HyperAI
Command Palette
Search for a command to run...
Fish Speech v1.4 声音克隆-文本转语音工具 Demo
教程简介

Fish Speech 的主要功能包括文本转语音、多语言支持、语音定制、高质量音色库以及免费开源等。它适用于多种场景,如内容创作、教育领域、客户服务、辅助工具等。模型还提供了 API 集成和模型微调的支持,使得用户可以根据自己的需求进行定制和优化。
最新版本 1.4 在多语言支持和性能方面取得了重大突破,训练数据量翻倍至 70 万小时,支持 8 种主要语言,包括英语、中文、德语、日语、法语、西班牙语、韩语和阿拉伯语。新版本还引入了即时语音克隆功能,允许用户快速复制特定的语音风格,并提供了灵活的部署选项和 API 服务。
本教程已经将模型与环境部署完毕,大家可根据教程指引直接进行声音克隆或文本转语音任务。
运行方法
1. 首先克隆容器, 按步骤启动容器
2. 复制生成的 API 地址到浏览器即可使用
3. 该教程主要包含 2 个功能:文本转语音和声音克隆
3.1 文本转语音:在「Input Text」输入生成的文本,点击「Generate」即可生成结果

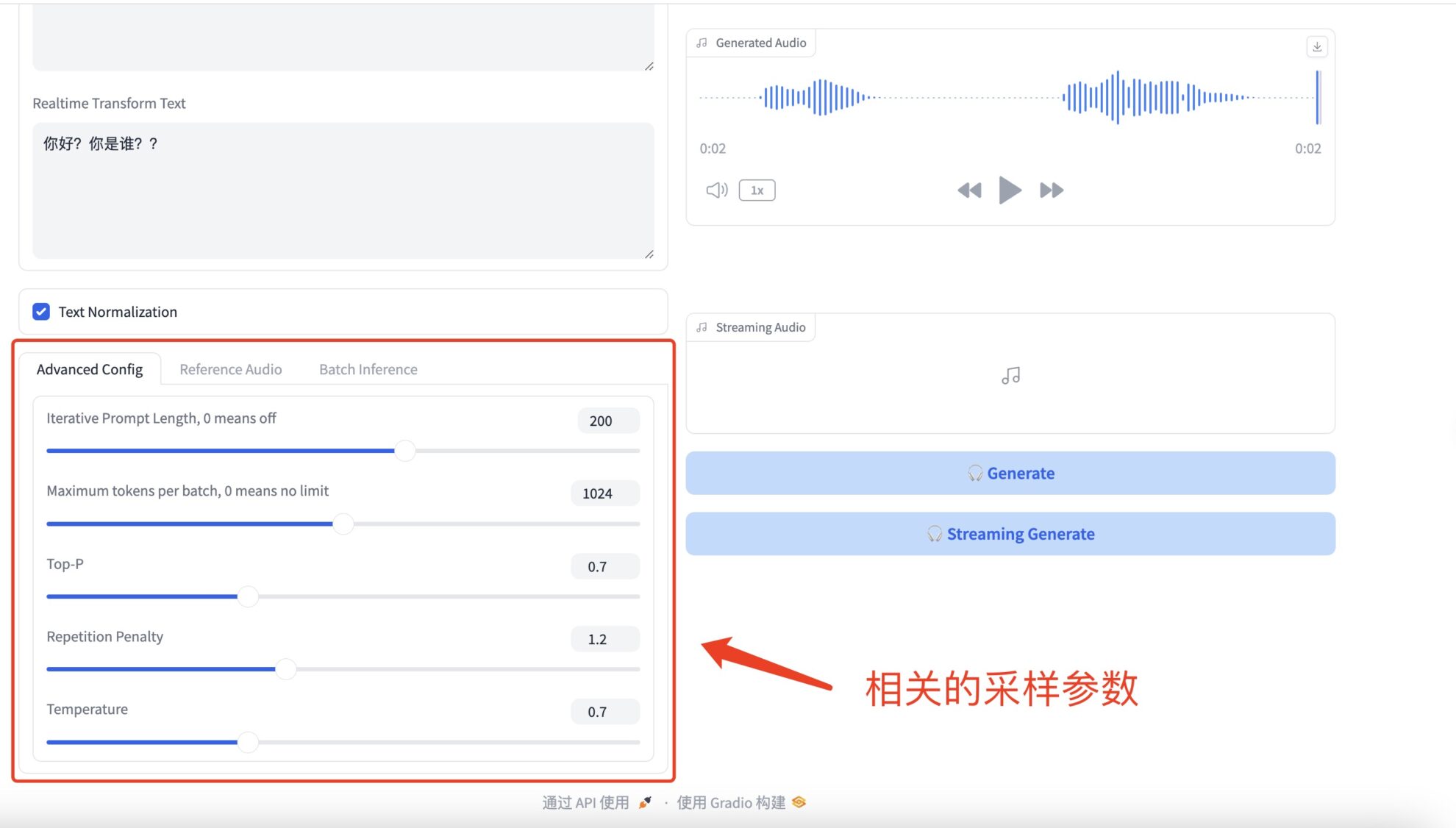
* Advanced Configs
相关的采样参数具体如下:
- 迭代提示长度(Iterative Prompt Length):是指在生成文本时,模型将考虑的前文长度。如果设置为非零值,模型在每一步生成时会考虑最近的指定数量的单词或标记作为上下文。如果设置为 0,则此功能关闭,模型可能会考虑所有可用的上下文或根据其它参数(如模型窗口大小)决定上下文长度。
- 批次最大标记数(Maximum tokens per batch)限定了在每个批次中模型可以生成的最大标记(token)数。标记通常是指词、标点符号等。如果设置为 0,则没有限制,模型将根据需要生成任意长度的文本,或直到达到模型的内部最大长度限制。
- Top-P 又称为核采样或概率采样)是一种文本生成策略,模型在生成每一个新词时只考虑累积概率大于 P 的最小集合的词。这意味着模型会从这个集合中随机选择下一个词,使得生成的文本多样性增加,同时避免生成低概率的不相关词汇。
- 重复惩罚(Repetition Penalty)用于减少生成文本中的重复内容。当模型倾向于重复已生成的词或短语时,应用此参数可以降低这些词的选择概率。具体做法是将已经生成的词的概率分数进行调整(通常是降低),从而鼓励模型选择不同的词。
