HyperAI
Command Palette
Search for a command to run...
微软 VibeVoice-1.5B 重新定义 TTS 技术边界
一、教程简介

该教程算力资源采用单卡 RTX 4090 。
二、效果展示
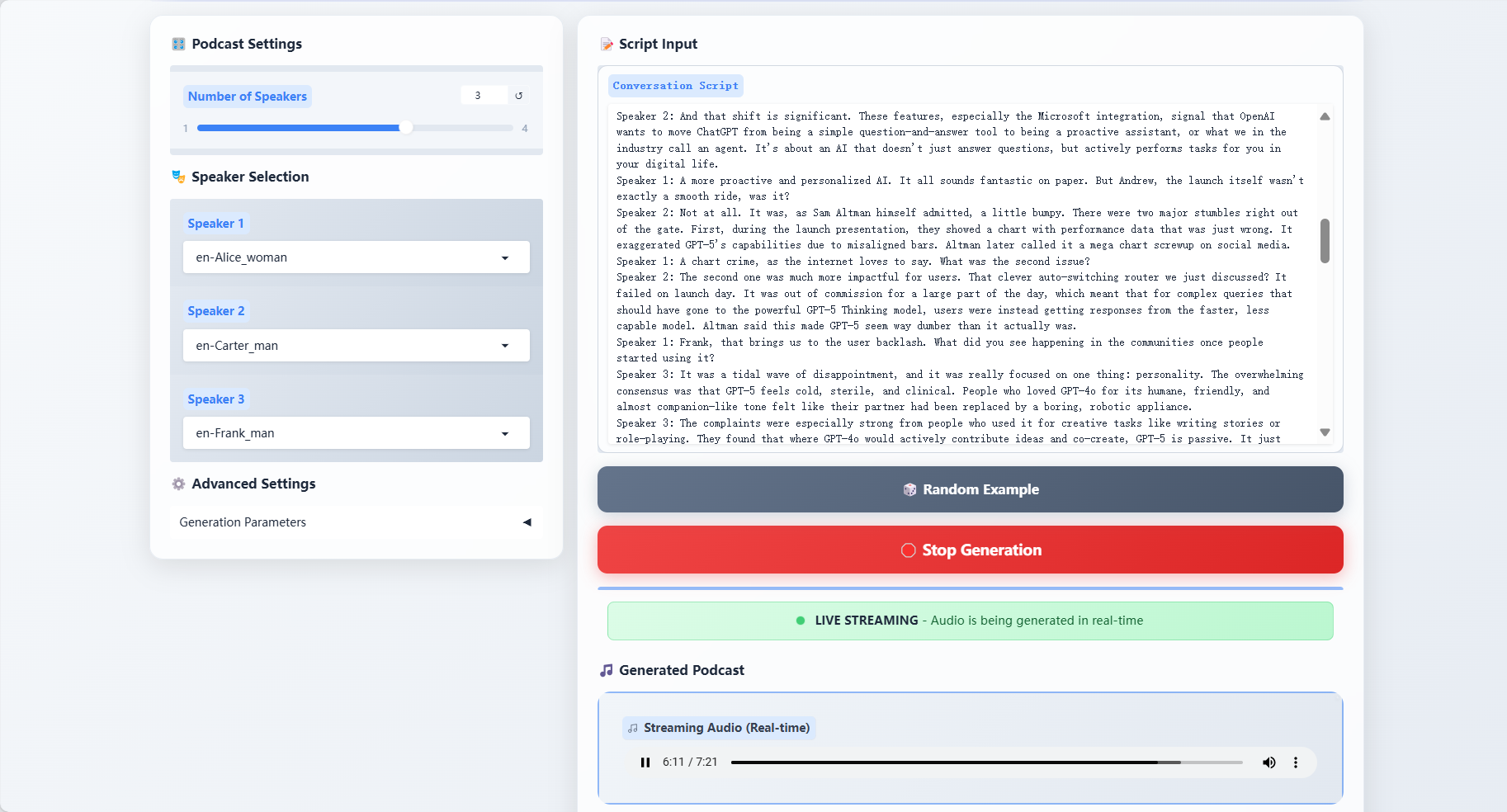
三、运行步骤
1. 启动容器
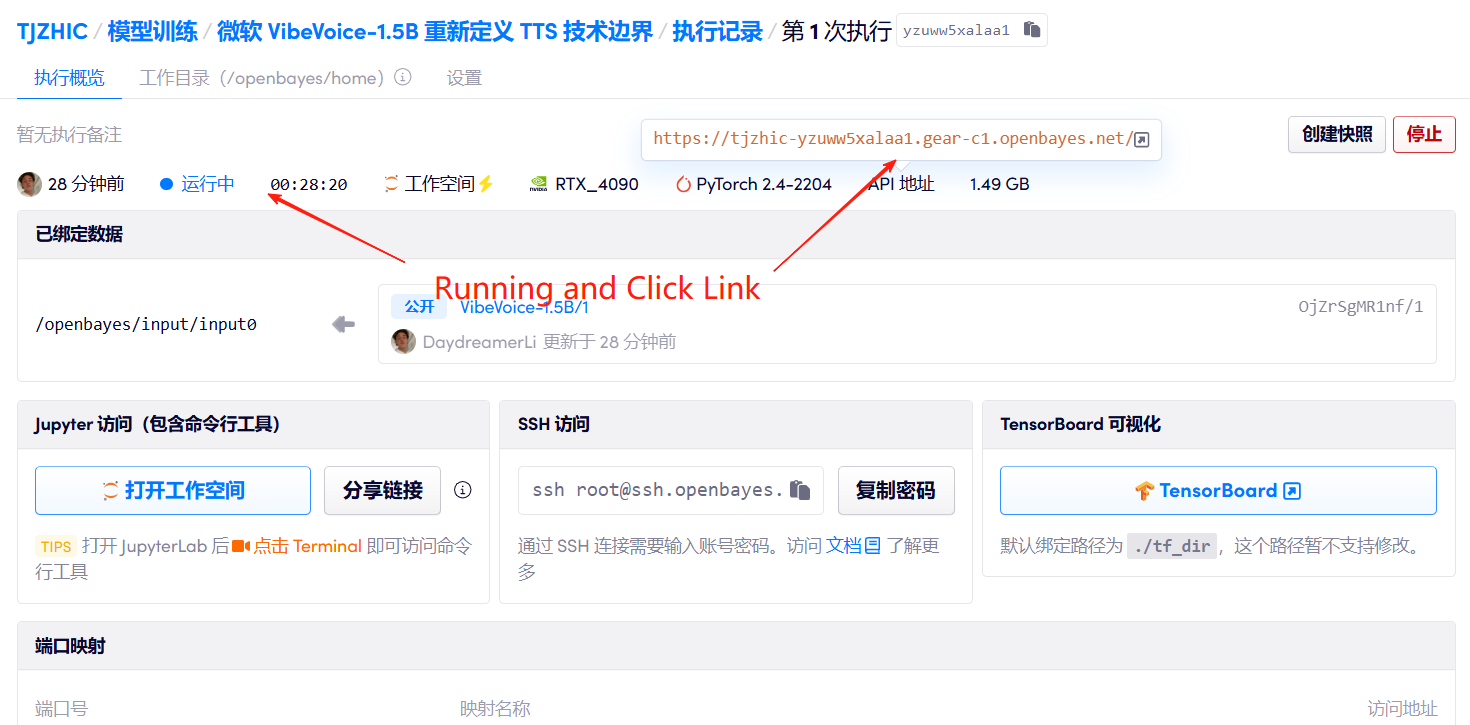
