HyperAI
Command Palette
Search for a command to run...
ACE-Step:音乐生成基础模型

一、教程简介

ACE-Step-v1-3.5B 是由人工智能公司阶跃星辰(StepFun)与数字音乐平台 ACE Studio 联合研发并于 2025 年 5 月 7 日开源。模型在 A100 GPU 上只需 20 秒即可合成长达 4 分钟的音乐,比基于 LLM 的基线快 15 倍,同时在旋律、和声和节奏指标方面实现了卓越的音乐连贯性和歌词对齐。此外,该模型保留了精细的声学细节,支持高级控制机制,例如语音克隆、歌词编辑、混音和音轨生成。
二、核心功能
多元风格流派
- 支持所有主流音乐风格,可通过短标签/描述文本/使用场景等多种形式输入需求
- 能根据不同类型自动适配乐器组合与风格特征(如爵士乐标配萨克斯风与摇摆节奏)
多语言支持
- 支持 19 种语言输入,性能最优的 10 种语言包括:🇺🇸 英语、🇨🇳 中文、🇷🇺 俄语、🇪🇸 西班牙语、🇯🇵 日语、🇩🇪 德语、🇫🇷 法语、🇵🇹 葡萄牙语、🇮🇹 意大利语、🇰🇷 韩语
器乐表现力
- 支持跨流派器乐生成,能精准还原乐器音色特征(如钢琴的踏板共鸣、吉他的滑弦噪音)
