Command Palette
Search for a command to run...
Qwen3_TTS 技术报告
Qwen3_TTS 技术报告
摘要
在本报告中,我们介绍了Qwen3-TTS系列——一组先进的多语言、可控、鲁棒且支持流式传输的文本转语音模型。Qwen3-TTS支持业界领先的3秒语音克隆与基于描述的控制能力,既能生成完全新颖的语音,也能对输出语音进行细粒度调控。该模型基于涵盖10种语言、超过500万小时的语音数据进行训练,采用双轨语言模型(LM)架构实现实时语音合成,并配备两个语音分词器:1)Qwen-TTS-Tokenizer-25Hz 是一种单码本编码器,侧重于语义内容的保留,可无缝集成Qwen-Audio,并通过分块式DiT(Diffusion Transformer)实现流式波形重建;2)Qwen-TTS-Tokenizer-12Hz 通过12.5 Hz、16层多码本设计,实现极低码率压缩与超低延迟流式传输,仅需97毫秒即可实现首个数据包的即时发送,同时采用轻量级因果卷积网络(Causal ConvNet)提升效率。 大量实验表明,Qwen3-TTS在多种客观与主观评测基准上均达到当前最先进水平,包括多语言TTS测试集、InstructTTSEval以及我们自建的长语音测试集。为促进社区研究与开发,我们已将两个分词器及模型以Apache 2.0许可证开源发布。
一句话总结
通义团队推出Qwen3-TTS,这是一种基于双轨语言模型架构和两种分词器构建的多语言、可控、流式文本转语音系统——Qwen-TTS-Tokenizer-25Hz用于语义丰富、兼容Qwen-Audio的流式合成,Qwen-TTS-Tokenizer-12Hz用于超低延迟输出(首包延迟仅97毫秒),支持3秒语音克隆,并在多语言、指令控制和长文本语音基准测试中达到业界领先水平。
核心贡献
- Qwen3-TTS引入双轨自回归架构及两种语音分词器:Qwen-TTS-Tokenizer-25Hz用于语义感知的流式合成,Qwen-TTS-Tokenizer-12Hz用于超低延迟生成(首包延迟97毫秒),支持在500万+小时语音数据上训练的10种语言的实时、高保真TTS。
- 模型在零样本语音克隆(Seed-TTS上最低WER)、跨语言合成(如中文到韩语)和指令控制语音生成方面达到业界领先水平,超越ElevenLabs和GPT-4o-mini-tts,同时在10分钟长语音生成中保持稳定、无伪影。
