Command Palette
Search for a command to run...
FLUX.1-schnell 文生图 Demo


教程简介
FLUX.1 是一个 120 亿个参数的大模型,能够从文本描述中生成图像。为文本到图像合成定义了图像细节、及时遵守、风格多样性和场景复杂性的全新最先进水平。 该教程使用的是 FLUX.1 [schnell] 版本模型,模型与环境部署完毕,大家可根据教程指引直接使用大模型进行推理对话。
由于模型较大,所以需要使用 A6000 运行,无法使用单卡 4090 启动。
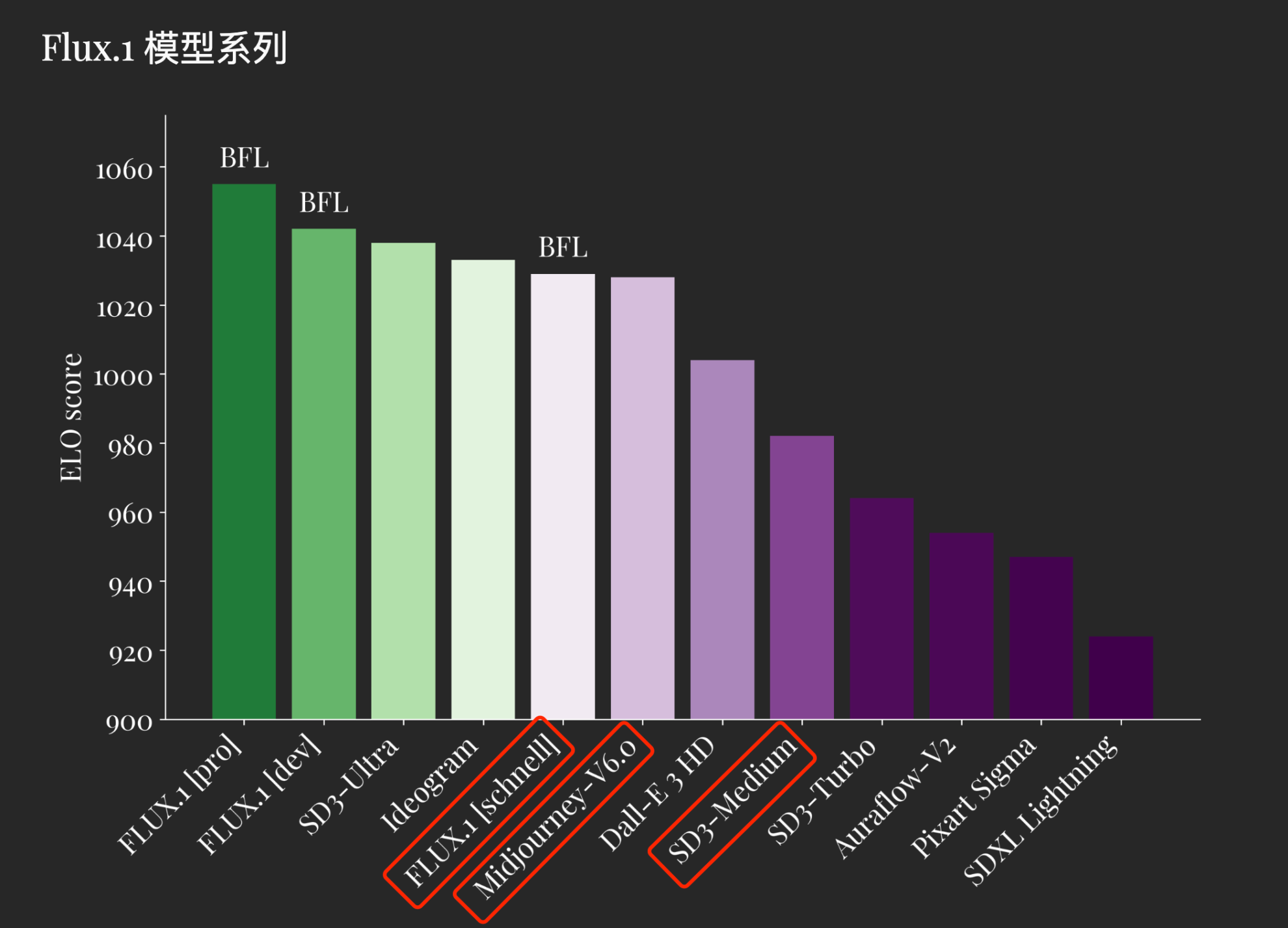
FLUX.1 定义了图像合成领域的最新技术。 FLUX.1 [pro] 和 [dev] 在以下每个方面都超越了 Midjourney v6.0 、 DALL·E 3 (HD) 和 SD3-Ultra 等热门模型:视觉质量、快速跟进、尺寸/长宽变化、排版和输出多样性。 