- 可生成包含复杂编曲的多轨音乐,保持声部间的和谐度与律动统一性
- 自动适配乐器演奏技法(如弦乐的颤音、铜管的吐音)
人声表现力
- 支持多种演唱风格(流行唱法、美声、戏腔等)
- 可控制情感表达强度(如压抑的低声吟唱 vs 爆发式高音)
三、运行步骤
1. 启动容器
若显示「Bad Gateway」,这表示模型正在初始化,由于模型较大,请等待约 1-2 分钟后刷新页面。

2. 使用示例
使用指南
使用 Safari 浏览器时,音频可能无法直接播放,需要下载后进行播放。
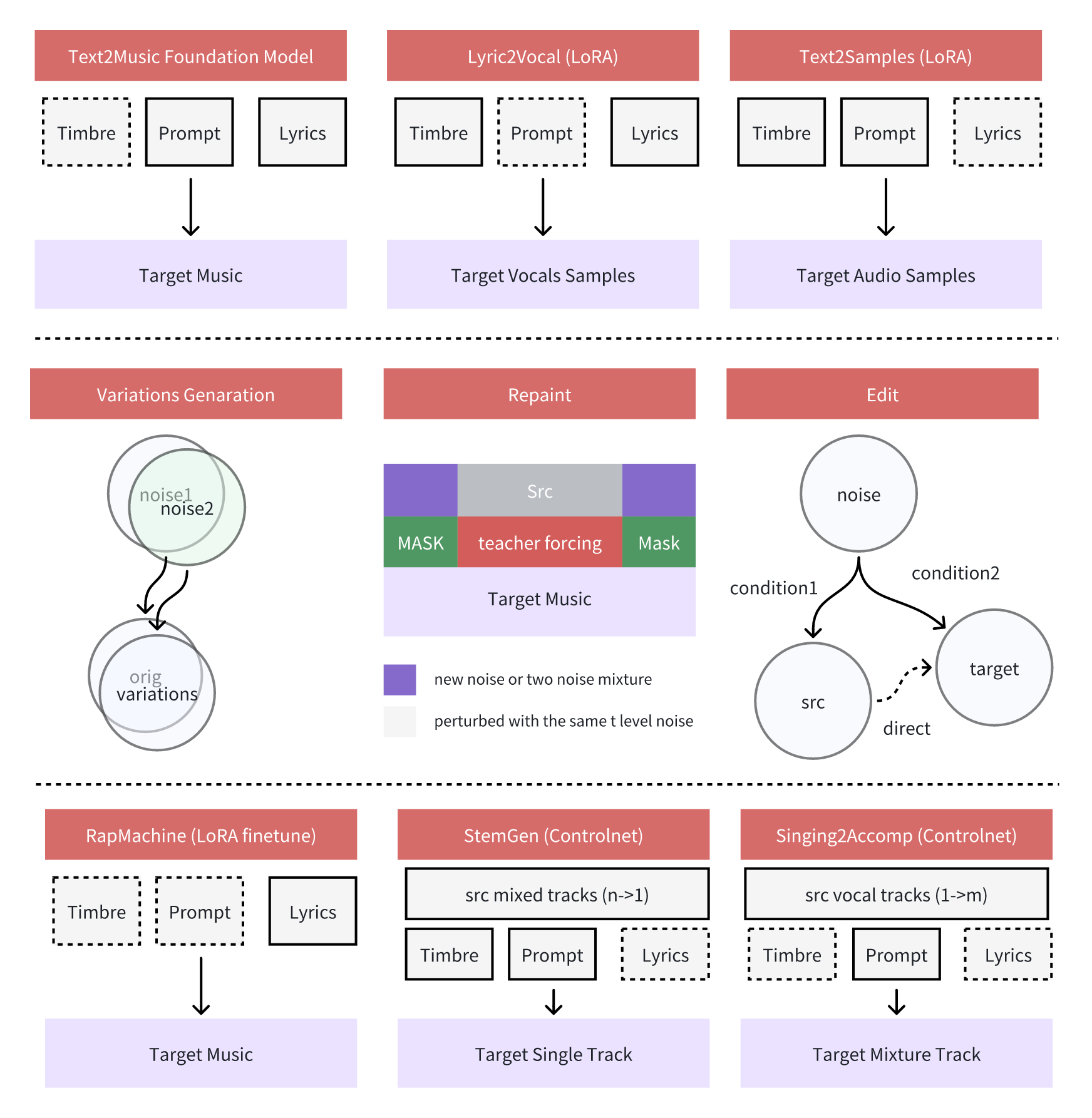