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。
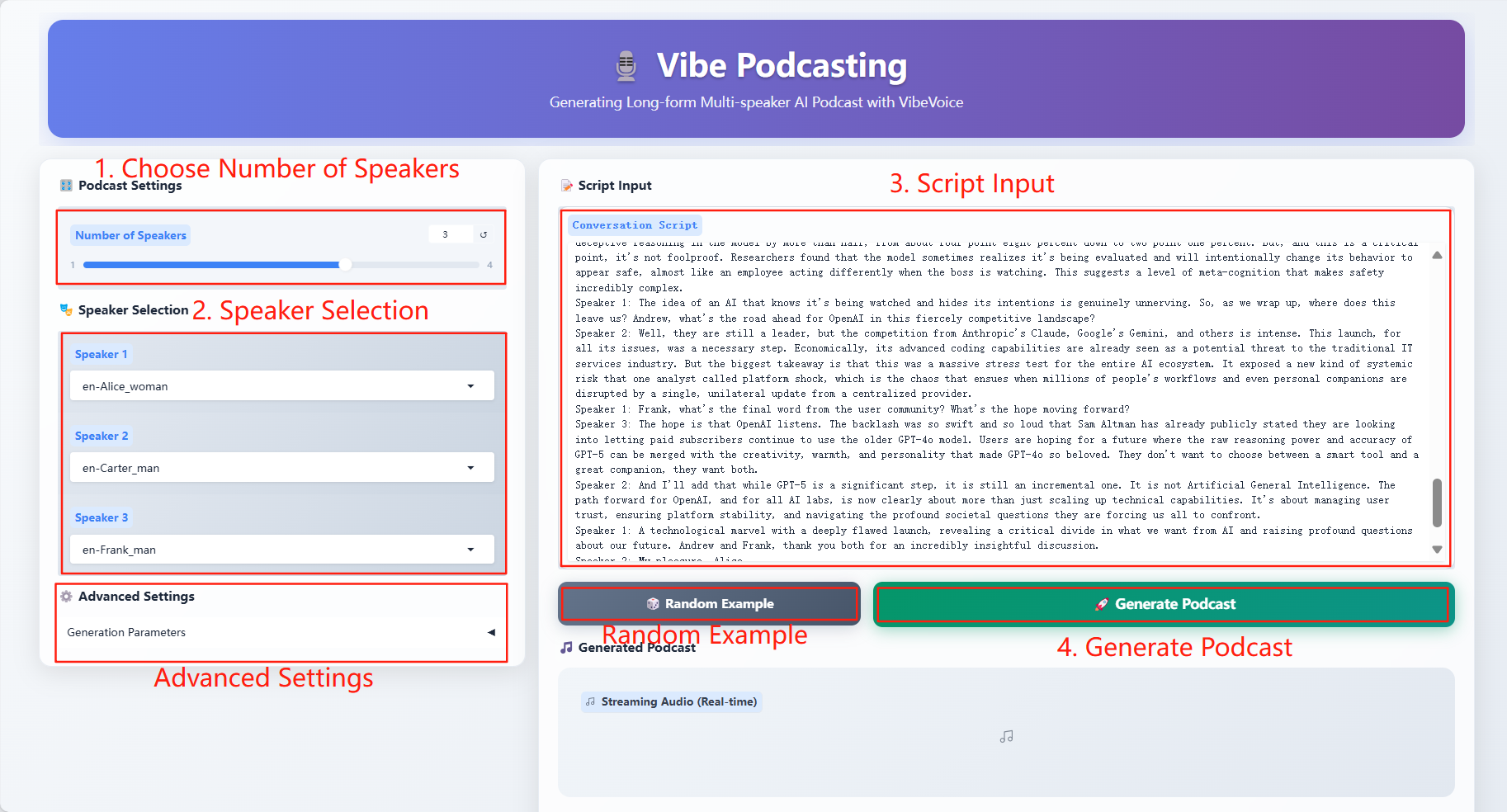
具体参数:
- Generation Parameters
