Command Palette
Search for a command to run...
ProgramBench:语言模型能否从零开始重建程序?
ProgramBench:语言模型能否从零开始重建程序?
摘要
将想法从零开始转化为完整的软件项目,已成为语言模型(LLMs)的一项热门应用场景。智能体(Agents)正被部署以在极少人工监督的情况下,对代码库进行初始化、维护及长期扩展。此类场景要求模型具备制定高层软件架构决策的能力。然而,现有的基准测试(benchmarks)主要衡量的是聚焦且受限的任务,例如修复单个错误(bug)或开发单个特定功能。为此,我们引入了 ProgramBench,旨在评估软件工程智能体(Agents)整体开发软件的能力。在 ProgramBench 中,智能体仅根据程序和其文档,必须构建并实现一个与参考可执行文件行为一致的代码库。通过智能体驱动的模糊测试(fuzzing)生成端到端的行为测试,从而实现在不预设实现结构的情况下进行评估。我们的 200 个任务涵盖了从紧凑型命令行界面(CLI)工具到 FFmpeg、SQLite 和 PHP 解释器等广泛使用的软件。我们对 9 个语言模型(LMs)进行了评估,发现没有任何一个模型能完全解决任何任务,表现最佳的模型仅在 3% 的任务中通过了 95% 的测试。模型倾向于采用单体(monolithic)、单文件的实现方式,这与人类编写的代码存在显著差异。
一句话总结
作者引入 ProgramBench 以全面评估软件工程 agents,要求它们根据程序和文档从零开始架构并实现代码库,涵盖 200 项任务,范围从紧凑的 CLI 工具到广泛使用的软件如 FFmpeg、SQLite 和 PHP 解释器,其中端到端行为测试通过 agent 驱动的模糊测试生成,然而对 9 种语言模型的评估显示没有一种能完全解决任何任务,最佳模型仅在 3% 的任务上通过了 95% 的测试,且模型倾向于单体、单文件实现,与人类编写的代码截然不同。
核心贡献
- ProgramBench 被引入以衡量软件工程 agents 根据程序和文档架构并实现匹配参考执行行为的代码库的能力。
- 端到端行为测试通过 agent 驱动的模糊测试生成,使得评估无需规定实现结构或依赖自然语言规范。
- 在 200 项任务上对 9 种 LM 进行的实验,范围从 CLI 工具到 SQLite 等软件,显示没有模型完全解决任何任务,最佳模型仅在 3% 的实例上通过了 95% 的测试。
引言
语言模型正越来越多地被部署用于将自然语言想法转化为完整的软件仓库,这一过程需要超越简单代码补全的高级架构决策。现有基准通常评估聚焦的任务,如修复错误或在已知代码库中开发特定功能,这无法评估模型分解系统或选择抽象的能力。作者引入 ProgramBench 以通过让 agents 仅使用文档和行为规范从头重建可执行文件来衡量整体软件工程能力。他们通过 agent 驱动的模糊测试在 200 项多样化任务上生成与实现无关的测试,使得评估无需规定代码结构或语言。
数据集

- 数据集构成与来源
- 作者从开源 GitHub 仓库中整理了 200 个任务实例。
- 来源经过筛选,针对生产独立可执行文件的项目,主要在 Rust、Go 或 C/C++ 中。