该项目提供多任务创作面板:Text2Music Tab 、 Retake Tab 、 Repainting Tab 、 Edit Tab 和 Extend Tab 。
各模块功能如下:
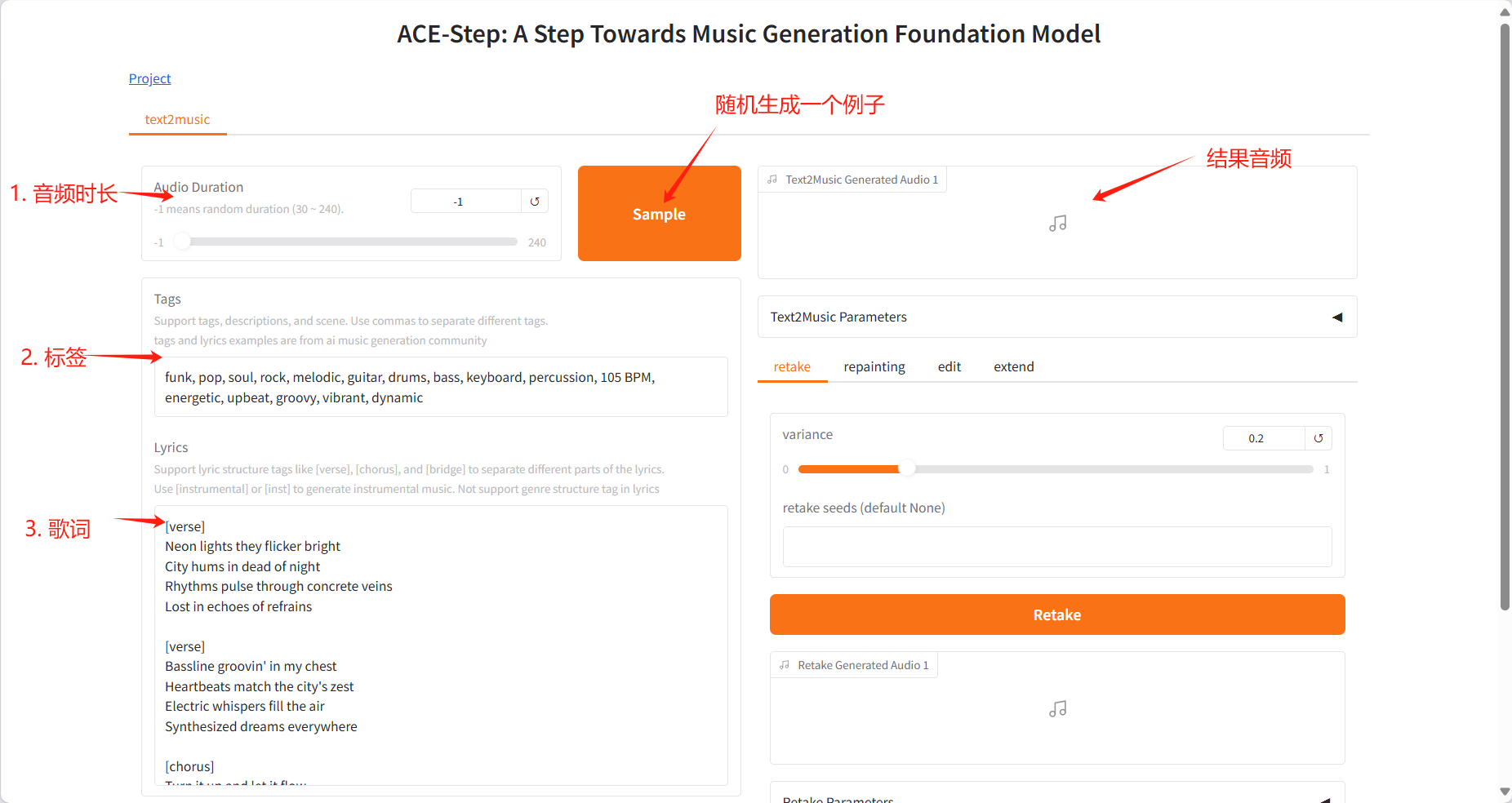
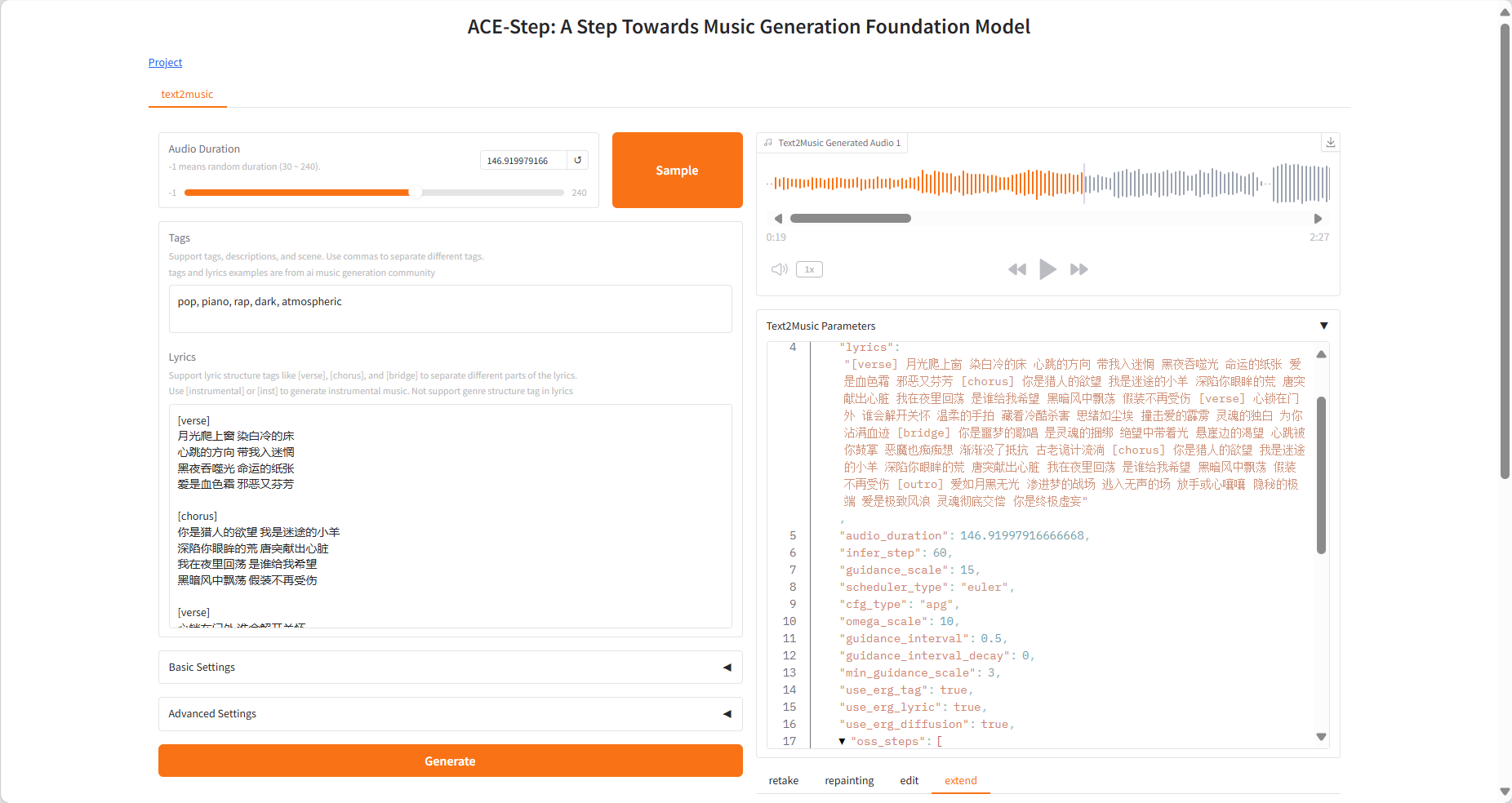
Text2Music Tab
- Input Fields
- Tags:输入描述性标签、音乐流派或场景描述,用逗号分隔
- Lyrics:输入带有结构标签的歌词,如 [verse] 、 [chorus] 、 [bridge]
