Command Palette
Search for a command to run...
通过可扩展查找实现的条件记忆:大型语言模型稀疏性的一个新维度
通过可扩展查找实现的条件记忆:大型语言模型稀疏性的一个新维度
摘要
尽管混合专家(Mixture-of-Experts, MoE)通过条件计算实现模型容量的扩展,但Transformer架构本身缺乏原生的知识检索机制,迫使模型通过冗余计算来低效地模拟检索过程。为解决这一问题,我们引入了“条件记忆”作为互补的稀疏性维度,其具体实现基于Engram模块——该模块将经典的N-gram嵌入技术现代化,实现了O(1)时间复杂度的快速查找。通过构建稀疏性分配(Sparsity Allocation)问题的理论框架,我们发现了一条U型缩放规律,该规律能够优化神经计算(MoE)与静态记忆(Engram)之间的权衡。基于这一规律,我们将Engram扩展至270亿参数规模,在保持与纯MoE模型相同参数量和相同浮点运算量(FLOPs)的前提下,显著超越了基准模型的性能表现。尤为值得注意的是,尽管预期记忆模块主要提升知识检索能力(如MMLU提升3.4分,CMMLU提升4.0分),我们观察到其在通用推理任务中带来了更显著的增益(如BBH提升5.0分,ARC-Challenge提升3.7分),并在代码与数学领域表现出强大优势(HumanEval提升3.0分,MATH提升2.4分)。机制分析表明,Engram使主干网络的浅层无需再承担静态知识重建任务,从而有效“加深”了网络结构,提升了复杂推理能力。此外,通过将局部依赖关系交由查表处理,Engram释放了注意力机制的计算资源,使其能够聚焦于全局上下文,显著增强了长上下文检索能力(例如,Multi-Query NIAH指标从84.2提升至97.0)。最后,Engram构建了面向硬件感知的高效架构:其确定性地址映射机制支持从主机内存中进行运行时预取,带来几乎可忽略的额外开销。我们展望,条件记忆将成为下一代稀疏模型中不可或缺的核心建模原语。代码已开源,地址为:https://github.com/deepseek-ai/Engram
一句话总结
北京大学与 DeepSeek-AI 的研究者提出了 Engram,这是一种具有 O(1) 查找复杂度 的可扩展条件记忆模块,通过将静态知识检索从 Transformer 的早期层中剥离出来并与 MoE 形成互补,从而释放早期层用于更深层的推理计算,并在推理任务(BBH +5.0,ARC-Challenge +3.7)、代码与数学任务(HumanEval +3.0,MATH +2.4)以及长上下文任务(Multi-Query NIAH:84.2 → 97.0)上取得显著提升,同时保持 等参数量与等 FLOPs 的效率。
主要贡献
-
将条件记忆引入为新的稀疏维度。
论文提出将条件记忆作为与 MoE 互补的稀疏化方向,并通过 Engram 实现——一种现代化的 N-gram 嵌入模块,能够以 O(1) 复杂度检索静态模式,从而减少模型通过神经计算重构知识的需求。 -