- Qwen3-TTS在一个统一框架内整合语音克隆、跨语言迁移和细粒度可控性,所有模型与分词器均在Apache 2.0协议下开源,推动流式、富有表现力的多语言语音合成的开放研究。
引言
作者采用双轨语言模型架构,结合两种新型语音分词器,构建Qwen3-TTS——一个在500万小时以上语音数据上训练的多语言、可控、流式文本转语音模型家族。以往的TTS系统常难以在自然度、低延迟和细粒度控制之间取得平衡,尤其在流式或跨语言场景中;而离散分词方法通常牺牲表现力或引入误差累积。Qwen3-TTS通过引入Qwen-TTS-Tokenizer-25Hz实现语义丰富的流式合成(与Qwen-Audio集成),并通过多码本设计和因果卷积网络实现Qwen-TTS-Tokenizer-12Hz的超低延迟输出(首包延迟低于100毫秒)。其主要贡献是提供一个统一的自回归框架,在语音克隆、跨语言合成、指令控制和长文本生成方面均达到业界领先水平,同时以Apache 2.0协议开源,加速社区创新。
数据集

作者使用多源数据集训练Qwen3-TTS,包含公开数据与内部整理的语音数据。关键细节如下:
-
数据集组成与来源:
- 结合公开数据集(如LibriTTS、VCTK、AISHELL-3)与专有内部录音。
- 包含多语言、多说话人样本,支持多样化语音合成。
-
子集详情:
- 公开子集:约500小时,筛选出清晰音频、标准发音、背景噪声最小的样本。
- 内部子集:约1200小时,在受控条件下采集,含说话人元数据和音素对齐。
- 所有子集均经信噪比>20dB、时长1–15秒筛选,并由人工标注员验证。
-
训练用途:
- 训练集划分采用90:10的训练-验证比例。
- 数据混合:60%公开数据,40%内部数据,按说话人和语言分布平衡。
- 所有来源统一应用文本归一化和音素转换。
-
处理与裁剪:
- 音频裁剪至1–15秒;根据能量阈值去除首尾静音。
- 元数据包含说话人ID、语言标签、时长和音素序列。
- 训练期间应用数据增强:语速扰动(±5%)、噪声注入和音量归一化。
方法
作者为Qwen3-TTS设计双路径架构,通过统一的大语言模型主干整合文本与语音模态,同时支持流式合成与细粒度语音控制。系统采用两种不同的分词方案——Qwen-TTS-Tokenizer-25Hz和Qwen-TTS-Tokenizer-12Hz,分别针对延迟、保真度与表现力的不同权衡。