- Audio Duration:设置生成音频的时长(-1 表示随机生成)
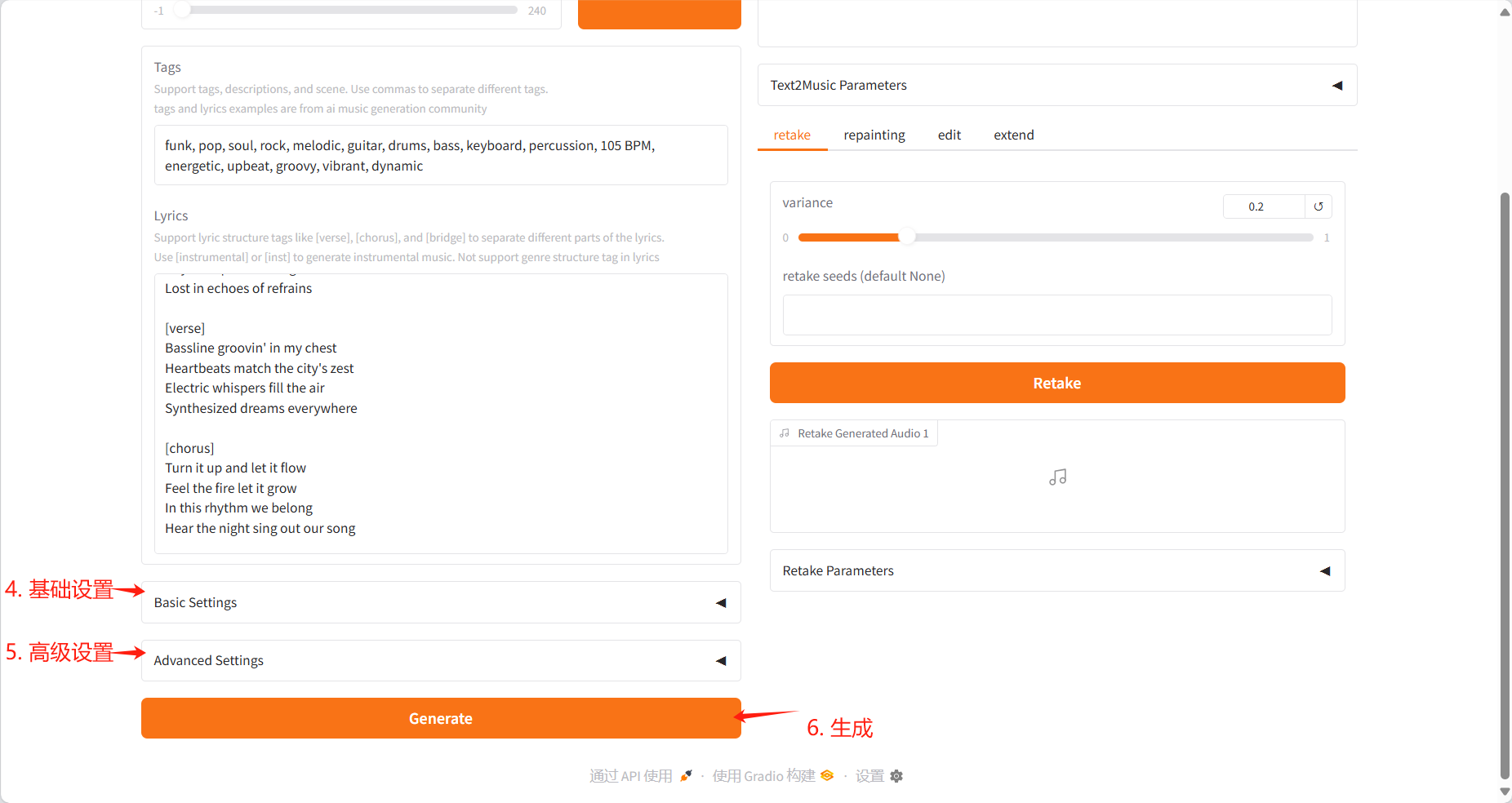
- Settings
- Basic Settings:调整推理步数、指导比例和种子值
- Advanced Settings:微调调度器类型、 CFG 类型、 ERG 设置等参数
- Generation
- 点击「Generate」按钮,根据输入内容创作音乐
生成结果
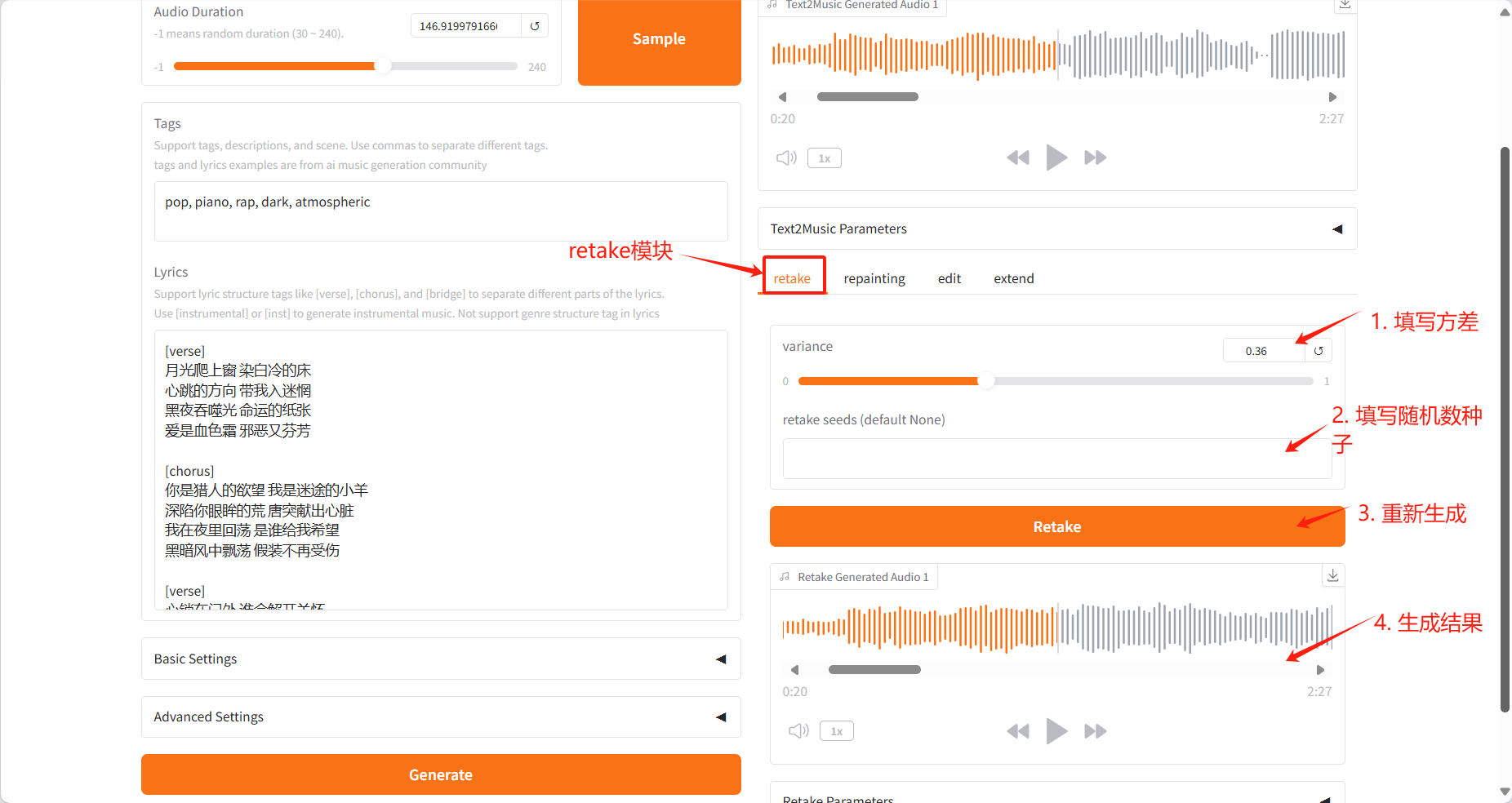
Retake Tab
