HyperAI
Command Palette
Search for a command to run...
Stable-audio-open-small:音频生成模型 Demo
一、教程简介

本教程采用资源为单卡 A6000 。生成提示词仅支持英文。
二、项目示例
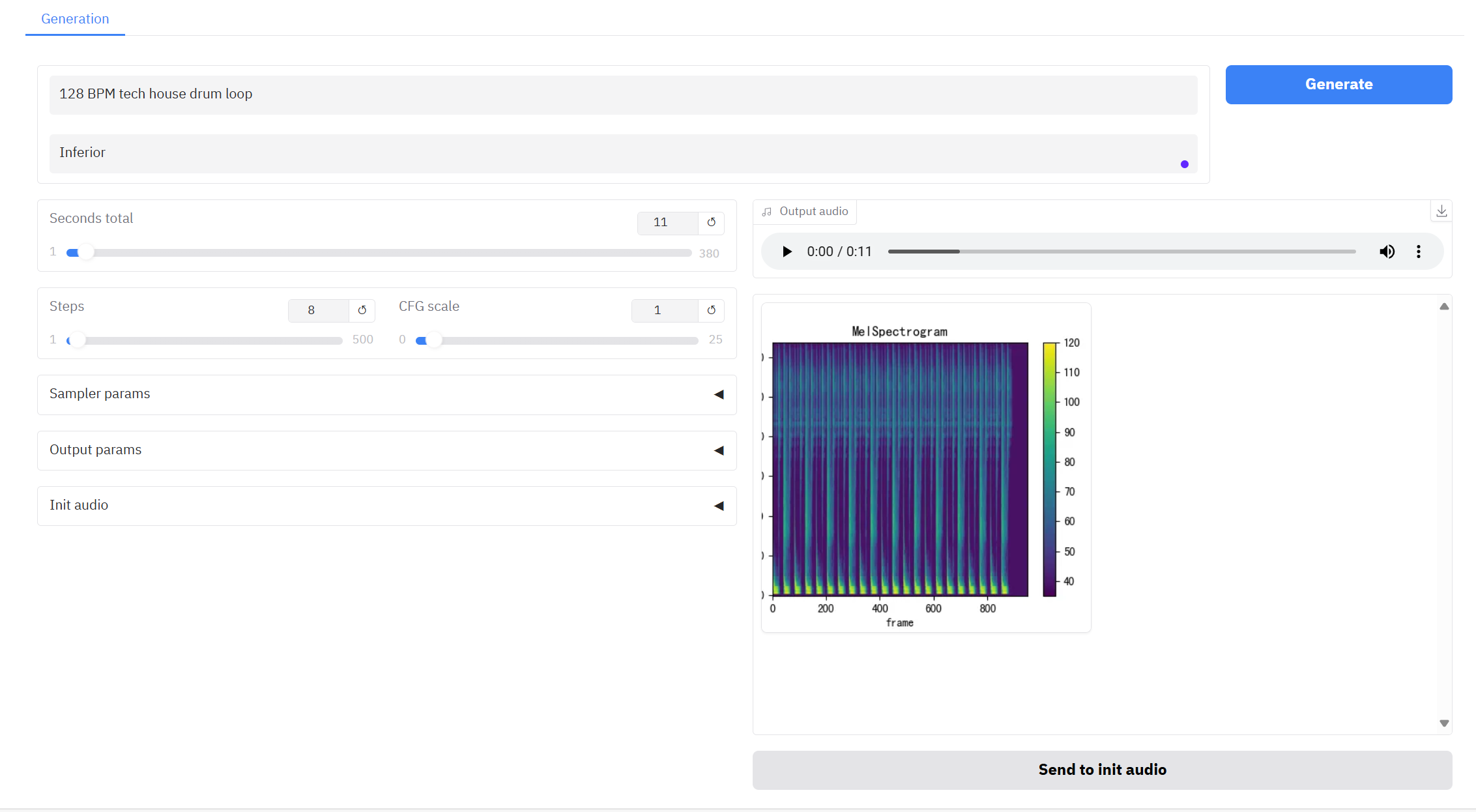
三、运行步骤
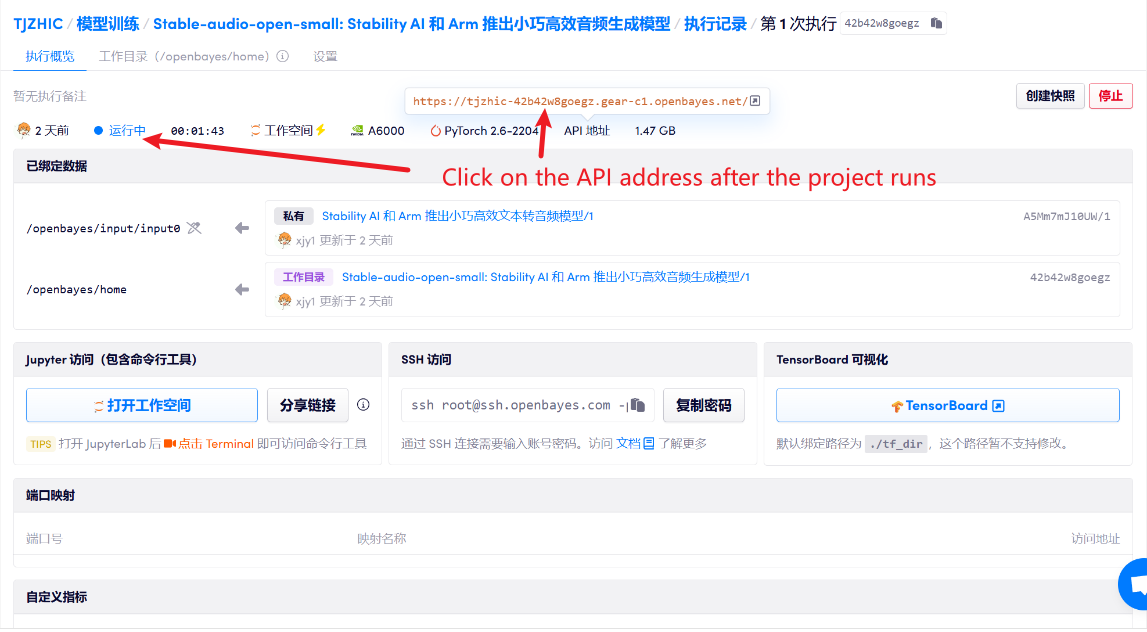
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
2. 进入网页后,即可与模型展开对话
提示:参数设置不恰当可能生成噪声。使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
使用步骤
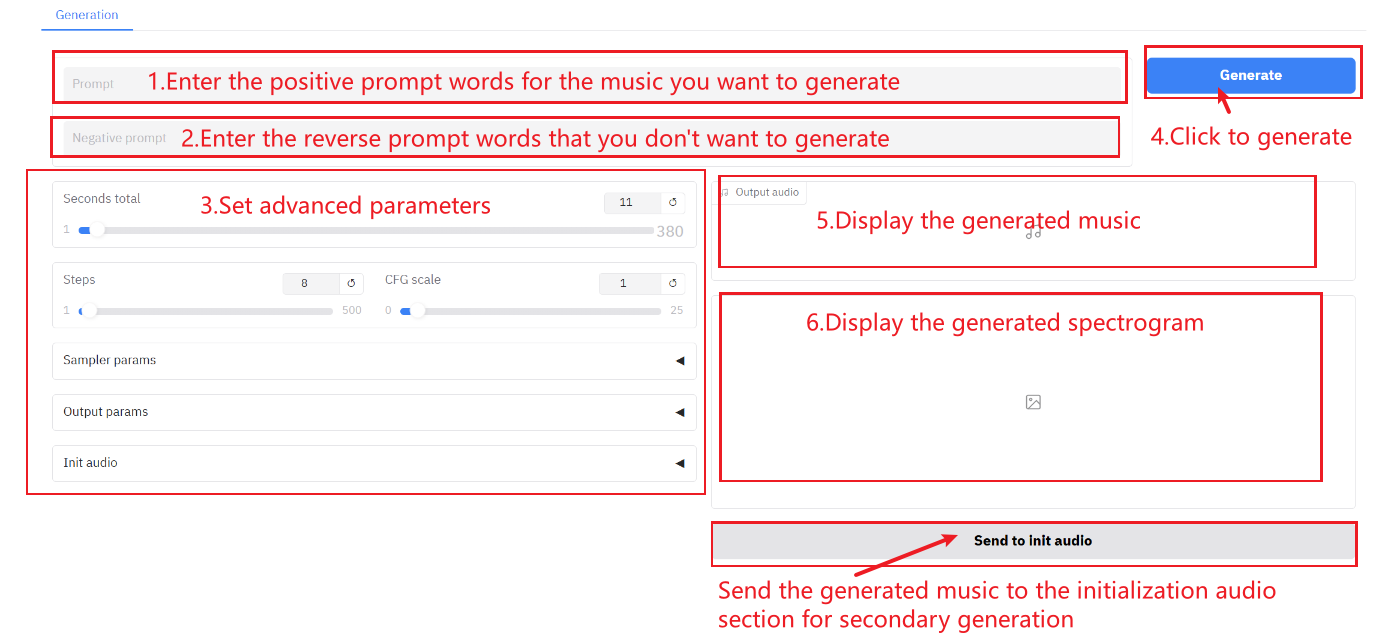
参数说明:
- Seconds total: 生成音频的总时长。
- Steps: 示模型的迭代次数或推理过程中的步数, 代表模型用于生成结果的优化步数。更高的步数通常会生成更精细的结果,但可能增加计算时间。
- CFG Scale: 用于控制生成模型中条件输入对生成结果的影响程度, 越高越遵循文本描述。
Sampler params
- Seed: 随机种子,保持不变可重复生成相同的结果。
- CFG interval min: 设置条件引导在扩散过程的时间起始点。
- CFG interval max: 设置条件引导在扩散过程的时间终止点。
- CFG rescale amount: 通过动态调整条件强度防止数值溢出,提升高条件强度下的生成稳定性。
Output params
- File format: 选择输出文件格式。
- File naming: 选择输出文件命名方式。
- Spec Preview Every: 选择是否预览频谱图。
- Cut to seconds total: 是否裁剪到指定时长。
- Autoplay: 是否自动播放。
- Infinite Radio: 是否循环生成。
- Auto Download: 是否自动下载。
Init audio
- Init audio: 选择初始化音频文件,用于生成新的音频。
- Init noise level: 初始化噪声级别,用于控制生成音频的初始随机性。
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。