HyperAI
Command Palette
Search for a command to run...
Voxtral-Small-24B-2507 语音理解模型 Demo
一、教程简介
Voxtral 是由 Mistral AI 于 2025 年 7 月推出的先进音频模型,基于卓越的语音转录和深度理解能力,推动语音作为自然的人机交互方式。 Voxtral 提供 24B 和 3B 两种版本,分别适用生产规模和本地部署。 Voxtral 支持多语言、长文本上下文、内置问答和总结功能,能直接触发后端功能调用。 Voxtral 性能在多个基准测试中超越现有开源模型和专有 API,同时成本更低,广泛应用在各种场景,助力语音交互的普及。
主要功能:
- 长文本上下文处理:支持长达 30 分钟 的音频转录和 40 分钟的音频理解,能处理复杂的长篇内容。
- 内置问答与总结:直接对音频内容提问,或生成结构化的总结,无需额外的 ASR 和语言模型。
- 多语言支持:自动语言检测,支持多种常用语言(如英语、西班牙语、法语、葡萄牙语、印地语、德语等),满足全球用户需求。
- 语音触发功能调用:根据用户语音意图直接触发后端功能、工作流或 API 调用,无需中间解析步骤。
- 文本理解能力:保留 Mistral Small 3.1 的文本理解能力,支持文本输入和处理。
- 优化的转录性能:提供高度优化的转录端点,成本效益高,适合大规模应用。
该教程算力资源采用双卡 RTX A6000,本教程部署的模型为 Voxtral-Small-24B-2507 。提供 Audio Transcription 、 Audio Understanding 两个功能供测试。
