Command Palette
Search for a command to run...
Qwen3-ASR 技术报告
Qwen3-ASR 技术报告
摘要
在本报告中,我们推出了Qwen3-ASR系列,包含两款功能强大的全功能语音识别模型,以及一种新颖的非自回归语音强制对齐模型。Qwen3-ASR-1.7B和Qwen3-ASR-0.6B均为支持52种语言及方言的语言识别与语音识别(ASR)模型,二者均基于大规模语音训练数据,并充分利用了其基础模型Qwen3-Omni强大的音频理解能力。除了在开源基准测试上的评估外,我们还进行了全面的内部评估,因为开源基准测试得分相近的ASR模型在真实应用场景中可能表现出显著的质量差异。实验结果表明,1.7B版本在开源ASR模型中达到了当前最优性能,其表现与最强的专有API相当;而0.6B版本则在准确率与效率之间实现了最佳平衡。Qwen3-ASR 0.6B可实现平均首词延迟低至92毫秒,在并发度为128的情况下,每秒可完成2000秒语音的转写。Qwen3-ForcedAligner-0.6B是一种基于大语言模型(LLM)的非自回归(NAR)时间戳预测模型,能够对11种语言的文本-语音对进行精确对齐。时间戳准确性实验显示,该模型显著优于当前三个最强的强制对齐模型,在效率与多语言适用性方面更具优势。为进一步加速语音识别与音频理解领域的社区研究,我们已将上述模型以Apache 2.0许可证开源发布。
一句话总结
Qwen 团队推出 Qwen3-ASR 系列模型,包括 1.7B 和 0.6B 两款 ASR 模型,依托 Qwen3-Omni 的音频理解能力,支持 52 种语言及方言;以及 0.6B 非自回归式 Qwen3-ForcedAligner,支持 11 种语言的语音-文本对齐。该系列在开源 ASR 性能上达到业界领先水平,准确率媲美商业 API,推理效率卓越(首字延迟 92ms,128 并发下每秒可转写 2000 秒语音),且在时间戳精度、效率和通用性方面超越以往强制对齐模型。
核心贡献
-
Qwen3-ASR-1.7B 和 Qwen3-ASR-0.6B 在 52 种语言及方言的开源 ASR 模型中表现最佳,依托 Qwen3-Omni 的音频理解能力,在包含噪音和歌唱语音的真实场景下优于商业 API;其中 0.6B 版本在 128 并发下实现低于 100ms 的延迟与高吞吐量。
-
Qwen3-ForcedAligner-0.6B 是首个基于大语言模型的非自回归强制对齐器,支持 11 种语言,在时间戳精度和效率上超越 MFA 和 NFA,单样本端到端处理时间低于五分钟,支持词、句、段落多粒度灵活对齐。
-
Qwen3-ASR 系列完全开源,提供统一、易用的框架,支持流式转写、多语言处理和可复现的微调,填补了可扩展语音标注与真实部署工具链的关键空白。
引言
