Command Palette
Search for a command to run...
PERSONAPLEX:用于全双工对话语音模型的语音与角色控制
PERSONAPLEX:用于全双工对话语音模型的语音与角色控制
Rajarshi Roy Jonathan Raiman Sang-gil Lee Teodor-Dumitru Ene Robert Kirby Sungwon Kim Jaehyeon Kim Bryan Catanzaro
摘要
近年来,全双工语音模型的进展使得自然、低延迟的语音到语音交互成为可能。然而,现有模型通常局限于固定角色与固定语音,难以支持结构化、角色驱动的真实应用场景以及个性化交互。在本研究中,我们提出PersonaPlex——一种融合混合系统提示的全双工对话语音模型,该模型结合角色条件化(通过文本提示)与语音克隆(基于语音样本)。PersonaPlex在大规模合成数据集上进行训练,该数据集包含成对的提示与用户-代理对话,由开源大语言模型(LLM)和文本转语音(TTS)模型生成。为在真实场景中评估角色条件化能力,我们扩展了Full-Duplex-Bench基准测试,将其从单一助手角色拓展至多角色客服场景。实验结果表明,PersonaPlex在角色一致性、说话人相似性、响应延迟和自然度等方面均显著优于当前最先进的全双工语音模型及基于混合大语言模型的语音系统。
一句话总结
NVIDIA 研究人员推出了 PersonaPlex,这是一种全双工对话语音模型,通过混合系统提示和语音克隆技术实现动态角色与语音控制,在扩展的多角色客服基准测试中,其在角色遵循度、说话人相似度、延迟和自然度方面均优于当前最先进的双工和基于大语言模型的语音系统。
核心贡献
- PersonaPlex 引入了一种全双工语音到语音模型,结合基于文本的角色条件提示与基于音频的语音克隆,支持零样本语音适配和结构化角色驱动的交互(如客服场景)。
- 该模型在使用开源大语言模型和 TTS 模型生成的大规模合成对话数据集上训练,并在 Service-Duplex-Bench 上评估——这是 Full-Duplex-Bench 的扩展版本,新增了 350 个多角色客服场景(原基准含 400 个问题)。
- 实验表明,PersonaPlex 在角色遵循度、说话人相似度、延迟和自然度方面优于当前最先进的双工和混合大语言模型语音系统,同时保持实时轮转和响应能力。
引言
作者利用近期双工语音模型的进展,构建了 PersonaPlex 系统,支持在实时全双工对话中动态切换角色和克隆语音。先前的双工模型仅限于固定角色和语音,不适合客服或多角色交互等结构化应用;而级联的 ASR-LLM-TTS 系统则牺牲了副语言细微差别和响应速度。PersonaPlex 通过将混合提示(文本用于角色条件,音频用于语音克隆)集成到统一的低延迟架构中,并在合成对话数据上训练,克服了这些限制。作者还扩展了 Full-Duplex-Bench 基准测试以评估多角色场景,表明 PersonaPlex 在角色遵循度、语音相似度和对话自然度方面优于现有系统,且不牺牲延迟。
数据集

