HyperAI
Command Palette
Search for a command to run...
MOSS:文本到口语对话生成
一、教程简介

本教程采用资源为单卡 RTX 5090 。
二、项目示例
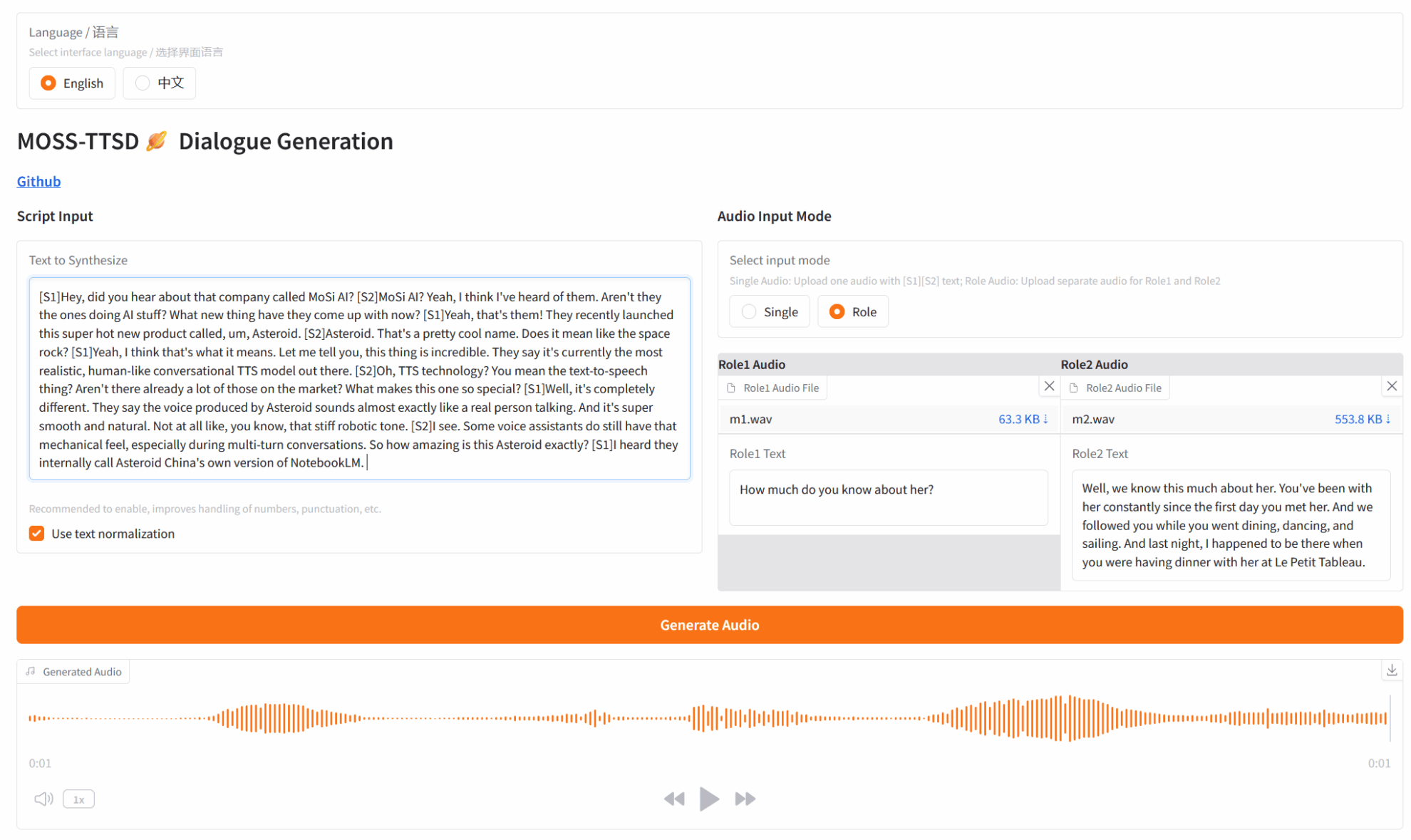
三、运行步骤
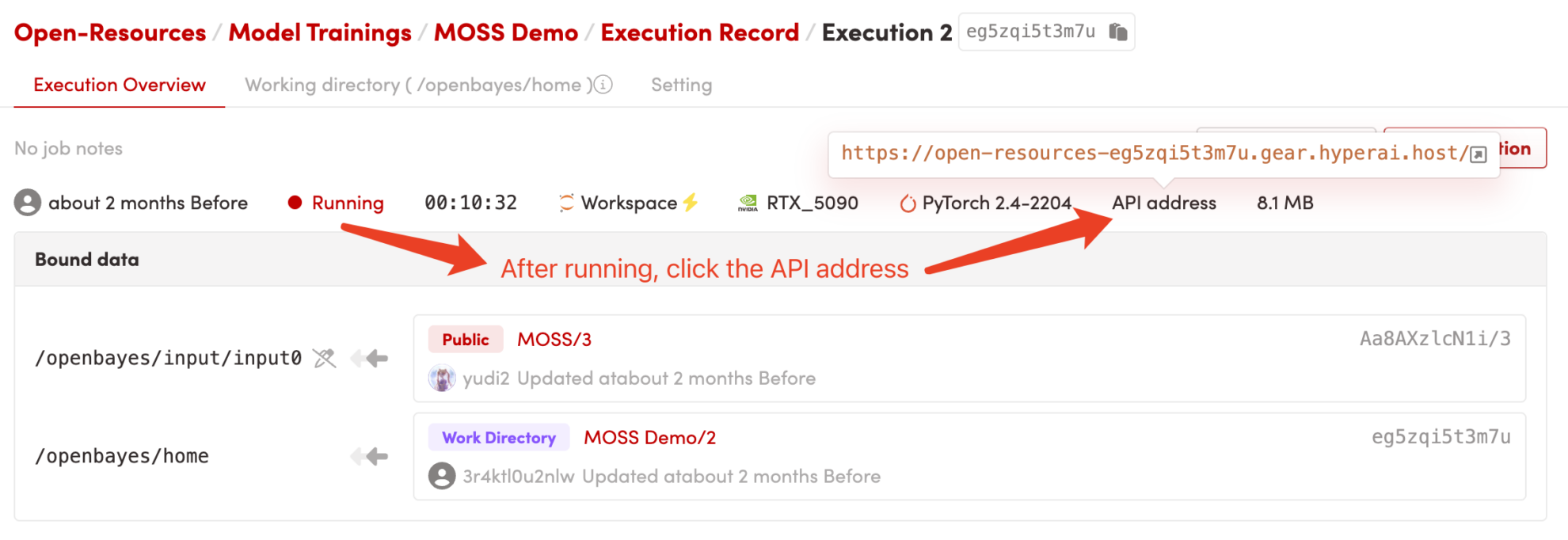
1. 启动容器后点击 API 地址即可进入 Web 界面
