Command Palette
Search for a command to run...
ComfyUI LanPaint 图像修复工作流教程
一、教程简介

LanPaint 是一款开源图像局部修复工具,于 2025 年 3 月发布。它采用创新的推理方法,无需额外训练即可适配多种稳定扩散模型(包括自定义模型),从而实现高质量的图像修复。相较于传统方法,LanPaint 提供了一种更轻量级的解决方案,显著降低了对训练数据和计算资源的需求。相关论文成果为 Lanpaint: Training-Free Diffusion Inpainting with Exact and Fast Conditional Inference 。
本教程采用资源为单卡 RTX 4090 。
该项目提供了 8 个样例工作流,总共使用了下列模型文件:
- animagineXL40_v40pt.safetensors
- fux1-dev-fp8.safetensors
- juggernautXL_juggXlByRundiffusion.safetensors
- clip_l_hidream.safetensors
- clip_g_hidream.safetensors
- flux_vae.safetensors
- hidream-i1-full-Q6_K.gguf
- t5-v1_1-xxl-encoder-Q4_K_S.gguf
- Meta-Llama-3.1-8B-Instruct-Q4_K_M.gguf
二、项目示例
所有示例都使用随机种子 0 生成 4 张图像的批次,以便进行公平比较。
HiDream 示例:InPaint(LanPaint K Sampler,5 个思考步骤)
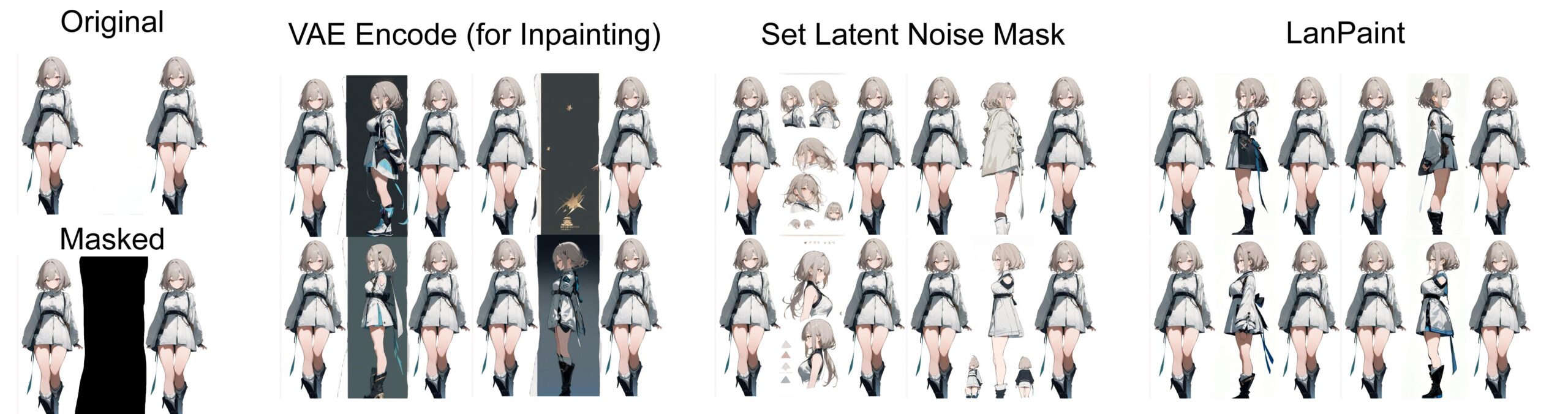
字符一致性(侧视图生成)(LanPaint K Sampler,5 个思考步骤)

Paint 中的助焊剂模型(LanPaint K Sampler,5 个步骤的思考)

三、功能列表
- 🎨零训练修复:可立即与任何 SD 模型(带/不带 ControlNet)和 Flux 模型配合使用!甚至你自己训练的自定义模型。
- 🛠️简单集成:与标准 ComfyUI KSampler 相同的工作流程。
- 🎯 真正的空白生成:无需将传统方法中使用的默认去噪设置为 0.7(在蒙版中保留 30% 的原始像素):100% 新内容创建,无需覆盖现有内容。
- 🌈 不仅仅是 inpaint:您甚至可以将其用作生成一致字符的简单方法。
四、运行步骤
1. 启动容器后点击 API 地址即可进入 Web 界面
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。
2. 功能演示
使用步骤
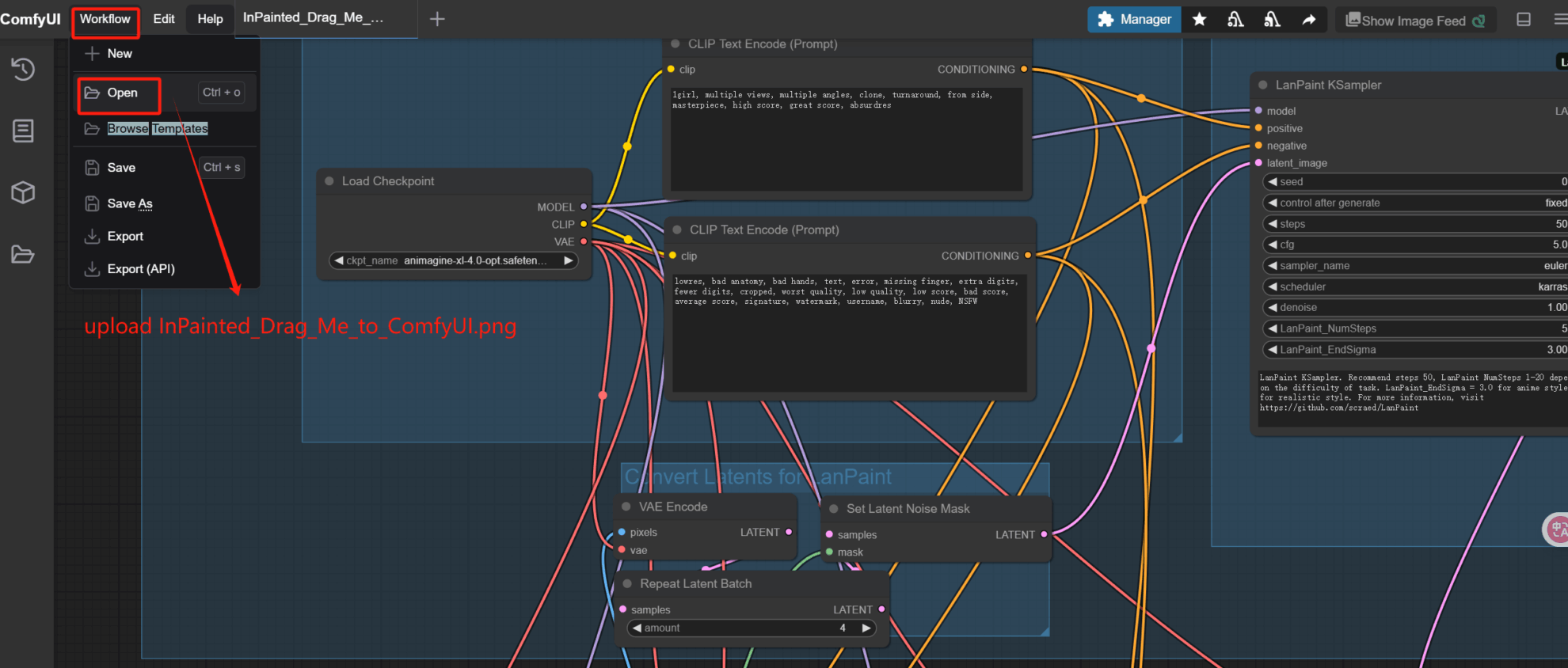