基于稀疏分配问题的可扩展性设计。
作者通过“稀疏分配(Sparsity Allocation)”问题发现参数分配存在 U 型缩放规律,并将 Engram 扩展到 27B 参数规模,在等参数量和等 FLOPs 条件下超越 MoE 基线模型,在 MMLU(+3.4)、BBH(+5.0)、HumanEval(+3.0)和 Multi-Query NIAH(84.2 → 97.0)等基准上取得显著提升。 -
机理分析与系统层面的优势。
实验表明 Engram 通过将静态模式重构从早期层转移出去,有效增加了网络的“有效深度”,并将注意力更多分配给全局上下文,从而提升长上下文检索能力;同时,由于存储与计算解耦,其设计对硬件友好,易于扩展。
引言
Transformer 模型通常通过大量计算来“模拟”知识检索过程,导致早期层的容量被浪费在重构诸如命名实体、固定搭配或公式化短语等静态模式上。以往方法要么将 N-gram 查找作为外部增强机制,要么仅在输入层引入嵌入,难以在像 MoE 这样以稀疏计算为核心的架构中高效融合。
本文提出 Engram,一种将现代 N-gram 嵌入引入深层网络结构的条件记忆模块,以常数时间完成查找并与 MoE 互补。作者将参数分配建模为“稀疏分配问题”,发现性能随参数比例呈 U 型变化,并据此将 Engram 扩展至 27B 参数规模,在知识、推理、代码和数学任务上均显著优于 MoE。
进一步的机理分析表明,Engram 释放了早期层用于更高层次的推理能力,同时显著提升了长上下文建模效果;其确定性的寻址方式还使得大规模记忆可以被安全地卸载到主机内存,几乎不影响推理速度。
方法
Engram 通过结构化地将静态模式存储与动态计算解耦来增强 Transformer。它在每个 token 位置执行两个阶段:检索(retrieval)与融合(fusion)。
在模型结构中,Engram 位于词嵌入层与注意力层之间,其输出通过残差连接加入主干网络,并在 MoE 之前生效。
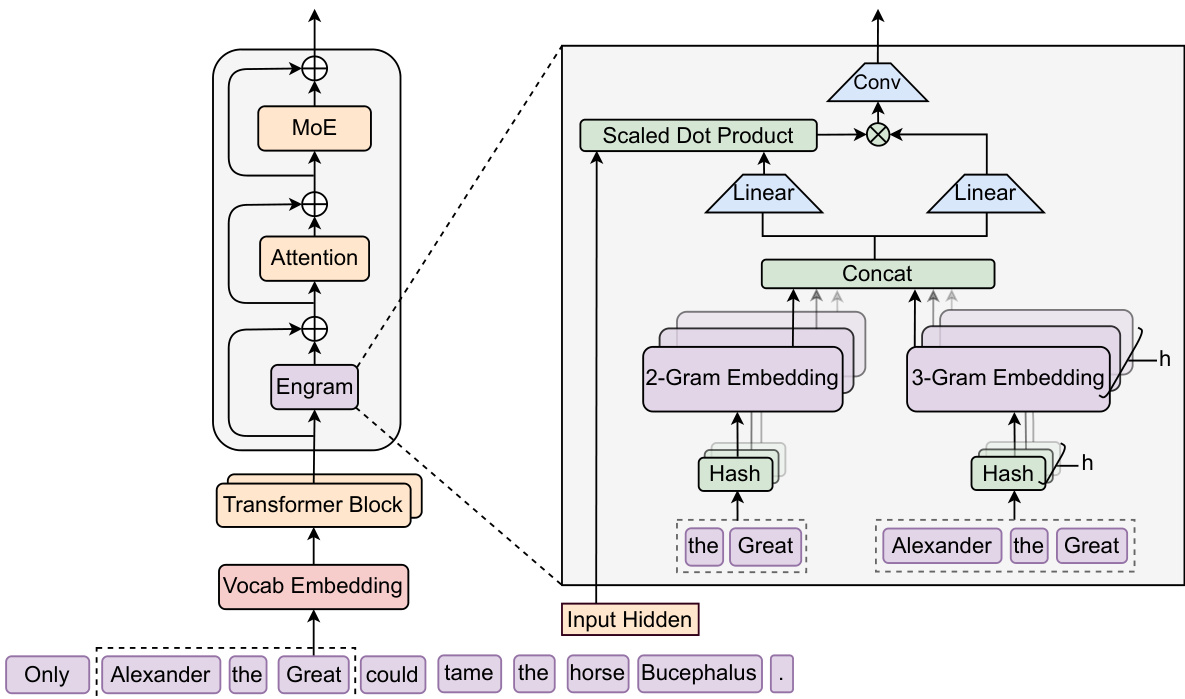
检索阶段
-
规范化映射(Canonicalization)
使用词表投影层 P 将 token 映射为规范 ID(如进行 NFKC 归一化、小写化等),在 128k 词表下有效词汇规模减少 23%。 -
N-gram 构造
对于位置 t,构造其后缀 N-gram gt,n。 -
多头哈希映射
使用 K 个哈希函数 φn,k 将每个 N-gram 映射到素数大小的嵌入表 En,k4,得到嵌入向量 et,n,k。 -
拼接形成记忆向量
融合阶段
将静态记忆向量 et与当前隐藏状态 ht 进行动态融合:
kt=WKet,vt=WVet.计算门控系数:
αt=σ(dRMSNorm(ht)⊤RMSNorm(kt)).得到门控输出 v~t=αt⋅vt,再通过深度可分离的因果卷积进行细化:
Y=SiLU(Conv1D(RMSNorm(V~)))+V~.最终结果通过残差连接加入主干网络。
多分支结构中的参数共享