作者利用 Qwen3-Omni 的音频理解能力构建 Qwen3-ASR,这是一套支持 52 种语言及方言的多语言 ASR 与语言识别开源模型家族,同时引入一种新型非自回归强制对齐器用于时间戳预测。以往 ASR 系统常难以应对真实场景中的多样性(如噪音、歌唱、方言),且依赖独立的、语言特定的工具进行时间戳标注,限制了可扩展性与效率。Qwen3-ASR 系列通过在真实内部基准测试中达到业界领先准确率、提供高效推理(如 92ms 首字延迟),并推出首个轻量级、多语言、基于大语言模型的强制对齐器,支持灵活粒度,在速度与精度上均优于现有工具,填补了上述空白。所有模型均以 Apache 2.0 协议开源,并配备统一的推理与微调框架,以加速社区研究。
数据集
作者使用多源数据集训练 Qwen3-ASR,结合公开与专有语音数据。关键细节如下:
-
组成与来源:
- 包含 LibriSpeech、CommonVoice 和 AISHELL-3 等公开数据集。
- 补充阿里巴巴生态系统的海量内部语音语料。
- 覆盖多样口音、领域与说话风格,以提升泛化能力。
-
子集详情:
- LibriSpeech:960 小时干净朗读语音,经筛选确保高转写准确率。
- CommonVoice:涵盖 100 多种语言约 1000 小时,设置严格的质量与对齐阈值。
- AISHELL-3:85 小时普通话多说话人数据,经清洗确保说话人一致性。
- 内部数据:超 50,000 小时含噪真实语音,通过 ASR 置信度与音频质量指标筛选。
-
训练使用:
- 数据划分:90% 训练,5% 验证,5% 测试 —— 按说话人与领域分层。
- 混合比例:公开数据权重 30%,内部数据 70%,优先保障真实场景鲁棒性。
- 处理:所有音频重采样至 16 kHz,切分为 30 秒片段(50% 重叠),通过 VAD 去除静音。
-
额外处理:
- 裁剪策略:训练时随机截取 10–30 秒片段,模拟不同语句长度。
- 元数据:每样本标注说话人 ID、语言、领域与信噪比估计,用于课程学习。
- 增强:训练时应用 SpecAugment,包含时间掩码、频率掩码与语速扰动。
方法
作者为 Qwen3-ASR 系列采用模块化架构,基于 Qwen3-Omni 基础模型,实现鲁棒、多语言、支持流式处理的语音识别。核心音频处理由 AuT 编码器完成,该编码器为独立预训练的注意力编码器-解码器(AED)模型,将 100Hz Fbank 特征下采样 8 倍,输出 12.5Hz 令牌率表示。该编码器支持 1s 至 8s 动态 Flash 注意力窗口,灵活部署于流式与离线场景。架构通过投影器将此编码器与 Qwen3 LLM 整合,形成统一多模态流水线。例如,Qwen3-ASR-1.7B 结合 Qwen3-1.7B 与 300M 参数 AuT 编码器,而 Qwen3-ASR-0.6B 使用更紧凑的 180M 参数编码器以平衡效率与精度。
如下图所示,整体框架展示了预训练 AuT 编码器与 Qwen3 LLM 的整合:语音首先编码为隐藏状态序列,经投影后输入语言模型进行转写。AuT 模型的解码器侧(左图)遵循 AED 范式,包含交叉注意力与自注意力层;右侧图示为端到端 Qwen3-ASR 结构,其中 LLM 直接基于音频嵌入生成文本。
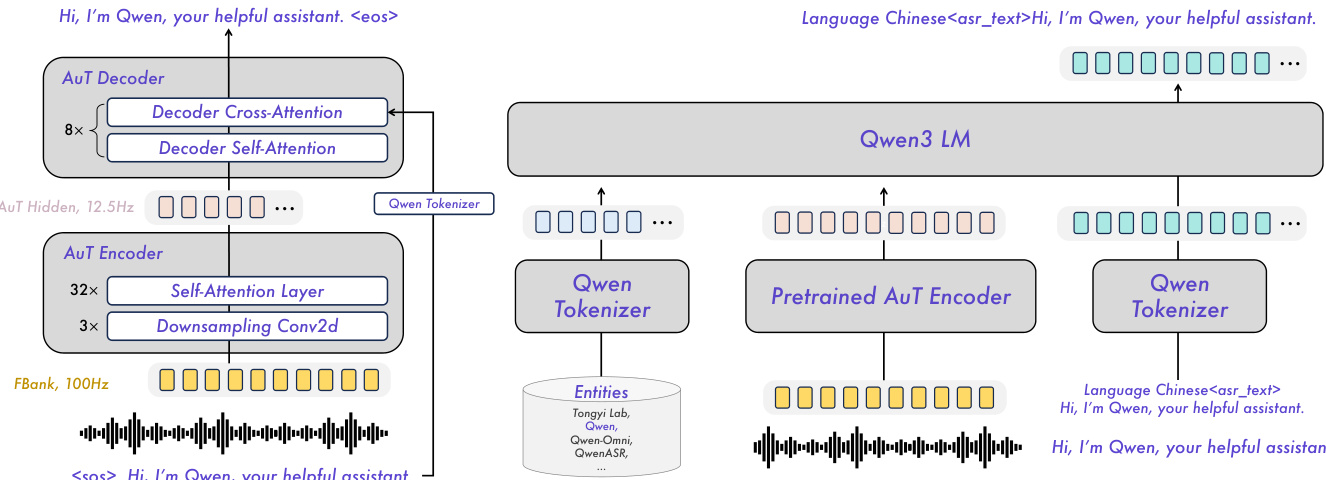