- 通过不同种子值重新生成音乐并产生细微变化
- 调整变化参数以控制新版本与原版的差异程度
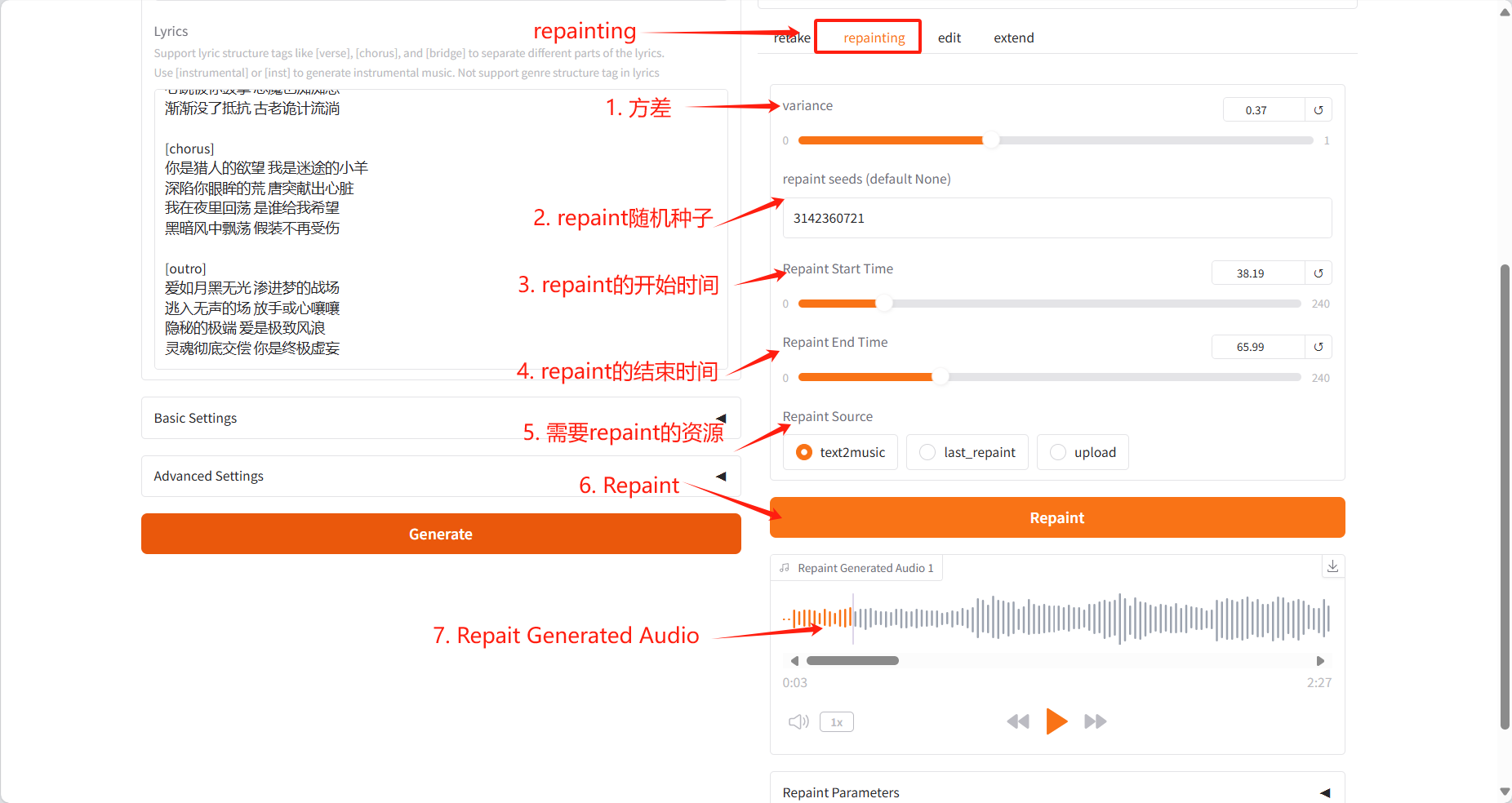
Repainting Tab
- 选择性重新生成音乐的特定段落
- 指定需要重新生成段落的开始和结束时间
- 选择源音频(text2music 、 last_repaint 或 upload)
Edit Tab
- 通过修改标签或歌词来改编现有音乐
- 可选择「only_lyrics」模式(保留原旋律)或「remix」模式(改变旋律)
- 通过调整编辑参数控制对原曲的保留程度