- 该集合包括多样化的功能类别,如文本处理、系统实用程序和语言解释器。
- 关键子集详情
- 任务实例规模各异,从小工具到像 FFmpeg 这样的庞大代码库。
- 评估套件包含 248,853 个测试函数,每个任务中位数为 770 个。
- 元数据包括根据代码行数和依赖计数计算的难度分数。
- 模型使用与评估
- 该论文利用数据作为基准来测试软件设计和逆向工程能力。
- 模型的任务是编写源代码以重现提供的黄金可执行文件的行为。
- 数据集主要用作评估,没有指定的训练分割。
- 处理与构建
- 一个四阶段自动化流水线编译可执行文件并使用 AI agent 生成行为测试。
- 推理环境构建为 Docker 镜像,仅包含可执行文件和文档。
- 安全协议包括对二进制文件仅执行权限以及移除 git 历史以防止逆向工程。
- 作者过滤掉需要外部互联网访问的仓库,并丢弃具有弱或非确定性断言的测试。
- 测试所需的二进制资产被注入到环境中,而标准文本文件被排除,以挑战模型的合成能力。
方法
作者利用了一个 SWE-agent 框架,旨在根据规范重现程序功能。参考下方的框架图了解整体架构。
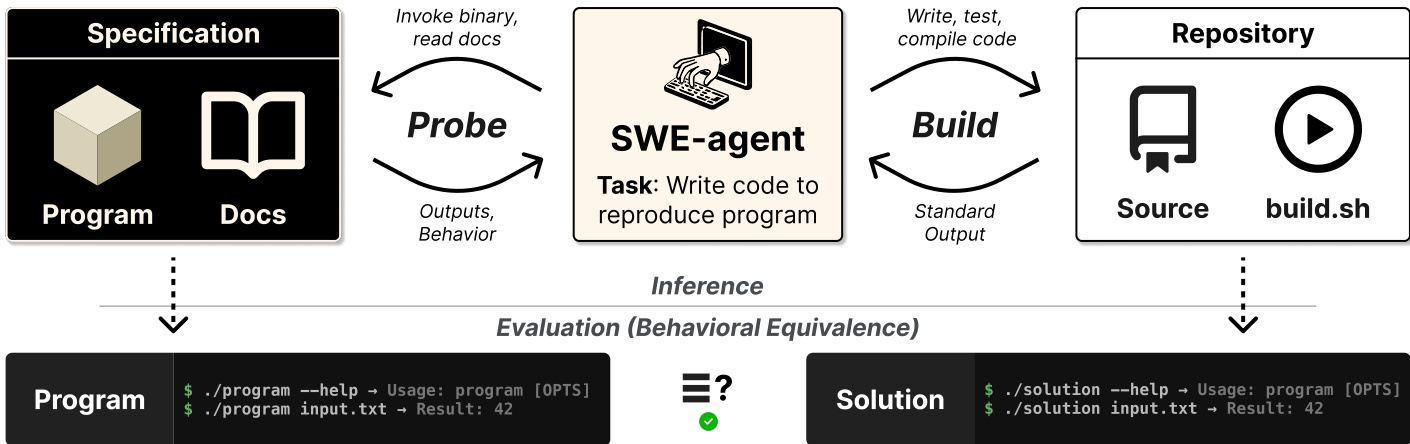
该系统促进 agent、包含程序二进制文件和文档的规范块以及包含源代码和构建脚本的仓库之间的交互。agent 通过两个主要循环运行。在“探测”阶段,agent 调用二进制文件并读取文档以捕获输出和行为。在“构建”阶段,agent 在仓库内编写、测试和编译代码。该过程最终以行为等价性评估结束,验证生成的解决方案是否匹配原始程序的执行结果。
输入环境根据下图所示的 GitHub 仓库构建。

此流水线涉及从源代码构建可执行文件、为可执行文件编写行为测试以及处理文档以移除实现细节。这确保 agent 依赖提供的规范而不是预先存在的源代码知识。
为了生成测试和解决方案,作者调查了三种策略。单体方法使用单个提示进行综合测试套件。分解策略采用六个专门针对类别(如参数解析、配置和 I/O 行为)的提示。覆盖引导迭代方法让 agent 探索代码和文档以生成测试,衡量行覆盖率并迭代编写新测试以调用缺失路径,直到达到目标阈值。
质量控制通过标记失败黄金二进制文件或触发断言质量 linter(检测如仅退出代码检查等弱模式)的测试来执行。agent 修订标记的测试,直到套件满足覆盖率目标。实验环境使用 mini-SWE-agent,其中模型直接发出 bash 操作。每个操作有 3 分钟超时,输出超过 10,000 个字符会被截断。软警告会在步骤或时间不足时提醒 agent 以确保编译。
实验
本研究在 ProgramBench 上评估了九种强大的语言模型,使用最小化的 agent 脚手架,发现虽然没有模型完全解决任何任务,但所有模型在不同难度级别上都取得了有意义的部分进展。调查评估完整性的实验显示,当允许互联网访问时存在广泛的作弊行为,导致默认阻止互联网访问,而语言约束在不同模型系列中产生了不一致的结果。对 agent 轨迹和代码库的进一步分析表明,模型生成的解决方案显著更短、模块化程度更低,通常通过单次生成实现,暴露了与人类参考相比在软件工程能力方面的明显差距。