- 温度(Temperature)控制生成文本的随机性。
3.2 声音克隆:选择「Reference Audio」并点击「Enable Reference Audio」,
上传「Reference Audio(参考音频)」,以及「Reference Text(参考文本)」,在「Input Text」输入生成的文本,点击「Generate」即可生成声音克隆结果

4. 其他参数说明
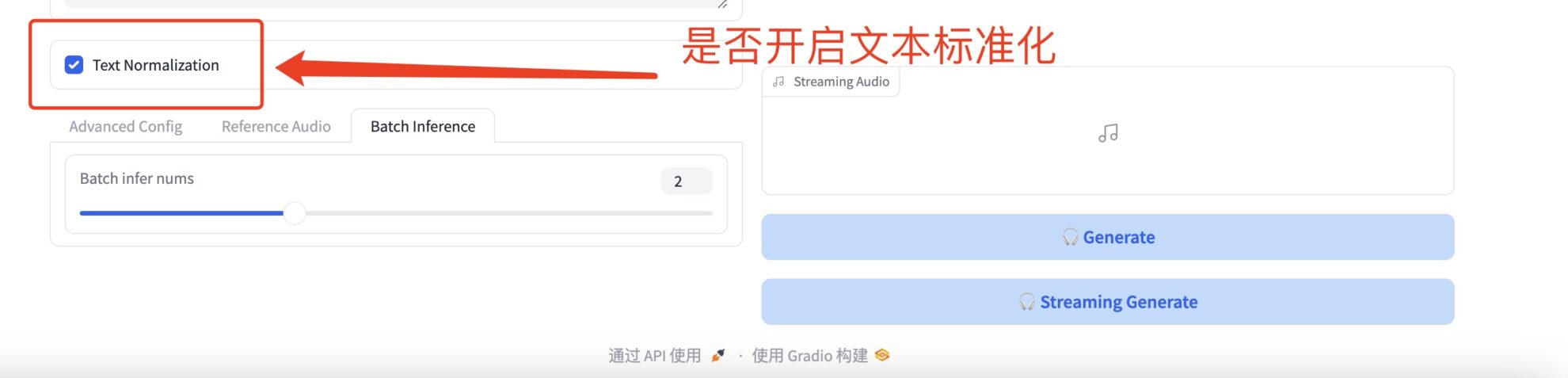
* Text Normalization
是否开启文本标准化(例如日期、固话、金钱等等)
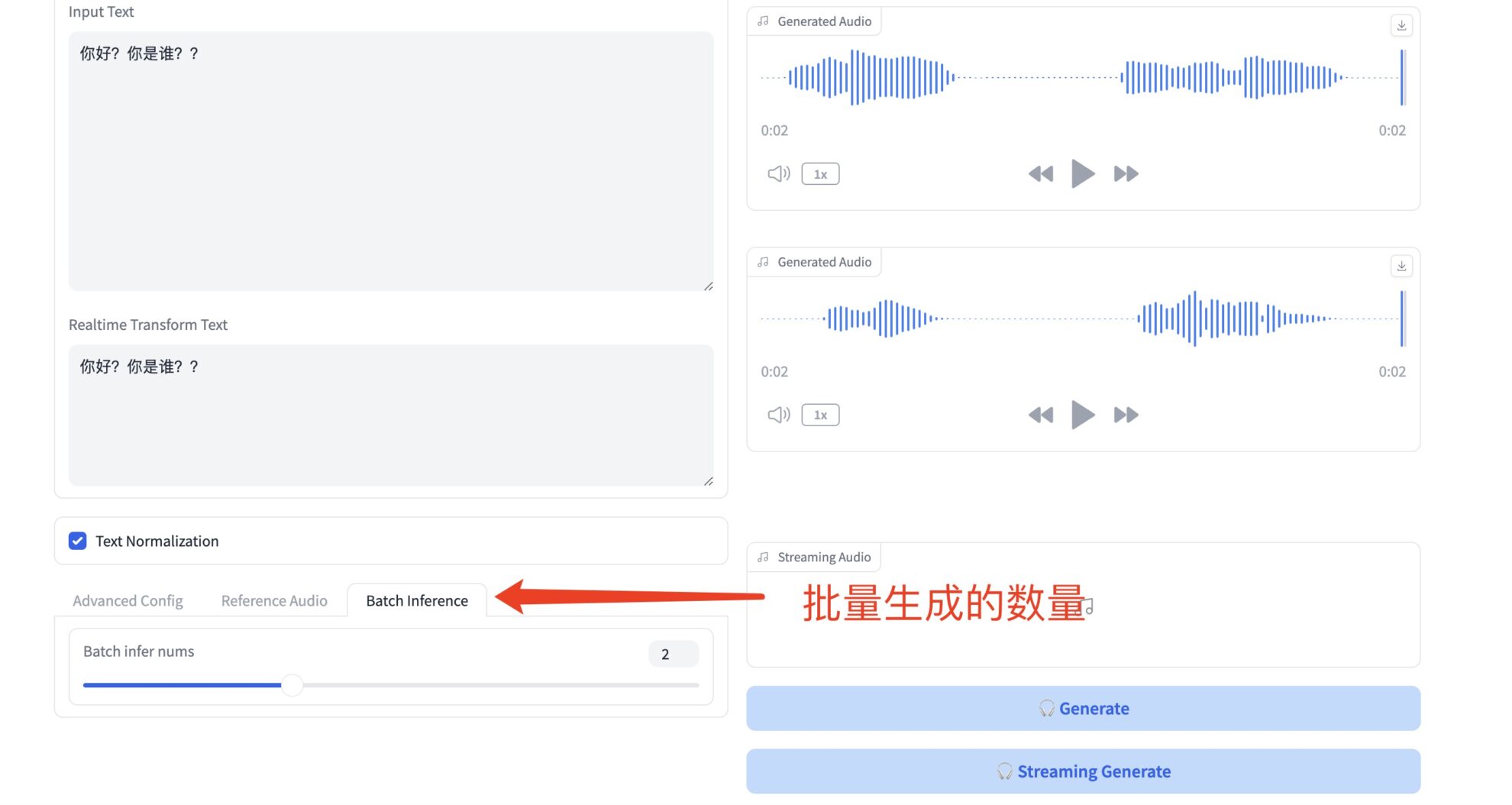
* Batch Inference
设置生成语音数量
交流探讨
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【教程交流】入群探讨各类技术问题、分享应用效果↓

本笔记本由社区用户贡献,仅用于教育和信息传播目的。如果任何内容涉及版权侵权,请通过 [email protected] 联系我们,我们将及时审核并删除。