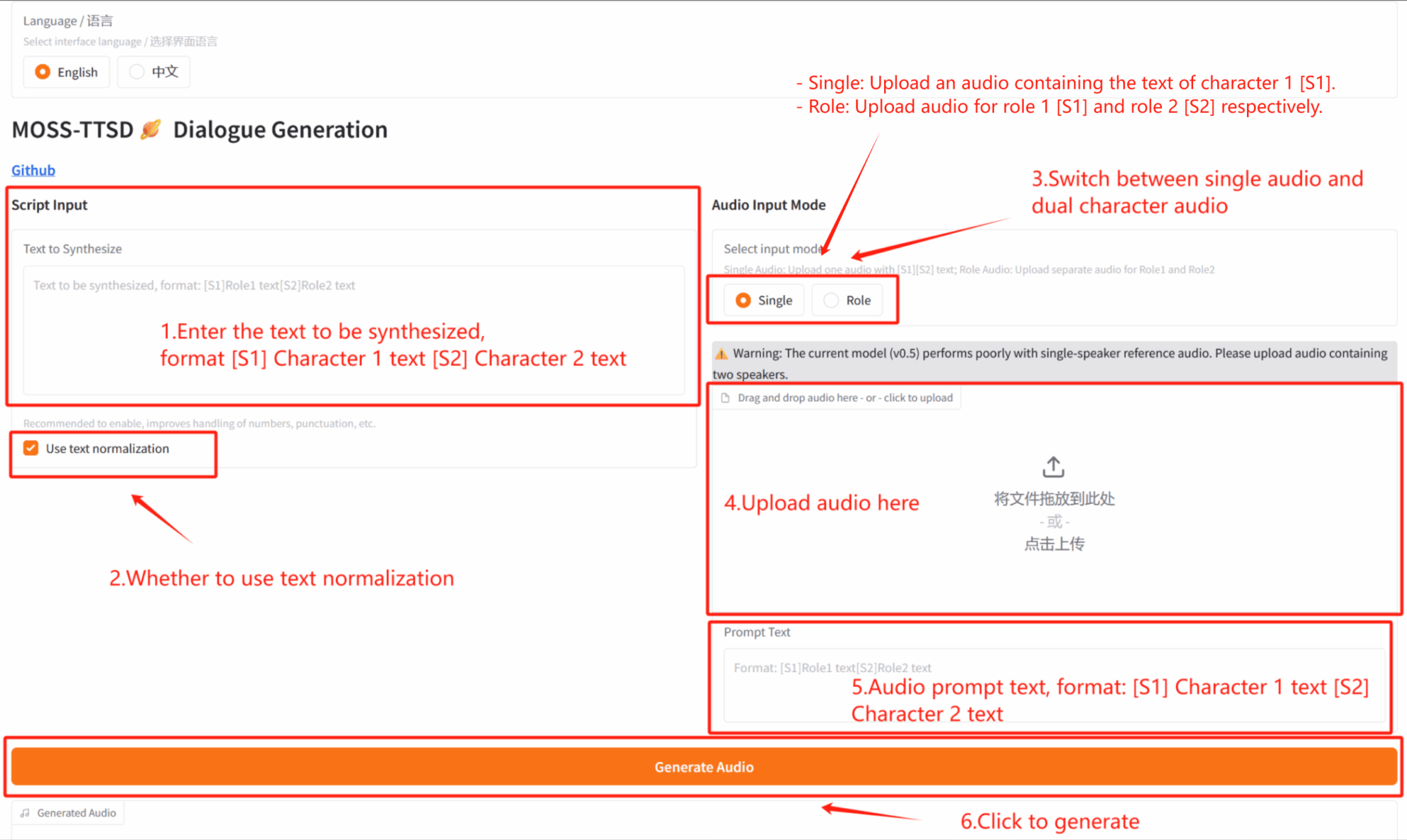
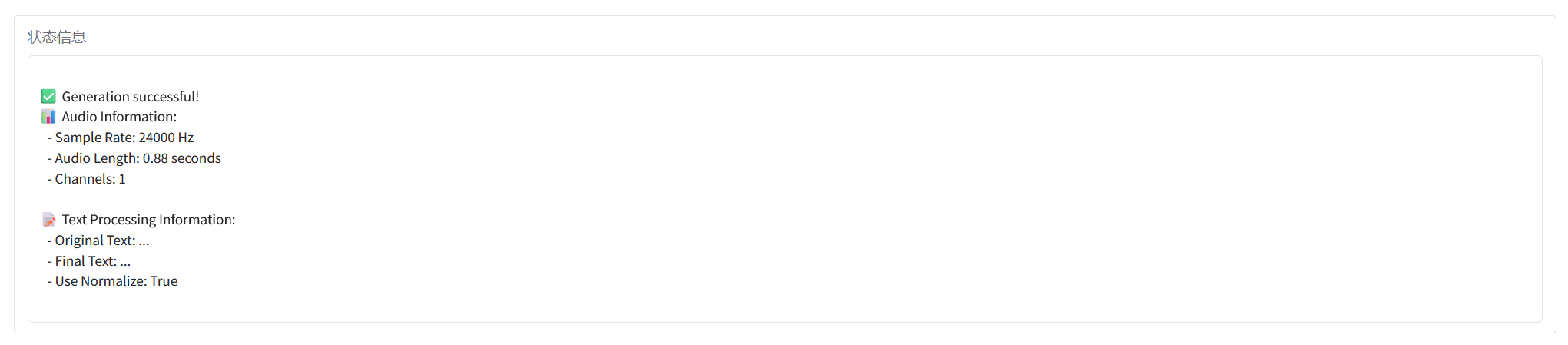
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 2-3 分钟后刷新页面。使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
*该教程可在「音频输入模式」处选择单人音频生成(Single)和双人对话音频生成(Role)。
引用信息
本项目引用信息如下:
@article{moss2025ttsd,
title={Text to Spoken Dialogue Generation},
author={OpenMOSS Team},
year={2025}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。