FLUX.1 [schnell] 是迄今为止最先进的 few-step 模型,其表现不仅优于同类竞争对手,还优于 Midjourney v6.0 和 DALL·E 3 (HD) 等强大的非蒸馏模型。
为了在可访问性和模型功能之间取得平衡,FLUX.1 有三种版本:FLUX.1 [pro] 、 FLUX.1 [dev] 和 FLUX.1 [schnell]:
FLUX.1 [pro]:FLUX.1 的最佳功能,提供最先进的性能图像生成,具有顶级的即时跟踪、视觉质量、图像细节和输出多样性。不可商用,需要联系研究团队进行使用。 FLUX.1 [dev]:FLUX.1 [dev] 是一种开放权重、指导提炼的模型,适用于非商业应用。 FLUX.1 [dev] 直接从 FLUX.1 [pro] 提炼而来,具有相似的质量和及时遵守能力,同时比同等大小的标准模型更高效。 FLUX.1 [dev] 权重可在 HuggingFace 上使用,并可直接在 Replicate 或 Fal.ai 上试用。不可商用。 FLUX.1 [schnell]:该模型是为本地开发和个人使用量身定制的。 FLUX.1 [schnell] 在 Apache2.0 许可下公开可用。
关键特性
- 尖端的输出质量和有竞争力的提示以下,匹配闭源替代品的性能。
- 使用潜在对抗扩散蒸馏进行训练,FLUX.1 [schnell] 只需 1 到 4 步就可以生成高质量的图像。
- 该模型在 apache-2.0 许可下发布,可用于个人、科学和商业目的。
与其他文生图模型分数对比
部署推理步骤
本教程已经将模型与环境部署完毕,大家可根据教程指引直接使用大模型进行推理对话。具体教程如下:
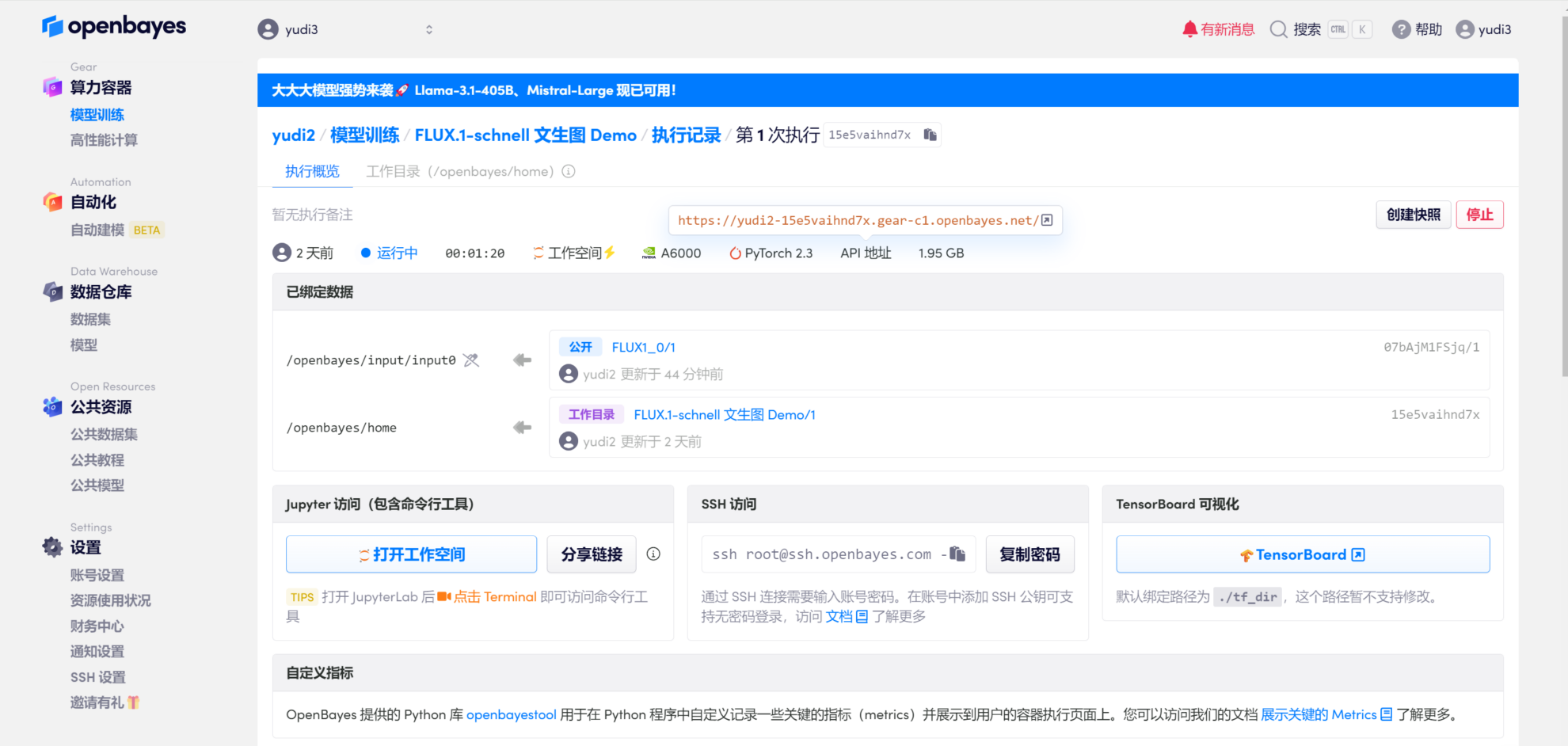
1. 打开界面
点击页面右上角的「克隆」,克隆并启动容器。待资源配置后启动容器,直接点击 API 地址处的链接即可进入 demo 界面
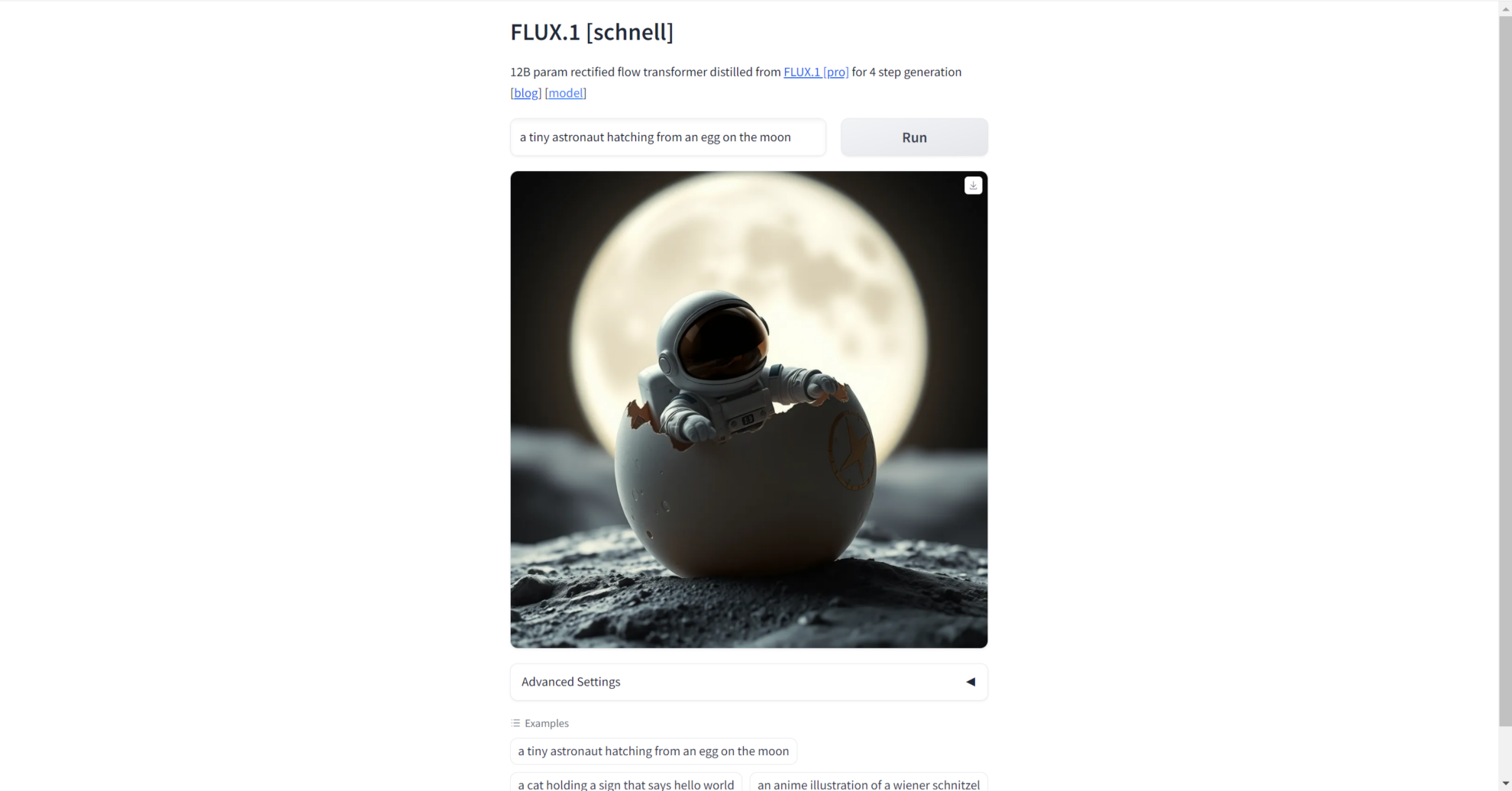
2. 输入提示词
打开界面后,我们可以输入我们希望生成图片的提示词,即可生成对应的高质量图片。我们也可以使用示例里的例子进行验证。
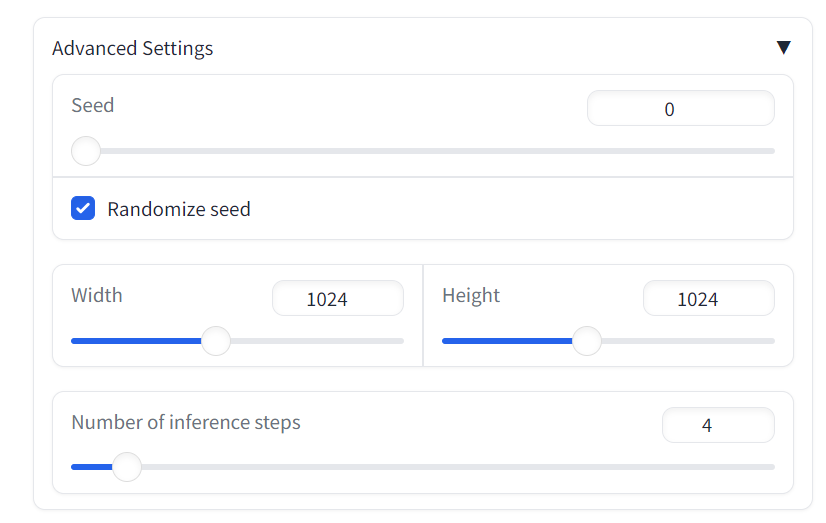
3. 更改参数
其中模型中还有多个可供用户调整的参数。我们可以自主的去调整模型的推理步数,生成图片的长度和宽度等参数
探讨交流
🖌️ 如果大家看到优质项目,欢迎后台留言推荐!另外,我们还建立了教程交流群,欢迎小伙伴们扫码备注【教程交流】入群探讨各类技术问题、分享应用效果↓ 