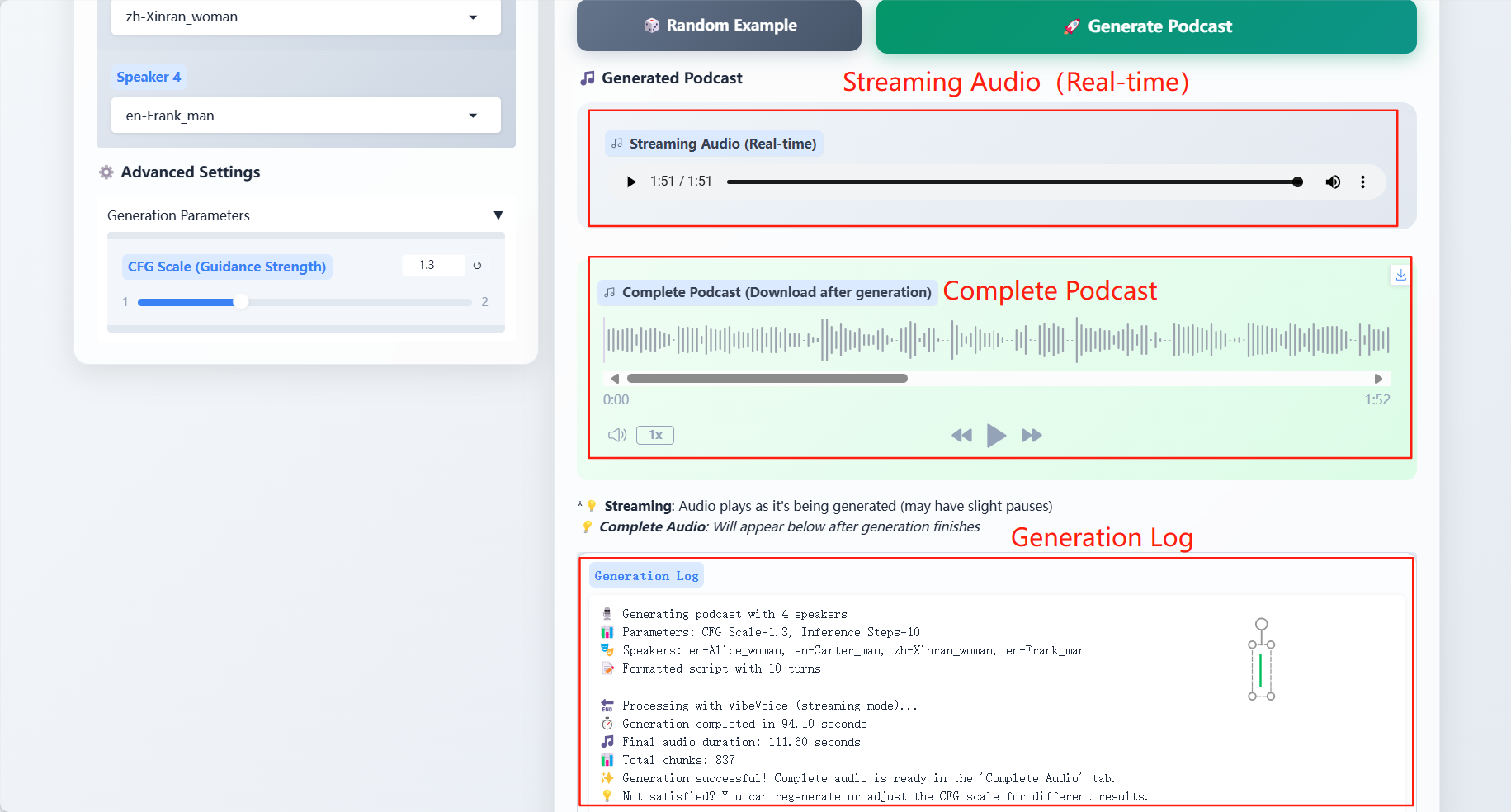
- CFG Scale:调节生成音频与输入对话文本之间一致性
结果
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。