对于25 Hz变体,分词器基于Qwen2-Audio构建,分两阶段训练。第一阶段,在音频编码器中加入重采样层和插入中间位置的向量量化(VQ)层,并在ASR任务上预训练模型。第二阶段,增加基于卷积的mel谱图解码器,从量化标记重建mel谱图,从而将声学结构注入标记表示。所得单码本标记由Diffusion Transformer(DiT)处理,该模型通过Flow Matching训练,将标记序列映射为mel谱图,再经修改版BigVGAN转换为波形。为实现流式,作者实现滑动窗口块注意力机制:标记分组为固定长度块,DiT注意力限制在四个块的感知域内——当前块、三个回看块和一个前瞻块,确保低延迟生成同时保持上下文连贯性。BigVGAN同样采用分块解码策略以维持流式兼容性。
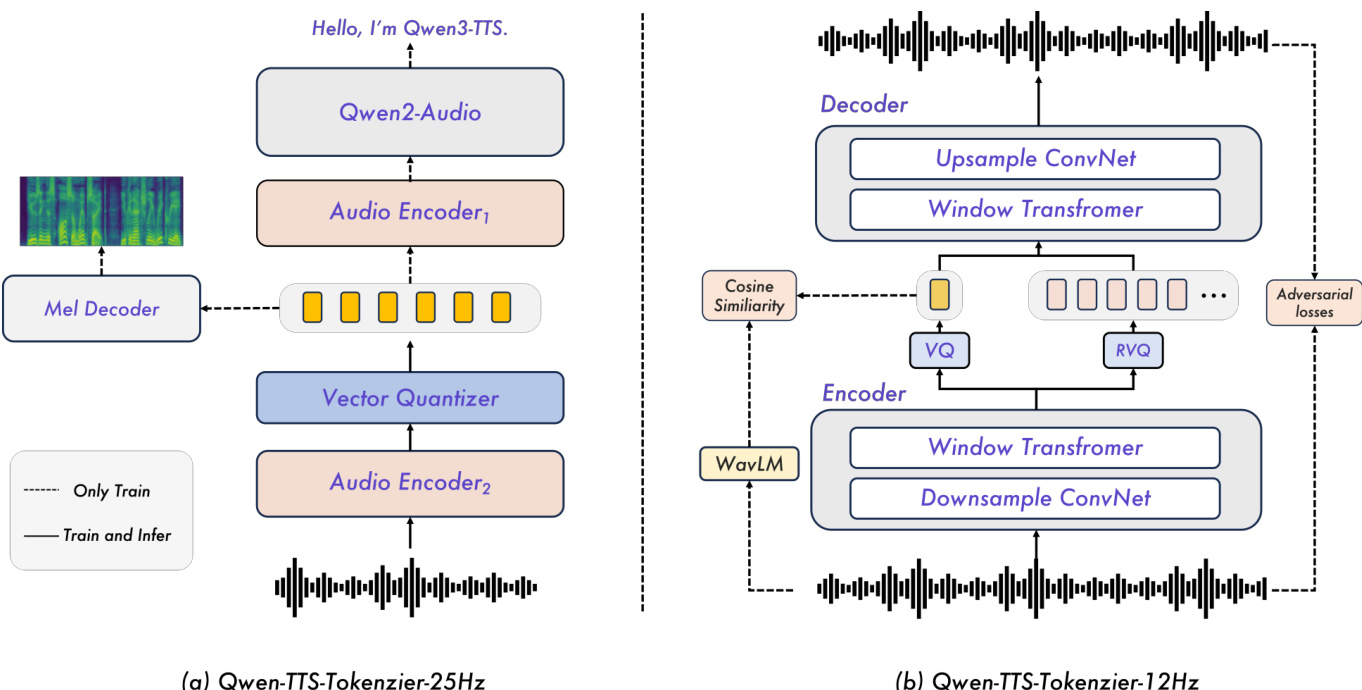
相比之下,12.5 Hz分词器采用受Mimi架构启发的多码本设计,将语义与声学信息解耦为两个并行流。语义路径使用WavLM作为教师,引导第一码本层朝向语义有意义的表示;声学路径采用15层残差向量量化(RVQ)模块,逐步细化细粒度声学细节。训练在GAN框架内进行:生成器直接作用于原始波形提取并量化两个流,判别器提升自然度与保真度。多尺度mel谱图重建损失进一步强制时频一致性。对于流式,编码器与解码器均为完全因果结构,以12.5 Hz速率无前瞻地发射标记并增量重建音频。
Qwen3-TTS主干通过双轨表示整合文本与声学标记,沿通道轴拼接。接收文本标记后,模型实时预测对应声学标记。对于25 Hz变体,主干预测单层标记,再由分块DiT精炼以重建波形。对于12 Hz变体,采用分层预测方案:主干首先从聚合特征预测第零码本,MTP(多标记预测)模块并行生成所有残差码本。这实现单帧生成同时捕捉精细声学细节,提升语音一致性和表现力。
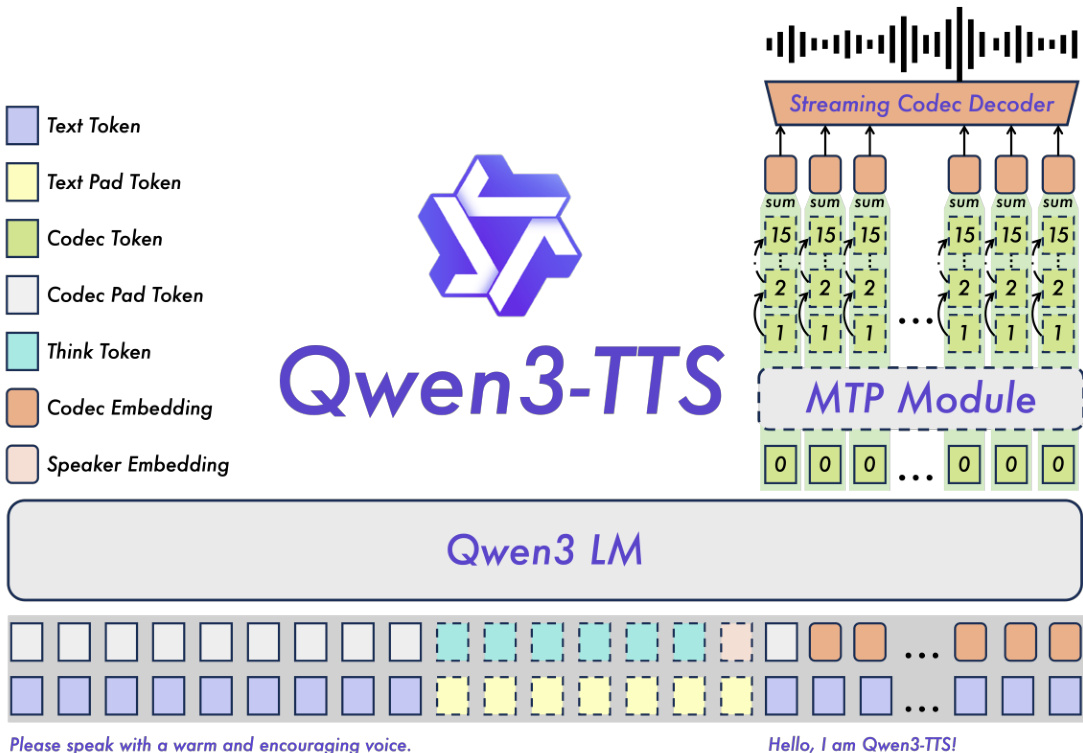
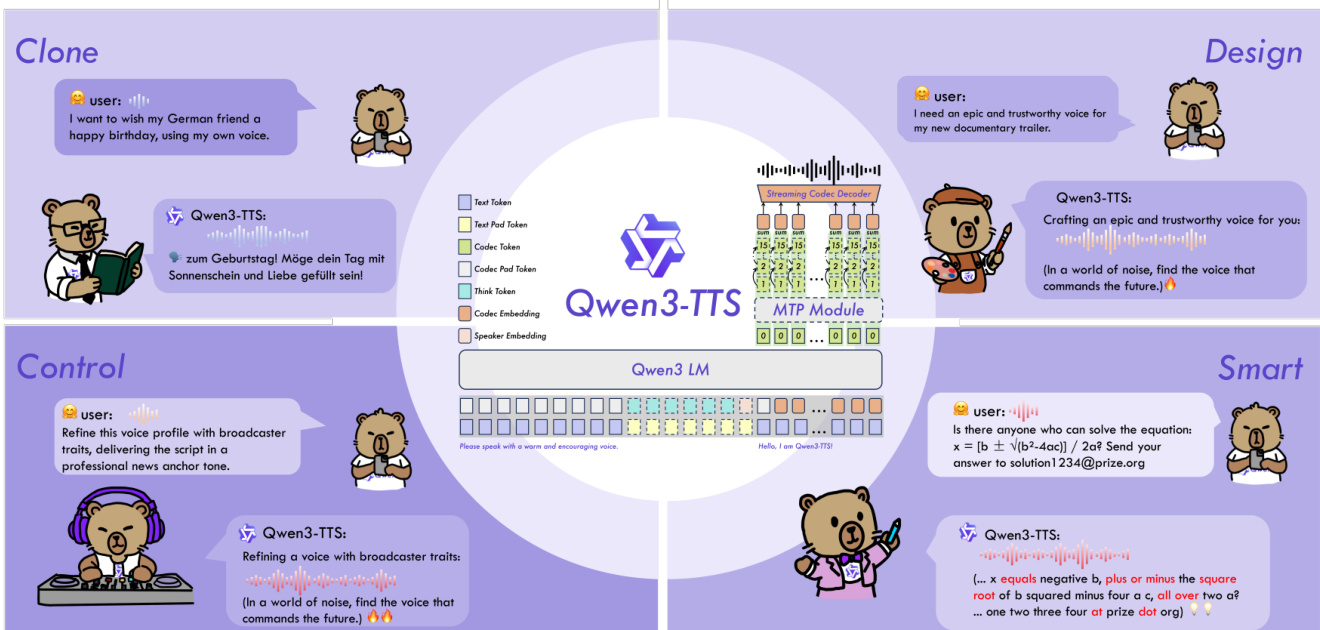
为支持语音克隆与设计,系统在输入序列前添加包含控制信号的用户指令。语音克隆可通过从参考语音提取的说话人嵌入实现(支持实时克隆),或通过文本-语音对的上下文学习(更好保留韵律)。语音设计利用Qwen3文本模型强大的理解与指令遵循能力,训练中加入概率激活的“思考”模式,使Qwen3-TTS能解析复杂语音描述并生成具有预定义风格或特质的语音。