二、效果展示
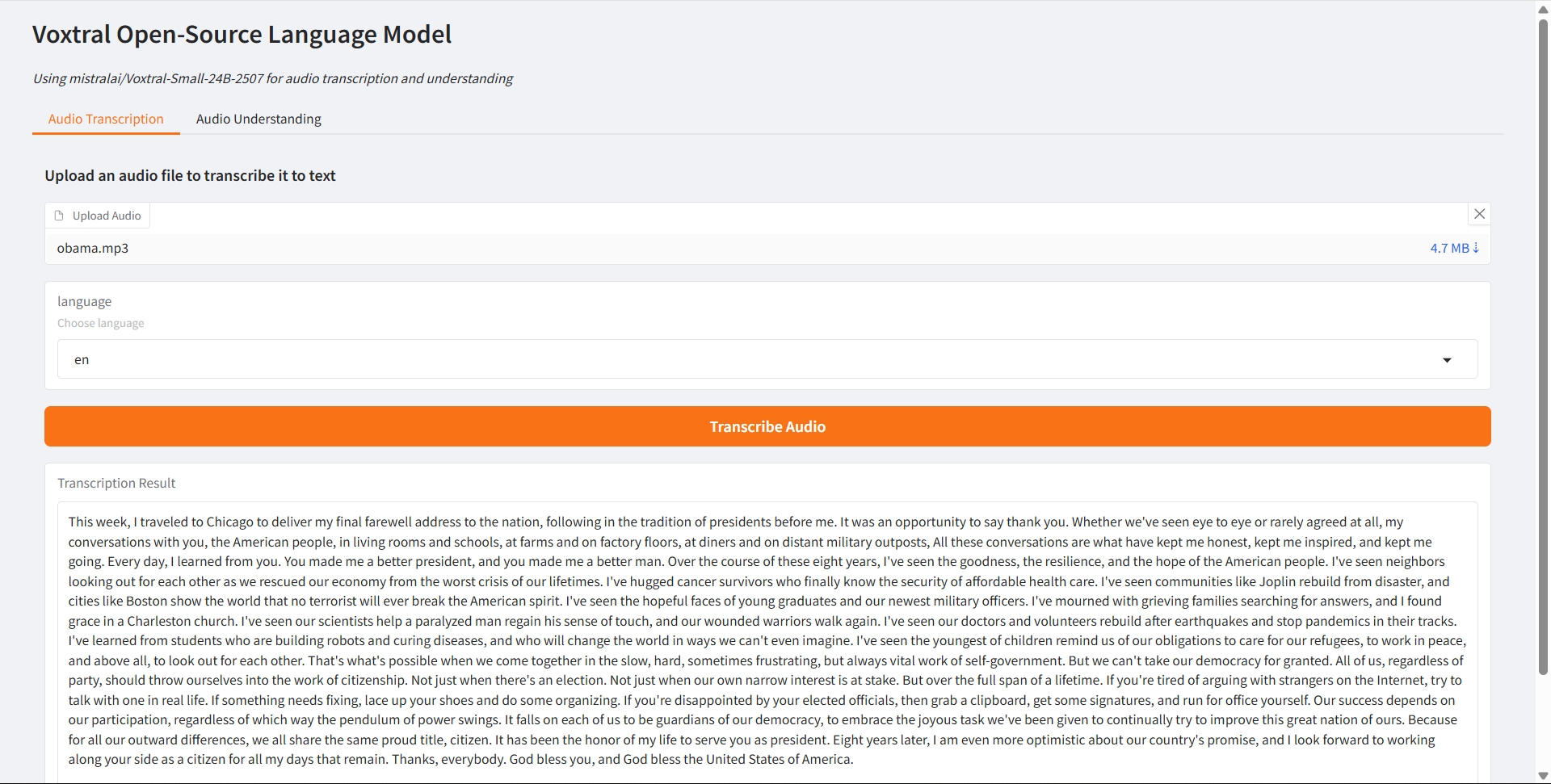
Audio Transcription
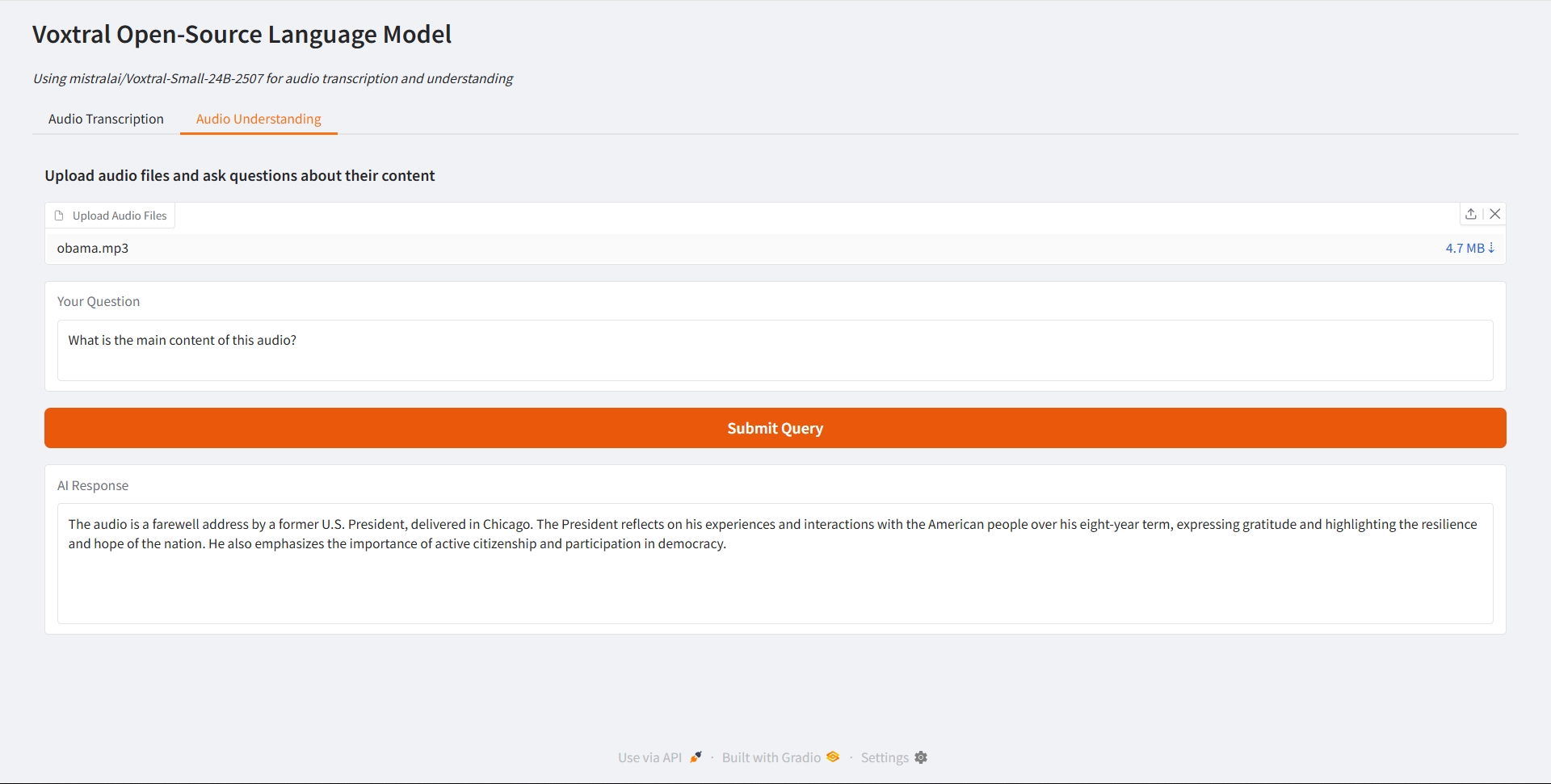
Audio Understanding
三、运行步骤
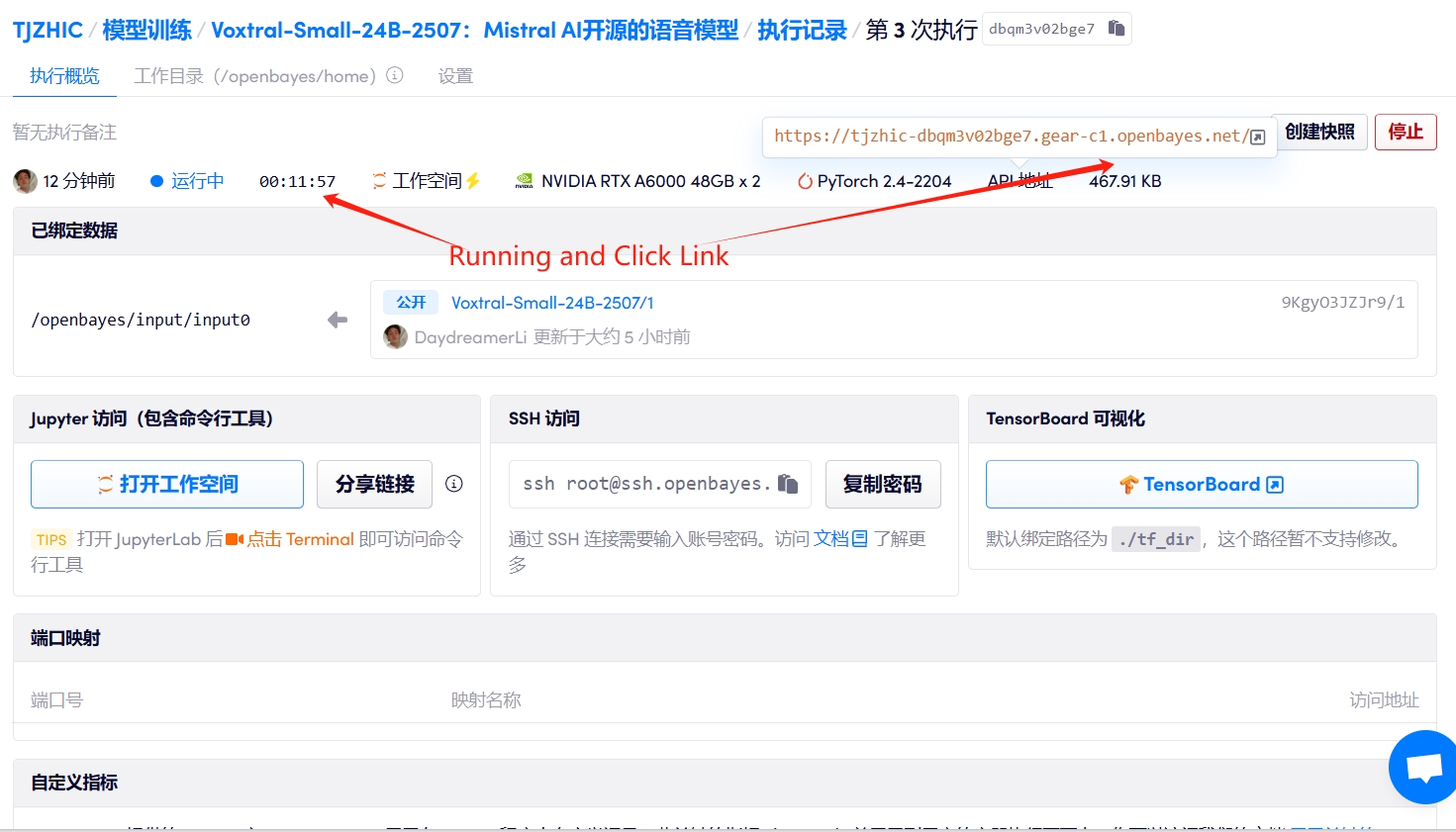
1. 启动容器
2. 使用步骤