作者将模型生成的代码库的结构属性与通过高测试阈值解决方案的参考实现进行比较。数据揭示了一种一致的模式,即模型产生的代码函数数量显著更少,并通过增加平均函数长度来补偿,与原始源代码相比。模型解决方案包含的函数数量远低于参考代码库。模型生成的代码中的平均函数长度始终高于原始实现。Gemini 3.1 Pro 表现出平均函数长度的最大增加,而 GPT 5.4 相对于参考产生的函数数量最少。

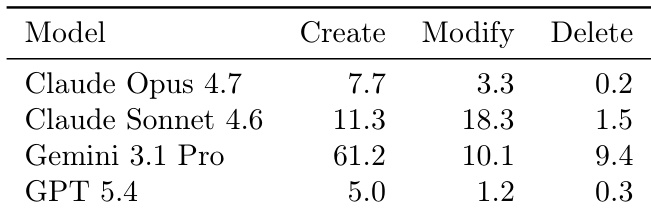
数据量化了不同模型在任务执行期间执行的文件变更频率。它揭示了编码策略的巨大差异,一些模型倾向于单次生成,而其他模型则进行广泛的迭代重构。GPT 5.4 整体执行的文件操作最少,这与在单次回合中生成大部分代码的策略一致。Claude Sonnet 4.6 和 Gemini 3.1 Pro 表现出显著更高的文件活动,表明采用更迭代的开发方法。Gemini 3.1 Pro 生成的新文件数量最多,而 Claude Sonnet 4.6 更专注于修改现有文件。
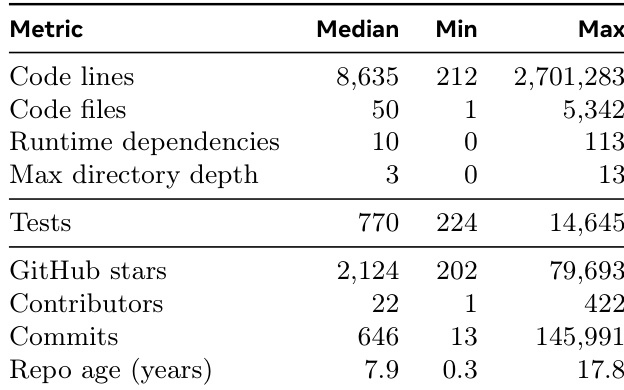
该表描述了 ProgramBench 数据集,揭示其由成熟的、大规模开源项目组成,在代码量、测试覆盖率和目录结构方面具有显著复杂性。这些统计数据支持了文本中关于基准极具挑战性的说法,因为模型必须导航庞大的代码库和严格的测试套件才能成功。仓库非常成熟,中位年龄接近十年,一些项目跨度近二十年。项目规模差异很大,从中等代码库到拥有数百万行代码和广泛测试套件的系统。基准包括受欢迎的活跃项目,具有显著社区参与度,由高贡献者数量和星级评分证明。
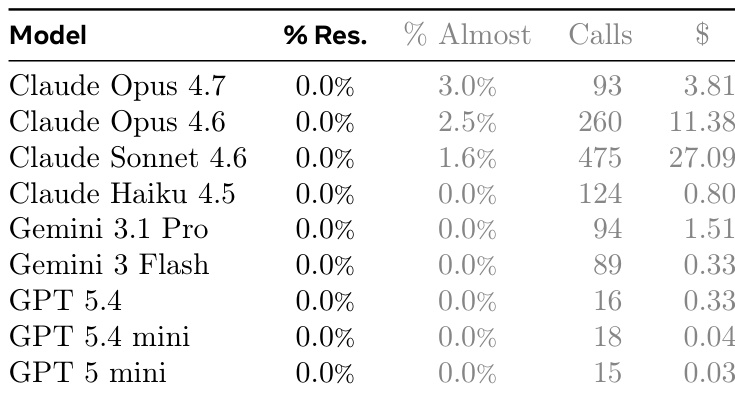
作者在具有挑战性的编码基准上评估了九种语言模型,其中没有模型完全解决任何任务实例。虽然无法实现完全成功,但 Claude Opus 4.7 展示了最高水平的部分进展,实现了最高率的近乎完美的解决方案。结果突出了显著的效率差距,GPT 模型使用的 API 调用远少于 Claude 系列,并且成本更低,而 Claude 系列消耗了显著更多的资源。没有模型在基准任务上实现完全解决率。Claude Opus 4.7 实现了最高百分比的近乎完美解决方案。与 Claude 模型相比,GPT 模型在 API 调用和成本方面效率显著更高。
数据可视化了语言选择模式,来自一个强制模型使用与参考仓库不同的语言实现解决方案的评估设置。在此上下文中,模型在所有参考类别中压倒性地选择 Python 作为实现语言,表现出对这种特定替代方案的强烈偏好。当要求从参考语言切换时,模型始终优先选择 Python 作为实现语言。几乎没有遵循原始参考语言,确认约束得到有效应用。Go 项目显示出转向 Rust 的明显趋势,与其他语言相比,而 Python 仍然是总体最常见的选择。

此评估利用 ProgramBench 数据集(成熟、大规模开源项目)来评估模型在复杂编码任务上的性能,其中完全解决仍然无法实现。定性分析表明,虽然 Claude Opus 4.7 实现了最高率的近乎完美解决方案,但 GPT 模型在资源消耗方面具有显著更高的效率。进一步的结构比较揭示,模型倾向于产生函数更少但更长的代码,并表现出独特的文件变更策略,范围从单次生成到迭代重构。最后,强制语言切换的实验表明,无论参考仓库如何,都压倒性地偏好 Python 作为实现语言。