训练分四阶段进行:AuT 预训练、Omni 预训练、ASR 监督微调(SFT)与 ASR 强化学习(RL)。AuT 编码器在约 4000 万小时伪标注 ASR 数据(主要为中文与英文)上预训练,学习在可变注意力窗口下的稳定音频表示。Omni 预训练随后将 Qwen3-Omni 模型与多模态数据对齐,使两个 Qwen3-ASR 变体在 3 万亿 token 上训练,获得跨模态理解能力。SFT 阶段在较小、独立的多语言数据集上微调模型,包含非语音、流式增强与上下文偏置数据,以强化纯 ASR 行为并缓解指令遵循失败。模型被训练为输出含或不含人声的转写,并利用系统提示中的上下文 token 生成定制化结果。最后,通过 Group Sequence Policy Optimization(GSPO)强化学习,利用 5 万条语句优化转写质量,增强在复杂声学环境下的抗噪性与稳定性。
对于强制对齐,Qwen3-ForcedAligner-0.6B 将任务重构为槽位填充:给定插入 [time] 标记词或字符边界的转写文本,模型预测每个槽位的离散时间戳索引。如图所示,架构使用相同预训练 AuT 编码器提取语音嵌入,转写文本以 [time] 占位符分词。这些占位符根据编码器输出 80ms 帧长离散化为索引。组合序列由 Qwen3-0.6B LLM 处理,后接线性时间戳预测层,同时输出所有槽位索引,支持最长 300 秒音频(3750 个类别)。
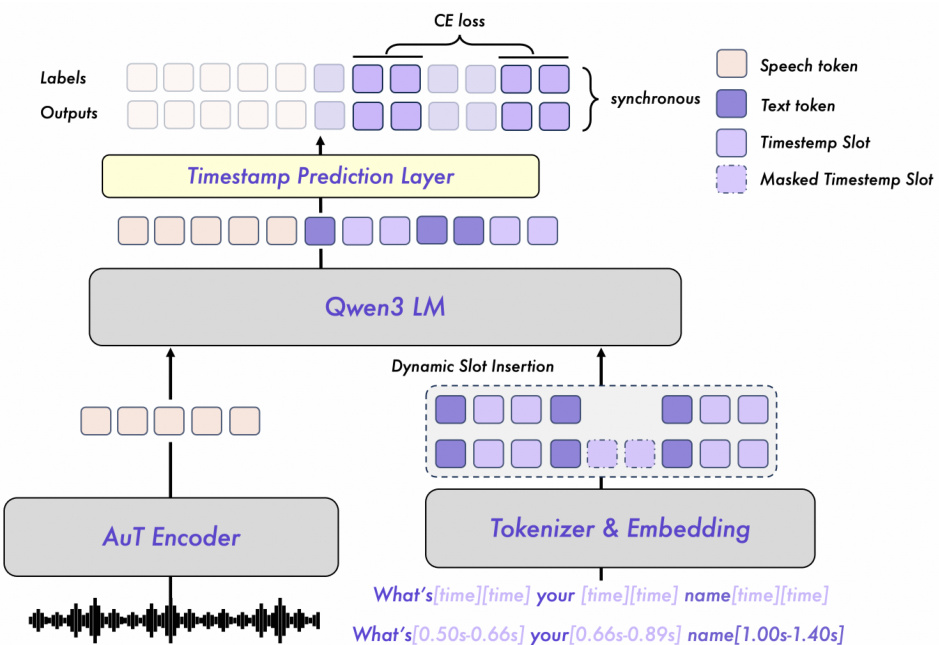
训练采用由 Montreal Forced Aligner(MFA)生成的伪标签,经蒸馏与平滑以减少系统性偏移。与标准逐词预测不同,模型采用因果训练:输出与标签序列保持对齐,使模型能明确识别时间戳槽位并利用上下文进行全局一致预测。交叉熵损失仅应用于时间戳槽位,聚焦优化槽位填充。动态槽位插入策略在训练时随机插入起止槽位,以提升泛化能力。推理时,用户可在任意词或字符后插入 [time] 标记,模型通过非自回归解码同时预测所有时间戳索引,再乘以 80ms 转换为实际时间戳。
实验
Qwen3-ASR 系列在公开与内部基准测试中表现卓越,在多语言与多方言 ASR 上达到业界领先,尤其在普通话与 22 种汉语方言中表现突出,对口音、噪音与歌唱语音识别鲁棒,即使存在背景音乐亦能保持性能。在英语基准测试中,其优于开源模型,且在真实、非整理语音场景下媲美或超越商业 API。1.7B 版本持续优于 0.6B,128 并发下实现高达 2000 倍实时吞吐,并保持强流式准确率。Qwen3-ForcedAligner-0.6B 进一步提供精确跨语言时间戳,AAS 值低,在短与长语句上均优于语言特定基线。
作者评估 Qwen3-ASR-1.7B 在含背景音乐的歌唱语音与完整歌曲转写任务,对比商业与开源基线。结果表明,Qwen3-ASR-1.7B 在多数歌唱基准测试中词错误率最低,在含音乐的长歌曲转写上超越所有开源模型,同时与顶级商业系统保持竞争力。Qwen3-ASR-1.7B 在 M4Singer、MIR-1k-vocal 与 Popcs 歌唱基准测试中取得最佳 WER。在含背景音乐的完整歌曲上(包括英语与中文数据集),其优于开源模型。商业系统表现波动,而 Qwen3-ASR-1.7B 在各类歌曲中保持稳定准确率。