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 5-10 分钟后刷新页面。
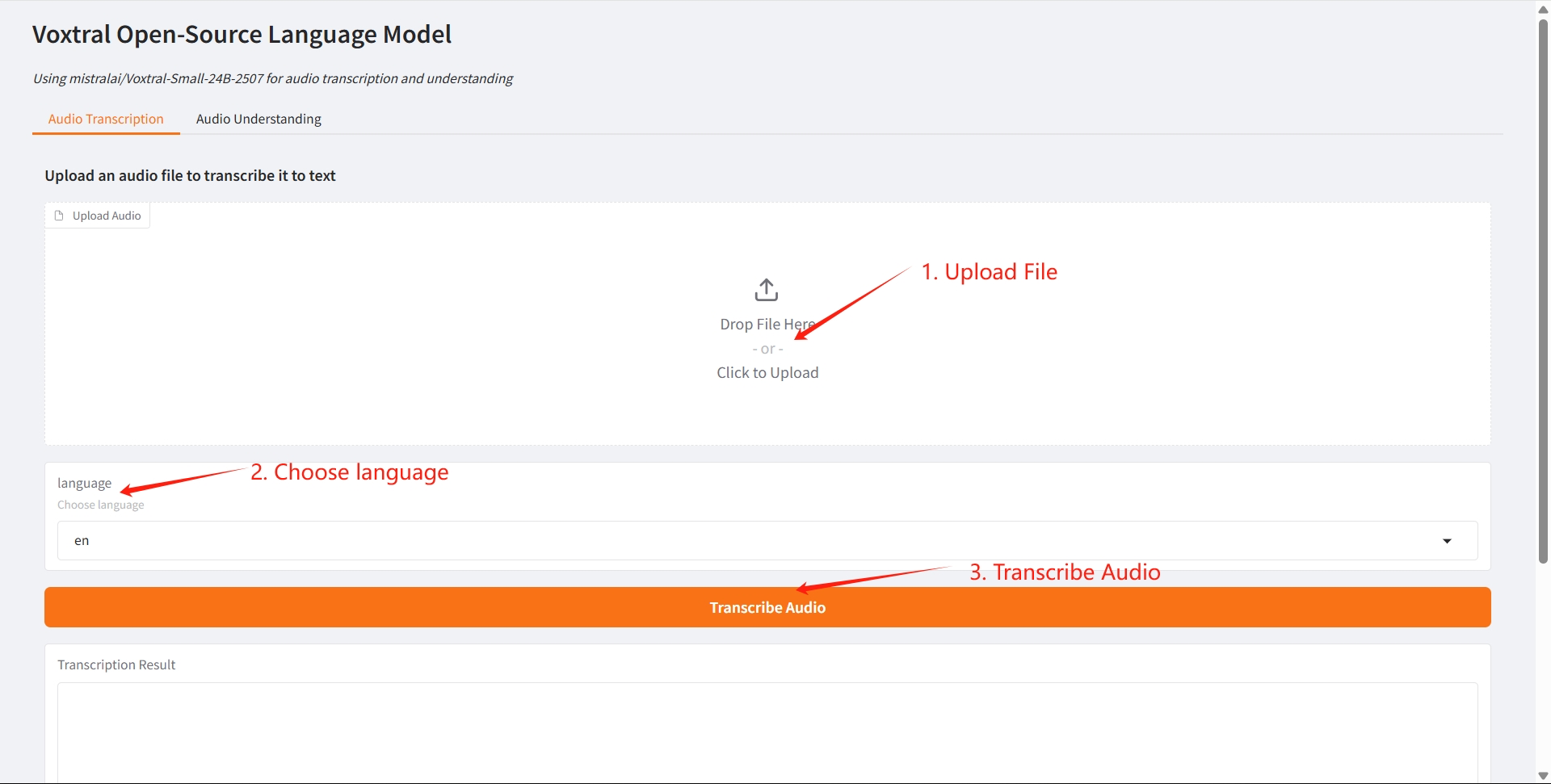
1. Audio Transcription
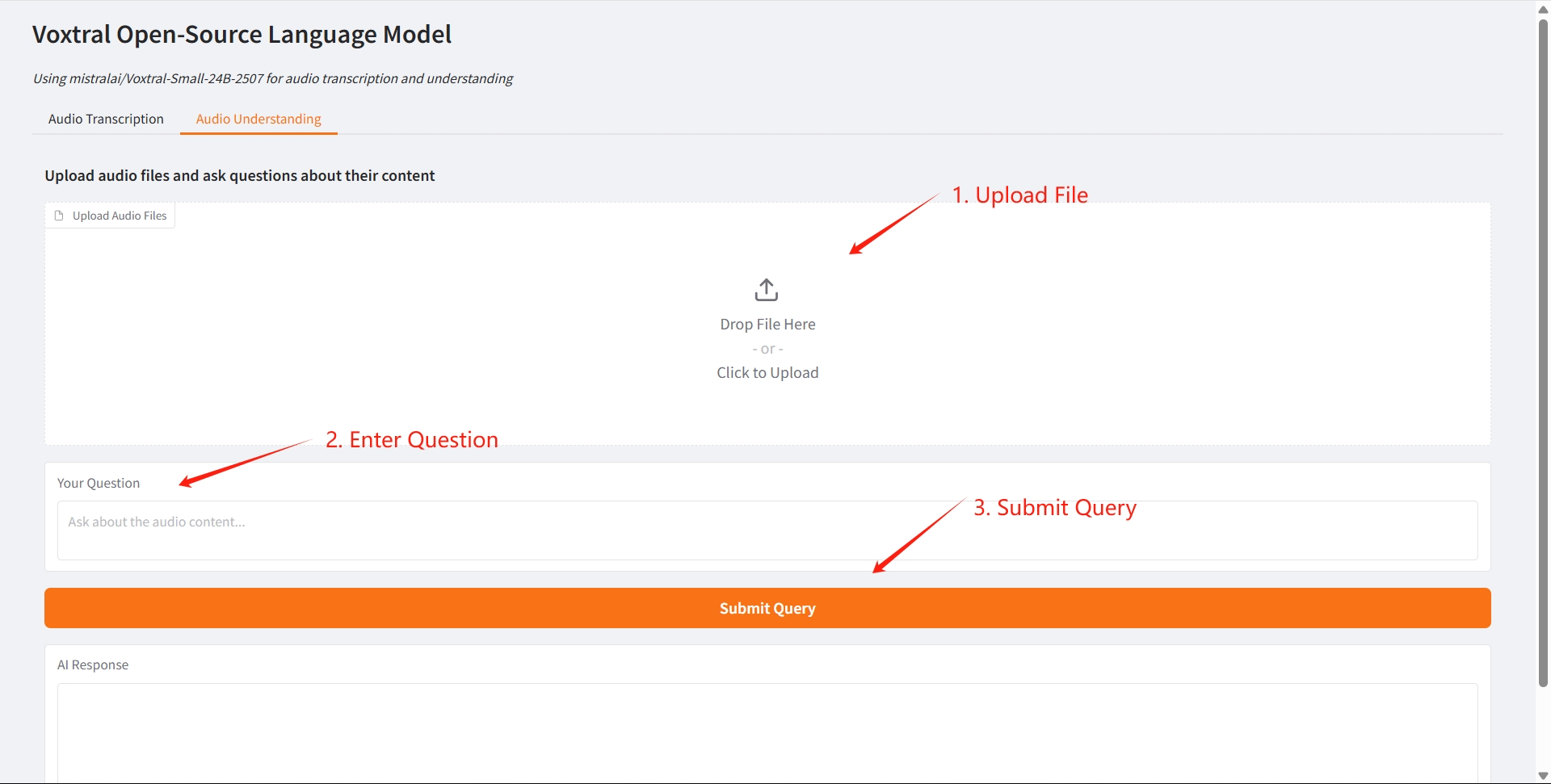
2. Audio Understanding
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。