- 嵌入表与 WV在所有分支间共享。
- 每个分支 m拥有独立的 WK(m):
所有分支输出被融合为一次 FP8 的稠密矩阵乘法,以提升 GPU 计算效率。
系统设计
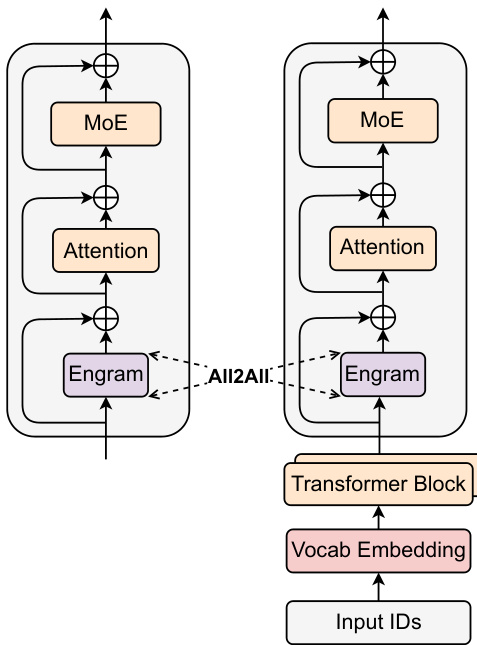
训练阶段
嵌入表在多 GPU 间分片存储,活跃行通过 All-to-All 通信进行拉取,从而使记忆容量可随加速卡数量线性扩展。
推理阶段
由于寻址是确定性的,嵌入可以卸载到主机内存:
- 通过 PCIe 异步预取,与前序 Transformer 块的计算重叠;
- 使用多级缓存结构利用 N-gram 的 Zipf 分布特性;
- 高频模式保留在高速存储,低频模式存放在大容量存储介质中。
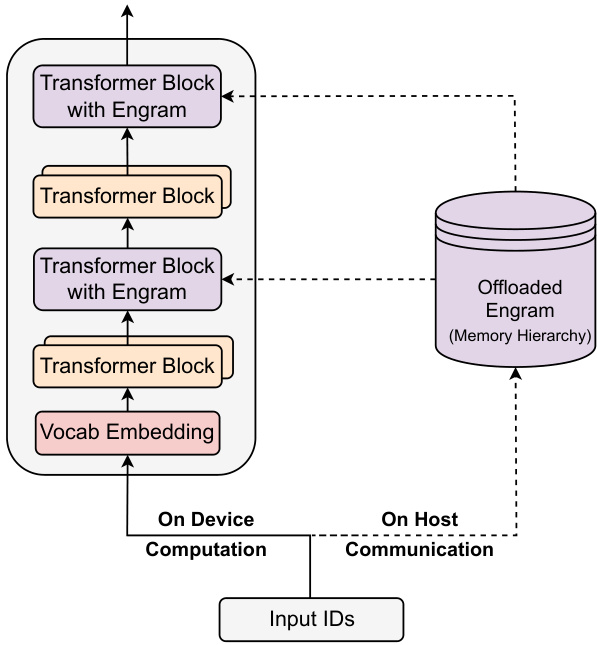
该设计使 Engram 能够扩展到极大的记忆规模,同时对实际推理延迟影响极小。
实验结果
参数分配实验
在计算量匹配条件下,将 75%–80% 的稀疏参数分配给 MoE,其余分配给 Engram 可获得最佳效果:
- 10B 规模验证集损失:1.7109(Engram) vs. 1.7248(MoE)。
在固定计算量下扩展 Engram 的记忆规模可持续带来幂律级别的损失下降,并优于 OverEncoding 方法。
基准测试性能
在等 FLOPs 条件下,Engram-27B(26.7B 参数)显著优于 MoE-27B:
- BBH: +5.0
- HumanEval: +3.0
- MMLU: +3.0
扩展到 Engram-40B 后,预训练损失进一步降低至 1.610,大多数任务得分继续提升。
在等 FLOPs 条件下,所有稀疏模型(MoE 与 Engram)均显著优于 4B 的稠密基线模型。

长上下文评估
Engram-27B 在 LongPPL 与 RULER 基准上全面优于 MoE-27B:
- 在 Multi-Query NIAH 与 Variable Tracking 等复杂检索任务上优势尤为明显;
- 即使仅训练到 41k 步(约为 MoE FLOPs 的 82%),Engram 也能在 LongPPL 上持平、在 RULER 上超过 MoE。

记忆卸载下的推理吞吐
将 100B 参数规模的 Engram 层卸载至 CPU 内存后,吞吐量下降极小:
- 4B 模型:9,031 → 8,858 tok/s
- 8B 模型:6,316 → 6,140 tok/s(仅下降 2.8%)
确定性寻址使得 PCIe 预取能够有效隐藏内存访问延迟。

总结
Engram 将条件记忆提升为一种与 MoE 并列的一等稀疏机制,通过将静态知识存储与动态计算分离,实现了:
- 推理、代码、数学与长上下文任务上的稳定性能提升;
- 对 Transformer 早期层更高效的利用;
- 依托确定性访问与存储卸载的高可扩展系统设计。
这些结果表明,未来的大模型架构应将记忆容量与计算能力视为可以独立扩展的两种核心资源,而不再强制将所有知识压缩进神经权重之中。