训练分为预训练与后训练两个阶段。预训练分三阶段:(1) 通用阶段(S1)在500万+小时多语言数据上训练,建立文本到语音映射;(2) 高质量阶段(S2)使用分层高质量数据减少幻觉;(3) 长上下文阶段(S3)将最大标记长度扩展至32,768并上采样长语音,提升对长输入的处理能力。后训练包括:(1) 使用人工偏好对的直接偏好优化(DPO),使输出符合人类判断;(2) 基于规则的奖励和GSPO,提升稳定性与跨任务性能;(3) 轻量级说话人微调,实现语音适配同时提升自然度与可控性。
实验
Qwen3-TTS在效率、语音分词及多样化语音生成任务中进行评估,使用内部与公开基准,指标包括WER、SIM、STOI和PESQ。12Hz分词器实现更低的首包延迟和更优的重建质量,在LibriSpeech上创下新纪录;25Hz变体在长文本合成中表现优异,内部数据集上WER为1.53。在零样本与多语言生成中,Qwen3-TTS-12Hz-1.7B在Seed-TTS上实现1.24 WER,在10种语言的说话人相似度上优于商业系统;在中文到韩语任务中跨语言错误率降低66%,并展现强大的指令遵循与目标说话人适配能力,在10种语言中的7种上超越GPT-4o。
作者在10种语言上将Qwen3-TTS变体与商业基线对比,评估内容一致性与说话人相似度。结果显示Qwen3-TTS在6种语言中WER最低,在所有10种语言中说话人相似度最高。1.7B模型通常优于0.6B变体,12Hz变体在说话人保真度上更优,25Hz变体在部分语言中内容准确性更强。Qwen3-TTS-12Hz-1.7B在全部10种语言中说话人相似度最佳,Qwen3-TTS-25Hz-1.7B在中文、英文、意大利语、法语、韩语和俄语中WER最低。ElevenLabs仅在德语和葡萄牙语中WER最低。

作者在英语和中文数据集的ASR任务中评估Qwen-TTS-Tokenizer-25Hz与S3分词器变体。结果显示Qwen-TTS-Tokenizer-25Hz在第一阶段在多个基准上实现最低或接近最低的WER,优于S3分词器变体。第二阶段由于增加声学细节,WER略有上升,反映了生成质量提升的权衡。Qwen-TTS-Tokenizer-25Hz第一阶段在C.V. EN和Fleurs EN上取得最佳WER,第二阶段WER轻微上升,以声学丰富性换取语义保真度,S3分词器变体在多数数据集上WER高于Qwen变体。

