Command Palette
Search for a command to run...
Arcee Trinity 大型技术报告
Arcee Trinity 大型技术报告
摘要
我们发布Arcee Trinity Large大型稀疏专家混合模型(Mixture-of-Experts)的技术报告,该模型总参数量达4000亿,每token激活参数量为130亿。此外,我们还介绍了Trinity Nano与Trinity Mini两款模型:Trinity Nano总参数量为60亿,每token激活参数量为10亿;Trinity Mini总参数量为260亿,每token激活参数量为30亿。这些模型采用现代化架构,包含交错式局部与全局注意力机制、门控注意力(gated attention)、深度缩放的夹心归一化(depth-scaled sandwich norm),以及用于专家混合的Sigmoid路由机制。针对Trinity Large,我们提出一种新型MoE负载均衡策略,名为“软夹紧动量专家偏置更新”(Soft-clamped Momentum Expert Bias Updates, SMEBU)。所有模型均采用Muon优化器进行训练,且在训练过程中均未出现任何损失峰值。Trinity Nano与Trinity Mini在10万亿token上完成预训练,而Trinity Large则在17万亿token上完成预训练。模型检查点已发布于 https://huggingface.co/arcee-ai。
一句话总结
Arcee AI 与 Prime Intellect 推出 Arcee Trinity Large,这是一款拥有 4000 亿参数的稀疏混合专家(MoE)模型,每 token 激活 130 亿参数,使用 Muon 优化器和一种新颖的“软钳制动量专家偏置更新”(SMEBU)负载均衡策略,在 17 万亿 token 上稳定训练而成。同时推出 Trinity Mini(总计 260 亿参数,激活 30 亿)和 Trinity Nano(总计 60 亿参数,激活 10 亿),二者均在 10 万亿 token 上训练。所有模型均采用交错式局部/全局注意力、门控注意力、深度缩放三明治归一化和 sigmoid 路由机制。检查点可在 https://huggingface.co/arcee-ai 获取。
核心贡献
- 我们推出了 Trinity 系列开源权重的混合专家模型——Trinity Large(总计 4000 亿参数,每 token 激活 130 亿)、Trinity Mini(总计 260 亿参数,激活 30 亿)和 Trinity Nano(总计 60 亿参数,激活 10 亿)——采用交错式局部/全局注意力和门控注意力,以支持高效推理和实际部署需求。
- 针对 Trinity Large,我们提出了一种新颖的 MoE 负载均衡策略“软钳制动量专家偏置更新”(SMEBU),并使用 Muon 优化器训练所有模型,相比 AdamW 实现更高的样本效率和更大的临界批大小,训练过程稳定,无损失尖峰。
- Trinity Nano 和 Mini 在 10 万亿 token 上预训练,Trinity Large 在 17 万亿 token 上训练(来自混合精选/合成语料),所有检查点均开放供企业使用,支持完整数据溯源、许可控制,并可在标准基准上进行评估。
引言