1. 导入工作流
本项目内置了 8 个样例工作流。
工作流下载地址:样例工作流下载
2. 本教程 Demo 已将工作流搭建好,仅需修改「CLIP Text Encode(Prompt)」,
并分别在「Original Image」和「Mask Image for inpainting」节点处上传对应的图片,
即可点击「run」来运行。下面步骤以 example 6 为例,首次克隆需要手动打开文件夹内的工作流进行加载,将 InPainted_Drag_Me_to_ComfyUI.png 打开到 ComfyUI 中,加载工作流程。
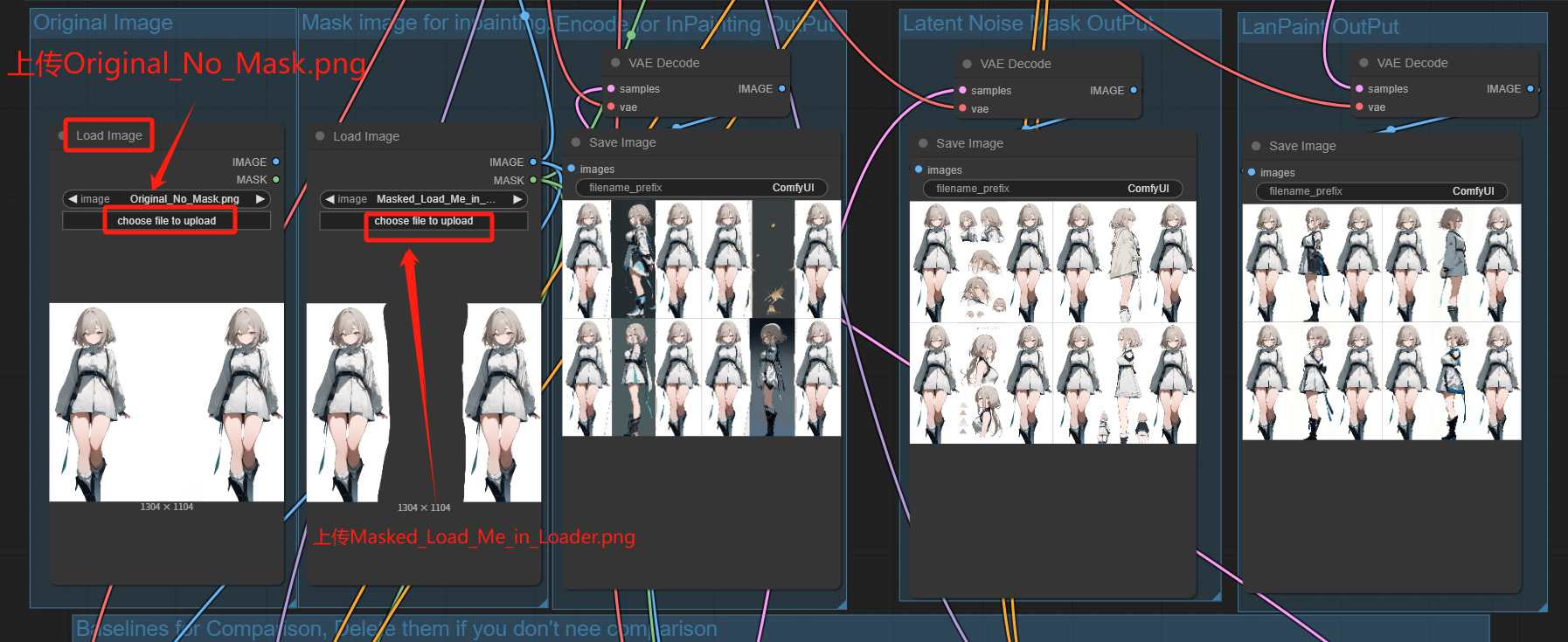
3. 将 Original_No_Mask.png 上传到 Load image 组(最左侧)中的 Original Image 节点(左一)。
4. 将 Masked_Load_Me_in_Loader.png 上传到 Mask image for inpainting 组中的 Load image 节点(左二)。
5. 本教程已添加了 8 个样例工作流所需的模型文件并且每个工作流会自行选择模型,您可以跳过此步骤,执行下一步(注意:若使用非样例工作流,请根据需求自行选择或下载模型)。
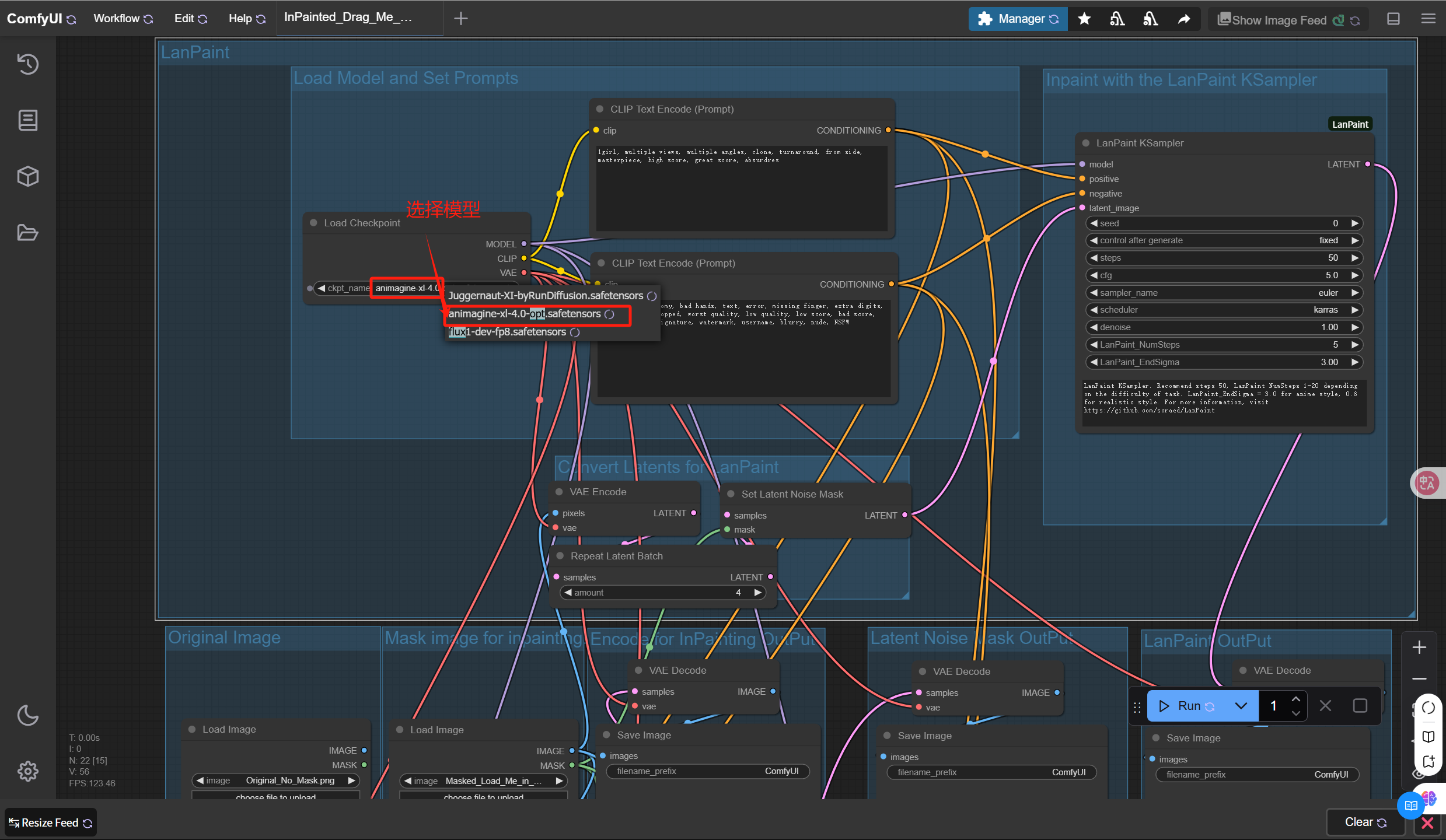
6. 设置基本采样器的参数,项目已设置好默认参数,若您无需修改参数,可以跳过此步骤,执行下一步。