作者使用由对话转录文本和生成语音组成的合成数据集来训练和评估其模型。以下是数据的结构与处理方式:
-
数据集组成与来源
- 对话转录文本由 Qwen-3-32B 和 GPT-OSS-120B 生成。
- 两种主要场景类型:服务场景(如餐厅、银行)和问答助手场景(教师角色,主题多样)。
- 语音样本来自 VoxCeleb、Libriheavy、LibriTTS、CommonAccent 和 Fisher(总计 26,296 个样本;其中 2,630 个保留用于测试说话人相似度)。
- 对于发布的检查点,添加了 Fisher 英语语料库中的真实对话数据(7,303 段对话,1,217 小时),以提升自然的反馈响应和情感表达。
-
关键子集详情
- 服务场景:
- 按领域 → 场景 → 转录文本分层采样。
- 为每个代理提供角色上下文(如姓名、公司、社保号、套餐选项)。
- 训练场景与 Service-Duplex-Bench 中的评估场景不同。
- 问答场景:
- 两轮对话,角色固定为“智慧友好的教师”。
- 主题多样;第二轮问题可能涉及主题变更或追问。
- Service-Duplex-Bench(评估):
- 50 个独特服务场景,每个含 7 个单轮问题。
- 测试能力包括专有名词回忆、上下文遵循和应对粗鲁客户。
- 示例上下文包含代理姓名、公司、社保号和可用套餐。
- 服务场景:
-
数据使用方式
- 训练集包含合成对话 + Fisher 语料库(用于发布检查点)。
- 混合比例未明确,但合成对话占主导;Fisher 数据用于补充真实感。
- Fisher 数据的提示详略不一:极简、主题特定或高度详细(由 GPT-OSS-120B 生成)。
- 对于发布模型,所有合成语音均由 TortoiseTTS 生成(保护隐私),并用 Praat 增强音高/共振峰。
- ChatterboxTTS 替代 Dia 用于统一语音生成,将说话人相似度提升至 0.65。
-
处理与裁剪细节
- 服务对话音频使用 Dia TTS 生成双说话人(含时序、打断、环境音)。
- 问答对话音频使用 Chatterbox TTS 逐轮生成,再用静音填充拼接(或负静音模拟打断)。
- 未明确提及裁剪,但轮次拼接模拟自然或被打断的语音流。
- 元数据包含每个对话的角色上下文、说话人身份和场景锚定。
方法
作者采用受 Moshi 启发的双工式多模态架构 PersonaPlex,处理三个并行输入流:用户音频、代理文本和代理音频。该设计通过新颖的混合系统提示,在时间上结构化地引导代理的语义和声学行为,实现同步的角色条件控制和语音控制。请参考框架图了解输入通道与处理阶段的视觉分解。
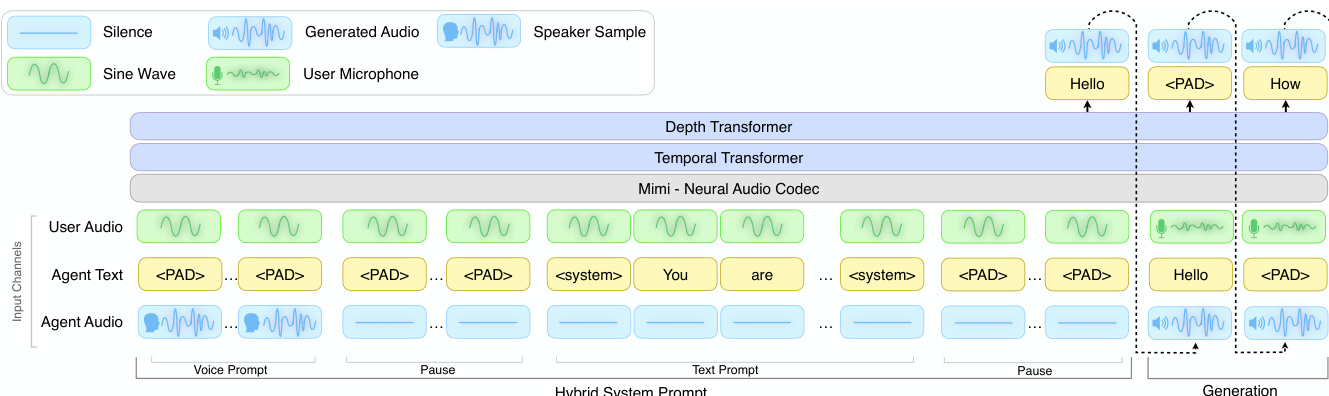
混合系统提示由两个连接段组成:文本提示段和语音提示段。在文本提示段,场景特定的文本标记注入代理文本通道,代理音频通道保持静音,强制角色条件。在语音提示段,通过代理音频通道提供短语音样本,代理文本通道填充以保持对齐——这通过条件化后续代理话语匹配所提供语音,实现零样本语音克隆。为确保训练期间稳定条件,用户音频通道在提示阶段替换为 440 Hz 正弦波,自定义分隔符标记混合系统提示与对话生成阶段的边界。
模型采用 Mimi 神经音频编解码器进行音频标记化,随后通过时序 Transformer 和深度 Transformer 处理多模态序列。训练期间,系统提示标记的损失被屏蔽,以防止过拟合提示结构。为解决标记不平衡,作者将非语义音频标记的损失权重降低 0.02,填充文本标记的损失权重降低 0.3,与 Moshi 训练目标一致。语音和文本提示段的顺序灵活;实践中语音提示在前,以便在无需语音克隆时预填充,从而降低延迟。
实验
PersonaPlex 使用混合提示系统,在 1840 小时客服对话和 410 小时问答对话上训练,并从 Moshi 权重微调,在对话自然度和语音克隆方面达到最先进水平,经人类 DMOS 评分和 WavLM-TDNN 说话人相似度指标验证。在 Full-Duplex-Bench 上,它在类人交互性方面表现优异;在 Service-Duplex-Bench 上,除 Gemini Live 外,其角色遵循度匹配或超越所有模型,显示强大的指令遵循能力。数据集扩展实验表明,合成数据提升语音克隆和角色遵循度,随着数据增加,Service-Duplex-Bench 性能稳步提升。发布的检查点保持竞争力的自然度,并增强反馈响应和停顿处理等对话动态。
作者使用不同数据集规模评估 PersonaPlex,并与 Moshi 基线比较。结果表明,增加数据集规模可提升 Full-Duplex-Bench 和 Service-Duplex-Bench 上的性能,100% 数据量得分最高。未使用合成数据训练的 Moshi 基线在所有指标上表现显著更差。数据集规模越大,两个基准测试性能越好:100% 数据量时 GPT-4o 得分最高:4.21 和 4.48;Moshi 基线(0% 合成数据)得分最低:0.10 SSIM 和 1.75 GPT-4o。