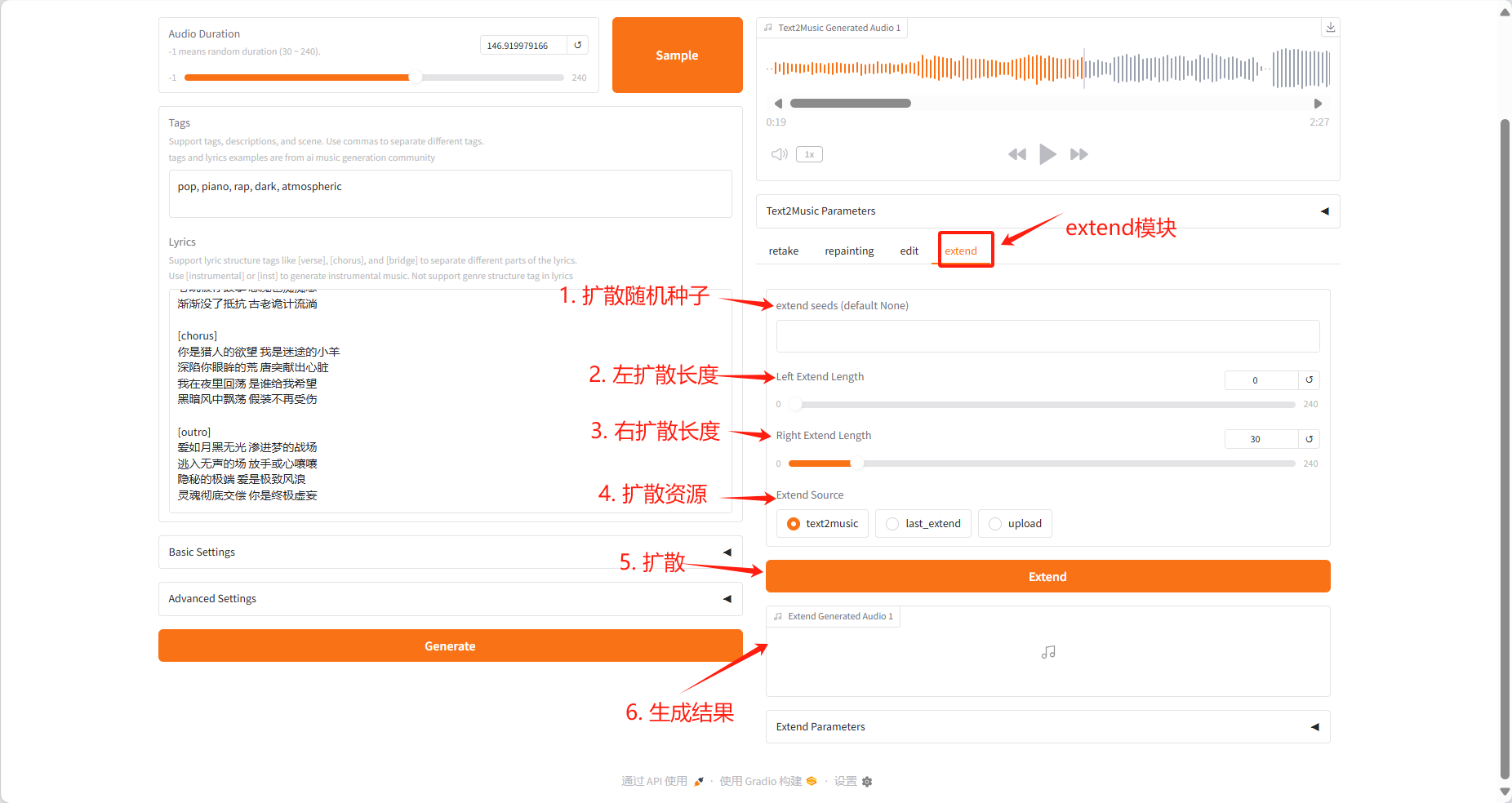
Extend Tab
- 在现有音乐的开头或结尾添加音乐片段
- 指定左右两侧的扩展时长
- 选择需要扩展的源音频
四、交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【SD 教程】入群探讨各类技术问题、分享应用效果↓

引用信息
感谢 Github 用户 SuperYang 对本教程的部署。本项目引用信息如下:
@misc{gong2025acestep,
title={ACE-Step: A Step Towards Music Generation Foundation Model},
author={Junmin Gong, Wenxiao Zhao, Sen Wang, Shengyuan Xu, Jing Guo},
howpublished={\url{https://github.com/ace-step/ACE-Step}},
year={2025},
note={GitHub repository}
}该教程由社区用户贡献,仅供交流学习使用。如内容涉及侵权,请联系邮箱 [email protected] 以便及时审查和下架。