简化的界面,推荐使用默认设置:
- Steps:建议 50+。
- LanPaint NumSteps:去噪前的思考次数。建议大多数任务使用 5 次。
- LanPaint EndSigma:噪音等级低于此等级时,思维将被禁用。建议写实风格设置为 0.6(已在 Juggernaut-xl 上测试),动漫风格设置为 3.0(已在 Animagine XL 4.0 上测试)。
LanPaint KSampler(高级)
| 参数 | 范围 | 描述 |
|---|---|---|
Steps | 0-100 | 扩散采样的总步数。步数越高,修复效果越好。建议设置为 50 。 |
LanPaint_NumSteps | 0-20 | 每个去噪步骤的推理迭代次数(“思考深度”)。简单任务:1-2 。困难任务:5-10 |
LanPaint_Lambda | 0.1-50 | 内容对齐强度(越高越严格)。推荐 8.0 |
LanPaint_StepSize | 0.1-1.0 | 每个思考步骤的步长,建议 0.5 。 |
LanPaint_EndSigma | 0.0-20.0 | 噪声级别,低于该级别时,思考将被禁用。建议 0.3 – 3 。值越高速度越快,但可能会损害质量。值越低,思考能力越强,但可能会使输出模糊。 |
LanPaint_cfg_BIG | -20-20 | 对齐蒙版和非蒙版区域时使用的 CFG 比例(正值倾向于忽略提示,负值增强提示)。当提示不重要时,建议使用 8 进行无缝修复(例如肢体、面部)。当提示很重要时,例如角色一致性(即多视图),建议使用 -0.5 |
7. 点击「Run」按钮,生成结果图像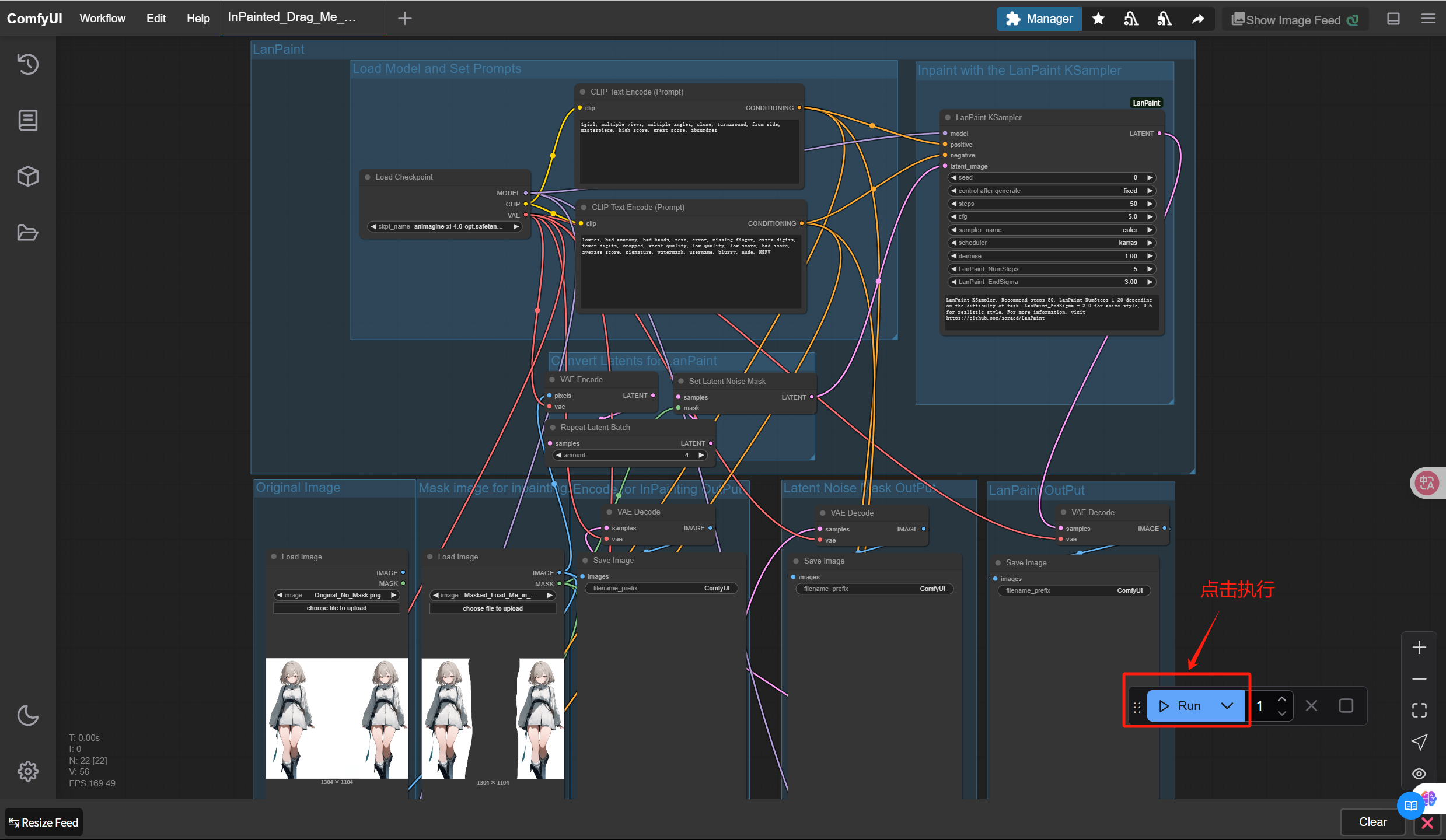
8. 您将通过 3 种方法获得最终的图像- VAE Inpainting 编码(中)
- 设置潜在噪声遮罩(右二)
- LanPaint(最右侧)

五、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
本项目引用信息如下:
@misc{zheng2025lanpainttrainingfreediffusioninpainting,
title={Lanpaint: Training-Free Diffusion Inpainting with Exact and Fast Conditional Inference},
author={Candi Zheng and Yuan Lan and Yang Wang},
year={2025},
eprint={2502.03491},
archivePrefix={arXiv},
primaryClass={eess.IV},
url={https://arxiv.org/abs/2502.03491},
}