作者利用稀疏混合专家(MoE)架构和高效注意力机制,构建了 Trinity Large——一款 4000 亿参数的开源权重大语言模型,每 token 仅激活 130 亿参数,专为现实企业环境中的可扩展推理设计。以往模型在大规模推理效率方面常表现不佳,尤其在处理长推理链或大上下文时,同时缺乏监管部署所需的透明度。Trinity 通过结合交错式局部/全局注意力、用于上下文理解的门控注意力,以及用于训练稳定性和样本效率的 Muon 优化器,解决了这些问题——同时保持开源权重以支持审计和本地部署。该工作还引入了较小规模的变体(Nano、Mini),作为通向全规模模型的验证步骤,强调实用的可扩展性和硬件感知训练。
数据集

-
作者使用 DatologyAI 精选的两种不同预训练数据混合:Trinity Nano 和 Mini 使用 10 万亿 token 混合数据,Trinity Large 使用 20 万亿 token 混合数据(从中采样 17 万亿)。两种混合均分为三个阶段,随着时间推移逐步增强高质量、领域特定数据(如代码、数学、STEM)的占比。
-
10 万亿混合数据复用 AFM-4.5B 数据集,并增加了大量数学和代码内容。Trinity Large 的 20 万亿混合数据包含最先进的编程、STEM、推理和多语言数据,覆盖包括阿拉伯语、中文、西班牙语和印地语在内的 14 种语言。
-
重要组成部分是合成数据生成:通过基于 BeyondWeb 的改写技术生成超过 8 万亿 token。其中包括 6.5 万亿合成网页 token(通过格式/风格/内容重构)、1 万亿多语言 token 和 8000 亿合成代码 token——全部源自高质量种子文档,并增强其多样性和相关性。
-
数据处理流水线在基于 Ray 和 vLLM 的 Kubernetes 可扩展基础设施上运行,支持在异构 GPU 集群上高效生成。
-
数据按三个阶段处理,混合比例逐步调整:后期阶段增强数学和代码内容,并在每类数据中优先选择更高质量、更相关的样本。分词采用在线序列打包,文档缓冲以支持高效批处理。
-
对于 Trinity Large,作者在第三阶段引入“随机顺序文档缓冲区”(RSDB),以减少长文档导致的批内相关性。RSDB 从已分词文档缓冲区中随机采样,提升独立同分布采样效果,降低批异质性而不丢弃 token。
-
RSDB 每 GPU 使用 8192 的缓冲区大小(配 4 个工作进程),高效填充以维持性能。相比顺序打包,RSDB 将 BatchHet 降低 4.23 倍,步间损失方差降低 2.4 倍,带来更稳定的训练和更少的梯度噪声。
-
作者通过 BatchHet(衡量每步最大与平均微批损失差异的指标)衡量批不平衡,并表明 RSDB 显著提升训练稳定性,甚至在损失方差控制上优于更大批大小的基线。
方法
作者采用仅解码器的稀疏混合专家(MoE)Transformer 架构,专为三个模型规模(Trinity Nano、Mini、Large)的高效扩展和稳定训练设计。核心框架整合了交错式局部/全局注意力、门控注意力、深度缩放三明治归一化和基于 sigmoid 的 MoE 路由。每个 Transformer 层遵循一致模式:输入归一化、子层计算(注意力或 MoE)、输出归一化,并全程使用残差连接。
请参考框架图以直观了解层结构。注意力模块首先对输入应用 RMSNorm,接着进行查询、键、值的线性投影。QK 归一化用于稳定注意力 logits,尤其在使用 Muon 优化器时。采用分组查询注意力(GQA)以减少 KV 缓存内存,通过 j(i)=⌊i⋅hqhkv⌋ 将多个查询头映射到单个键/值头。局部层使用带旋转位置编码(RoPE)的滑动窗口注意力,全局层则省略位置编码(NoPE),局部与全局层比例为 3:1。门控注意力在注意力后应用,使用 sigmoid 门控 gt=σ(WGxt) 调制注意力输出,再进行最终线性投影,以提升长上下文泛化能力并减少训练不稳定性。