作者在 MLS、CommonVoice 与 MLC-SLM 等多个多语言基准测试中评估 Qwen3-ASR 模型。结果表明,Qwen3-ASR-1.7B 持续优于较小的 Qwen3-ASR-0.6B,且两者在多数语言中普遍优于 Qwen3-ASR-Flash-128。性能差距在低资源或挑战性语言子集尤为显著。Qwen3-ASR-1.7B 在 MLS 与 CommonVoice 多数语言中取得最低错误率。Qwen3-ASR-0.6B 在几乎所有评估语言中优于 Qwen3-ASR-Flash-128。模型规模越大,多语言鲁棒性越强,尤其在 MLC-SLM 中。

作者在多个基准测试中评估 Qwen3-ASR 模型的离线与流式模式表现。结果表明,流式推理保持强准确率,相比离线模式仅轻微增加错误率。更大的 1.7B 模型在两种推理模式下均持续优于 0.6B 版本。流式模式下所有基准测试中,Qwen3-ASR-1.7B 的准确率略低于离线模式,但优于 Qwen3-ASR-0.6B。模型在流式模式下于英语与中文基准测试中均保持强性能。

作者使用累积平均偏移(AAS)在 MFA 标注与人工标注测试集上评估 Qwen3-ForcedAligner-0.6B 与竞争方法。结果表明,Qwen3-ForcedAligner-0.6B 在不同语言与语句长度下持续取得更低 AAS 值,表明时间戳预测更精确。尽管基于 MFA 伪标签训练,其在人工标注数据上泛化良好。Qwen3-ForcedAligner-0.6B 在短与长语句上均优于基线。其在人工标注测试集上保持低 AAS,显示强真实场景泛化能力。该模型支持多语言与跨语言场景,仅需单一模型。

作者在 Fleurs 多语言基准测试中评估 Qwen3-ASR 模型,报告 30 种语言的词错误率。结果表明,Qwen3-ASR-1.7B 持续优于较小的 Qwen3-ASR-0.6B,且两者在多数语言中错误率低于 Qwen3-ASR-Flash-1208 基线。1.7B 模型整体表现最强,尤其在阿拉伯语、捷克语与印地语等语言上。Qwen3-ASR-1.7B 在多数语言中取得最低 WER,优于较小变体。性能随模型规模提升,1.7B 持续优于 0.6B。Qwen3-ASR-Flash-1208 在几乎所有语言中错误率均高于两个主模型。

Qwen3-ASR-1.7B 在含背景音乐的歌唱语音与完整歌曲转写任务中表现卓越,在 M4Singer、MIR-1k-vocal 与 Popcs 基准测试中取得最低 WER,超越所有开源模型,同时与商业系统保持竞争力。在 MLS、CommonVoice、MLC-SLM 与 Fleurs 等多语言基准测试中,1.7B 模型持续优于较小变体与 Flash 基线,尤其在低资源语言中表现突出,性能随模型规模正向提升。在流式模式下,Qwen3-ASR 模型保持强准确率,相比离线推理仅轻微下降,且 1.7B 版本在两种模式与所有语言中均优于 0.6B。Qwen3-ForcedAligner-0.6B 在不同语言与语句长度下提供更优时间戳精度,尽管基于伪标签训练,仍能良好泛化至人工标注数据,并支持单模型跨语言对齐。