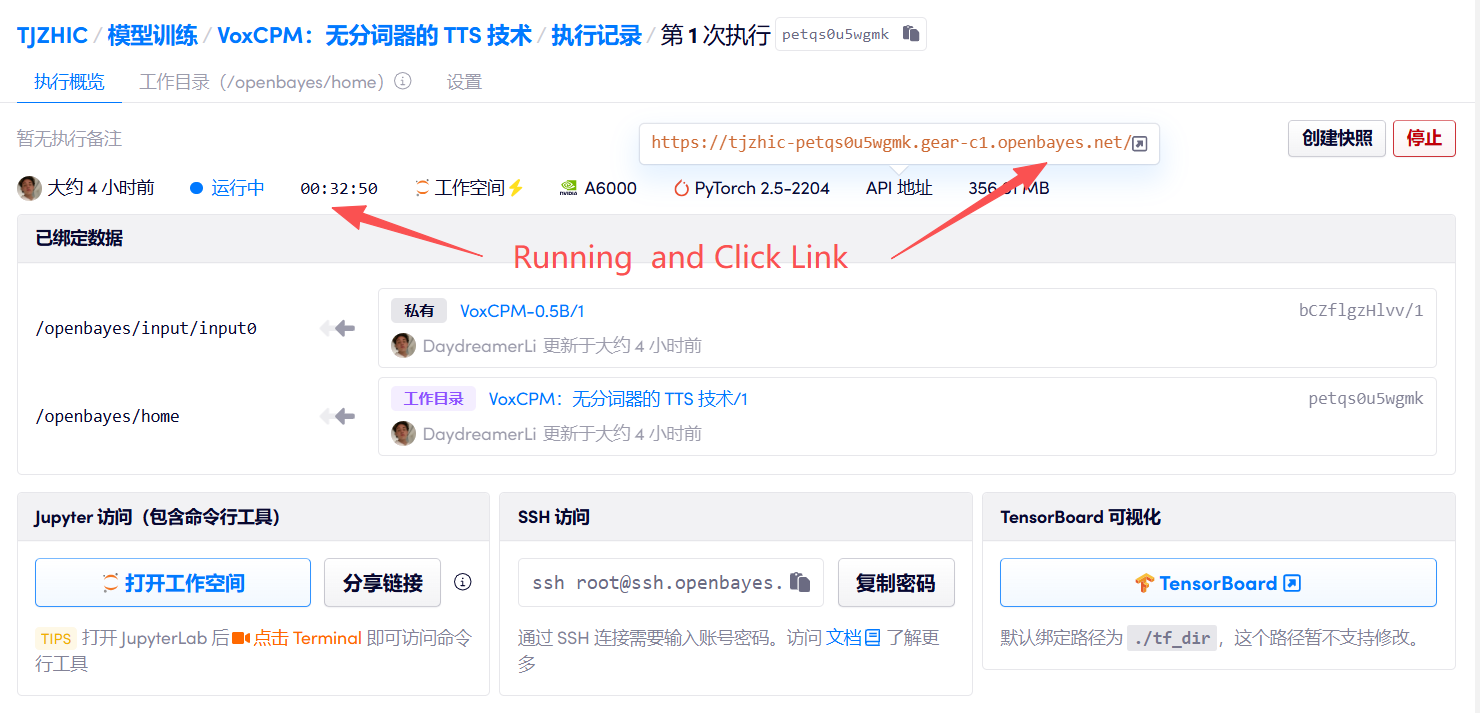
2. 使用步骤
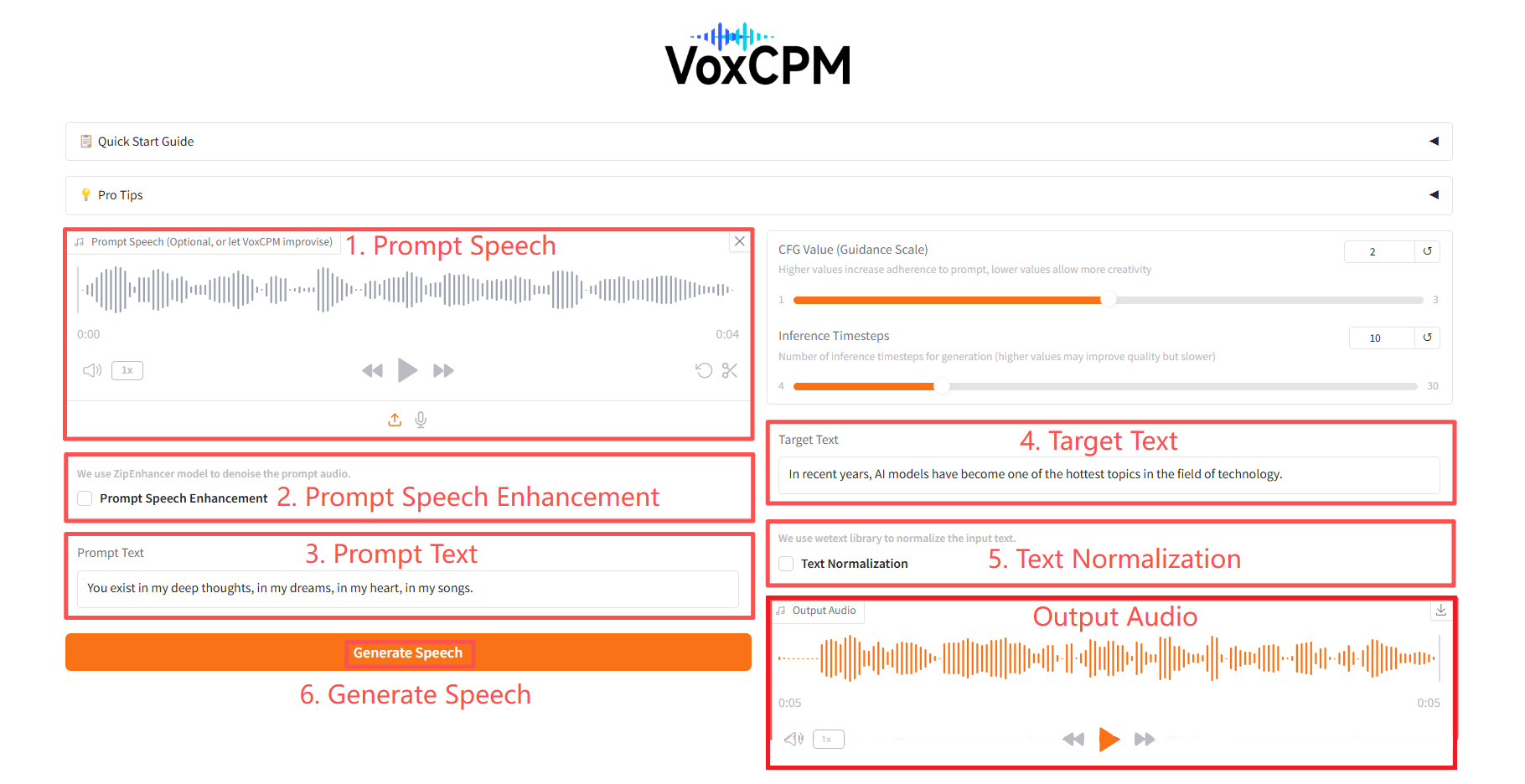
具体参数:
- CFG Value:值越高,对提示的依从性越高,值越低,创造力越高。
- Inference Timesteps:生成的推理时间步长数(值越高可能会提高质量,但速度越慢)。
- Prompt Speech Enhancement:使用 ZipEnhancer 模型对提示音频进行降噪。
- Text Normalization:使用 wetext 库来规范化输入文本。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@misc{voxcpm2025,
author = {{Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, Zhiyong Wu, Zhiyuan Liu}},
title = {{VoxCPM}},
year = {2025},
publish = {\url{https://github.com/OpenBMB/VoxCPM}},
note = {GitHub repository}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。