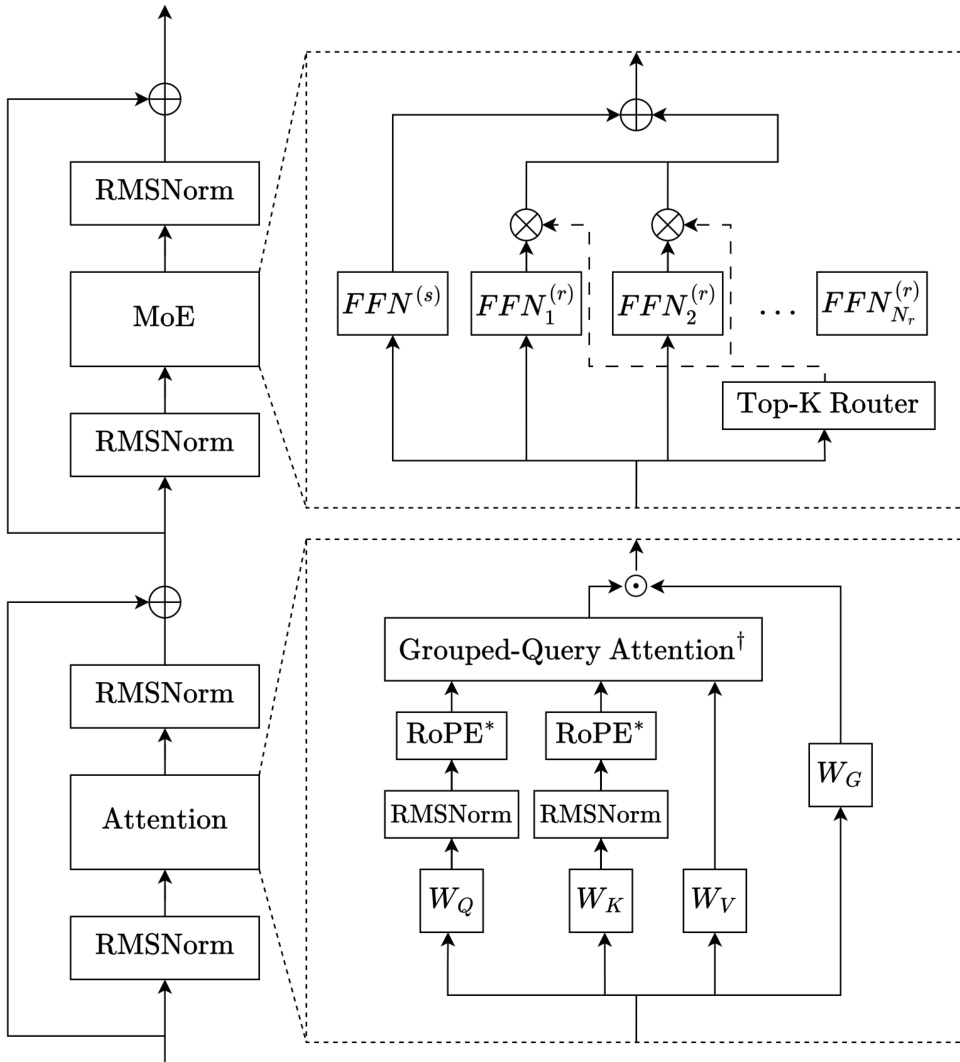
MoE 模块遵循 DeepSeekMoE 设计,包含一个始终激活的共享专家和多个路由专家,激活函数为 SwiGLU。路由器计算 sigmoid 分数 si,t=σ(ut⊤ei),经归一化后与专家偏置 bi 结合以选择 Top-K 专家。门控分数 gi,t 从路由器分数中导出(不含偏置),确保专家偏置更新解耦。对于 Trinity Mini 和 Nano,负载均衡通过无辅助损失的更新和重新中心化的专家偏置实现。对于 Trinity Large,作者引入“软钳制动量专家偏置更新”(SMEBU),以 tanh 缩放、动量平滑的变体替代基于符号的更新,以稳定收敛。归一化违规值 vi=nˉnˉ−ni 通过 v~i=tanh(κvi) 进行软钳制,动量用于抑制收敛附近的振荡。
归一化采用深度缩放三明治 RMSNorm:每个子层的输入和输出均归一化,第二个 RMSNorm 的增益按 1/L 缩放,其中 L 为总层数。最终层在语言建模头前应用 RMSNorm。初始化采用零均值截断正态分布,σ=0.5/d,前向传播时嵌入激活按 d 缩放,以符合高性能 LLM 的既定实践。
实验
Trinity 模型在 GPU 集群上使用 TorchTitan 和 Liger Kernels 等定制框架训练,基础设施针对 H200 和 B300 系统优化,采用 FSDP、EP 和上下文并行以实现可扩展性和容错性。超参数针对每种模型规模使用 Muon 和 AdamW 优化器调优,上下文扩展通过 MK-NIAH 基准验证,Trinity Large 在 256K 长度下达到 0.994,在 512K 长度下达到 0.976(尽管未在该长度训练)。训练后包括监督微调和短暂的 RL 微调(使用 prime-rl),得到 Trinity Large Preview,在 MMLU、GPQA Diamond 和 AIME25 上表现具有竞争力,尽管稀疏度更高。在 8xH200 上使用 FP8 量化进行推理测试,显示出强大吞吐量,归功于其稀疏架构和注意力设计。
作者在一系列能力基准上评估 Trinity Large Base,包括编程、数学、常识、知识和推理任务。结果表明,尽管稀疏度更高、激活参数更少,其表现仍与其他开源基础模型相当。模型在 MMLU 和 TriviaQA 上得分优异,但在 GPQA Diamond 上表现较低。编程能力在 MBPP+ 上得分为 88.62,5-shot 提示下 MMLU 得分为 82.58,GPQA Diamond 得分为 43.94,表明高级推理能力仍有提升空间。

Trinity Large Preview 模型在轻量后训练阶段后于多个基准上评估。结果表明其在知识和推理任务上表现强劲,MMLU 得分为 87.21,MMLU-Pro 得分为 75.25。模型在 GPQA Diamond 上得分为 63.32,表明尽管后训练有限,仍具备竞争力的推理能力。MMLU 得分为 87.21,显示强大通识知识;MMLU-Pro 得分为 75.25,表明高级推理能力;GPQA Diamond 得分为 63.32,反映稳健的专家级推理能力。

Trinity Large Base 尽管稀疏度更高,但在编程、数学和知识基准上表现具有竞争力,MBPP+ 得分为 88.62,MMLU 得分为 82.58,但在 GPQA Diamond 上仅为 43.94。轻量后训练后,Trinity Large Preview 在推理和知识能力上有所提升,MMLU 得分为 87.21,MMLU-Pro 得分为 75.25,GPQA Diamond 得分为 63.32,表明即使微调极少,其专家级推理能力也更强。