作者在LibriSpeech test-clean上评估Qwen-TTS-Tokenizer-12Hz与先前语义感知分词器的语音重建效果。结果显示Qwen-TTS-Tokenizer-12Hz在所有指标(包括PESQ、STOI、UTMOS和说话人相似度)上均达到业界领先水平。同时以16个量化器和12.5 FPS保持高效率。Qwen-TTS-Tokenizer-12Hz在PESQ_NB(3.68)和UTMOS(4.16)上创下新纪录,在对比模型中达到最高说话人相似度(SIM 0.95),使用16个量化器在12.5 FPS下平衡质量与效率。

作者在SEED测试集上评估Qwen3-TTS变体与主流零样本TTS系统的对比,通过词错误率衡量内容一致性。结果显示Qwen3-TTS-12Hz-1.7B在中文和英文子集上均实现最低WER,优于CosyVoice 3和MiniMax-Speech等基线。12Hz变体始终优于25Hz变体,表明较粗时间分辨率有助于长期依赖建模。Qwen3-TTS-12Hz-1.7B在test-zh上实现0.77 WER,在test-en上实现1.24 WER,12Hz变体在两种语言的内容准确性上始终优于25Hz变体,模型从0.6B扩展到1.7B为两种分词器变体均带来持续的WER提升。

作者在不同模型规模和分词器下评估Qwen3-TTS效率,考虑不同并发水平。结果显示12Hz分词器在首包延迟和RTF上显著低于25Hz变体,尤其在高并发下更明显。较大模型延迟更高,但保持可接受的实时因子以支持流式使用。12Hz分词器首包延迟比25Hz变体最多降低50%,高并发增加延迟但12Hz模型在负载下保持更低RTF,较大模型(1.7B)延迟更高但效率优于较小模型(0.6B)。

Qwen3-TTS变体在多语言、零样本和效率基准测试中持续优于商业和先前系统,在说话人相似度和内容准确性方面表现突出,1.7B模型与12Hz分词器在中文和英文的说话人保真度和WER上达到业界领先,同时在并发下展现卓越流式效率。Qwen-TTS-Tokenizer-25Hz在ASR任务中第一阶段WER低,12Hz变体在LibriSpeech的PESQ和UTMOS等语音重建指标上创下新纪录,以12.5 FPS平衡质量与速度。在零样本设置中,Qwen3-TTS-12Hz-1.7B在SEED测试集上实现最低WER,超越CosyVoice 3和MiniMax-Speech,12Hz变体在内容一致性上始终优于25Hz,表明其长期建模能力更强。效率测试确认12Hz分词器在负载下延迟最多降低50%,尽管较大模型延迟更高,但仍保持可接受的实时因子。