作者使用人类评分的 DMOS 分数和说话人相似度指标,将 PersonaPlex 与多个基线模型进行比较。结果表明,PersonaPlex 在 Full-Duplex-Bench 和 Service-Duplex-Bench 上均获得最高 DMOS 分数和最高说话人相似度分数,表明其在对话自然度和语音克隆能力上优于其他模型。PersonaPlex 在 Full-Duplex-Bench 和 Service-Duplex-Bench 上的 DMOS 分数均最高;PersonaPlex 达到 0.57 的说话人相似度,显著优于所有其他模型;Gemini 和 Qwen-2.5-Omni 的 DMOS 中等,但说话人相似度接近零。

作者使用人类评分的 DMOS 分数在 Full-Duplex-Bench 上评估发布的 PersonaPlex 模型的自然度。PersonaPlex 在测试模型中得分最高,表明其对话自然度感知更优。评估包括与 Gemini、Qwen-2.5-Omni、Freeze-Omni 和 Moshi 的比较。PersonaPlex(发布版)得分最高,为 2.95 ± 0.25 DMOS;在自然度上优于 Gemini(2.80)和 Qwen-2.5-Omni(2.81);Moshi 基线得分最低,为 2.44 ± 0.21 DMOS。

作者在 GPT-4o 任务上评估多个模型,报告七个子任务和平均分。PersonaPlex 平均得分为 4.48,仅次于 Gemini 的 4.73,而 Moshi 和 Qwen-2.5-Omni 得分显著更低。PersonaPlex 总体排名第二,平均得分为 4.48;Gemini 以最高平均分 4.73 领先;Moshi 和 Qwen-2.5-Omni 表现明显较低。

发布的 PersonaPlex 检查点在多个对话动态方面进行评估,包括停顿处理、反馈频率、轮转和用户打断响应。结果表明其轮次重叠率低、延迟低、反馈频率高、用户打断处理能力强。这些指标表明相比先前基线,对话流畅性和响应性有所提升。停顿和轮转中的低重叠率表明精确的时序控制;高反馈频率表明对话参与度提升;低延迟的用户打断处理支持自然对话流。

PersonaPlex 在多个基准测试中使用人类评分和自动化指标进行评估,显示出对 Moshi、Gemini 和 Qwen-2.5-Omni 等基线的一致优越性。在 Full-Duplex-Bench 和 Service-Duplex-Bench 上,它获得最高 DMOS 分数和说话人相似度(0.57),表明更强的对话自然度和语音克隆能力。使用 100% 数据集时,其 GPT-4o 得分达到峰值 4.21 和 4.48,显著优于 Moshi 基线(0.10 SSIM,1.75 GPT-4o)。发布的模型在对话动态方面也表现出色,显示低轮次重叠、高反馈频率和响应式打断处理,同时在 GPT-4o 任务性能中排名第二,平均得分为 4.48。