Command Palette
Search for a command to run...
DeepSeek-OCR 2:视觉因果流
DeepSeek-OCR 2:视觉因果流
Haoran Wei Yaofeng Sun Yukun Li
一键部署 DeepSeek-OCR 2
摘要
我们提出 DeepSeek-OCR 2,旨在探究一种新型编码器——DeepEncoderV2——在图像语义驱动下动态重排视觉标记(visual tokens)的可行性。传统视觉-语言模型(VLMs)在将视觉标记输入大语言模型(LLM)时,始终以固定的栅格扫描顺序(从左上到右下)进行处理,并采用固定的位置编码。然而,这种处理方式与人类视觉感知机制相悖:人类视觉遵循灵活且语义连贯的扫描模式,其行为由图像内在的逻辑结构所驱动。尤其在面对复杂布局的图像时,人类视觉表现出具有因果关联的序列化处理特征。受此认知机制启发,DeepEncoder V2 被设计为赋予编码器因果推理能力,使其能够在基于 LLM 的内容理解之前,智能地重新排列视觉标记。本研究探索了一种全新范式:是否可通过两个级联的一维因果推理结构,有效实现二维图像的理解,从而为实现真正意义上的二维推理提供一种具有潜力的新架构。代码与模型权重已公开,可访问 http://github.com/deepseek-ai/DeepSeek-OCR-2。
一句话总结
DeepSeek-AI 研究人员推出 DeepSeek-OCR 2,其核心为 DeepEncoder V2,该编码器通过因果推理动态重排视觉标记,取代僵化的光栅扫描处理方式,从而实现更接近人类、语义连贯的图像理解,提升 OCR 与文档分析能力。
核心贡献
- 我们提出 DeepEncoder V2,这是一种视觉编码器,通过从图像语义中推导出的因果推理动态重排视觉标记,取代僵化的光栅扫描顺序,更贴近人类视觉感知。
- 该编码器采用双向与因果注意力机制,在二维图像上实现一维序列推理,形成两级级联的一维范式,推动向真正的二维理解演进,同时保留空间结构。
- 在涉及复杂布局、公式与表格的文档 OCR 任务中评估,DeepSeek-OCR 2 在保持高标记压缩率的同时,相比 DeepSeek-OCR 实现显著性能提升,验证了向语义引导视觉处理的架构转变。
引言
作者利用一种新颖的视觉编码器 DeepEncoder V2,挑战大多数视觉语言模型中僵化的光栅扫描标记排序方式,该方式忽略语义结构,而更贴近人类视觉感知。先前模型将图像块视为固定序列,引入了阻碍复杂布局(如文档或公式)推理的归纳偏置。DeepEncoder V2 引入因果流查询与混合注意力掩码,根据语义上下文动态重排视觉标记,使模型通过级联的一维因果推理处理图像——这是迈向真正二维理解的一步。该架构还为统一多模态编码奠定基础,共享参数可通过模态特定查询处理文本、视觉及其他潜在模态。
数据集
- 作者使用的训练数据集由 OCR 1.0、OCR 2.0 和通用视觉数据组成,其中 OCR 数据占训练混合数据的 80%。
- OCR 1.0 通过将页面划分为文本、公式和表格(比例为 3:1:1)进行更均衡采样,以提升数据平衡性。
- 布局检测标签通过合并语义相似类别进行优化——例如,“图注”与“图标题”被统一。
- 评估时,他们使用 OmniDocBench v1.5,该基准包含 1,355 页中英文文档,涵盖杂志、学术论文与研究报告,共 9 个类别。
- 该基准的多样性与评估标准有助于验证 DeepSeek-OCR 2 的性能,特别是 DeepEncoder V2 的影响。
方法
作者利用一种新颖的编码器架构 DeepEncoder V2,使视觉语言建模流程中实现因果视觉推理。该设计将 DeepEncoder 原先基于 CLIP 的视觉编码器替换为紧凑型语言模型(Qwen2-0.5B),重用其仅解码器结构,通过可学习的因果流查询建模视觉标记重排。如图所示,整体框架保留了 DeepSeek-OCR 的标记化与解码阶段,但在编码器内引入双流注意力机制,以解耦全局视觉表示与序列因果建模。
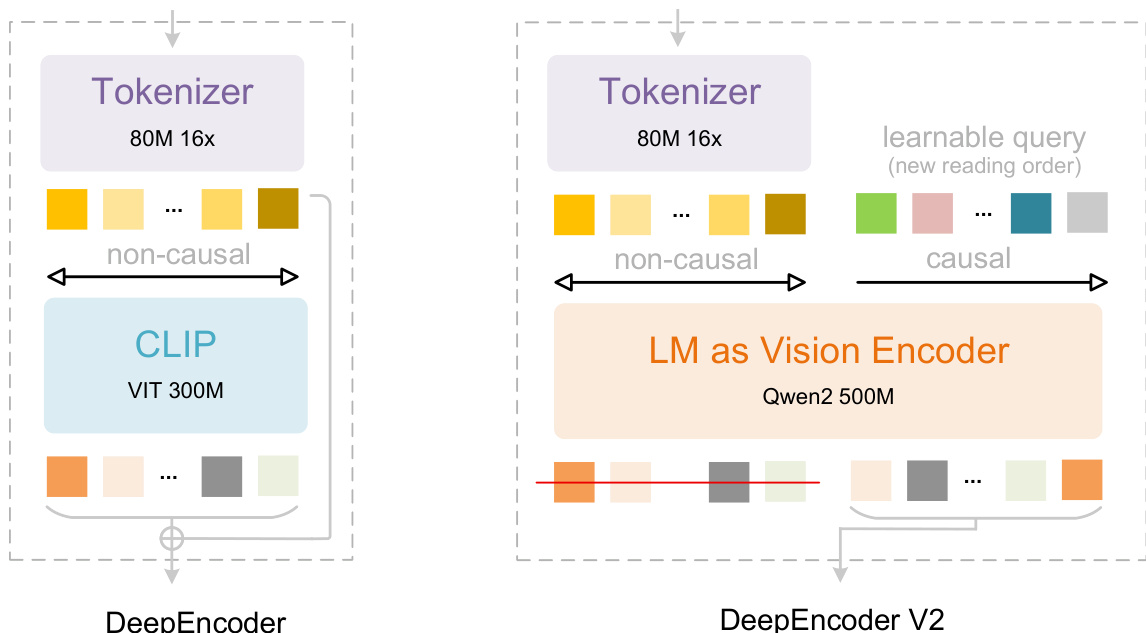
视觉标记器继承自 DeepEncoder,采用 80M 参数的 SAM-base 架构,后接两个卷积层,将图像块压缩为视觉标记,压缩比为 16 倍。该组件输出隐藏维度为 896 的标记,优化以兼容下游 LLM 编码器。该标记器的高效性在处理高分辨率输入时显著节省内存与计算资源。
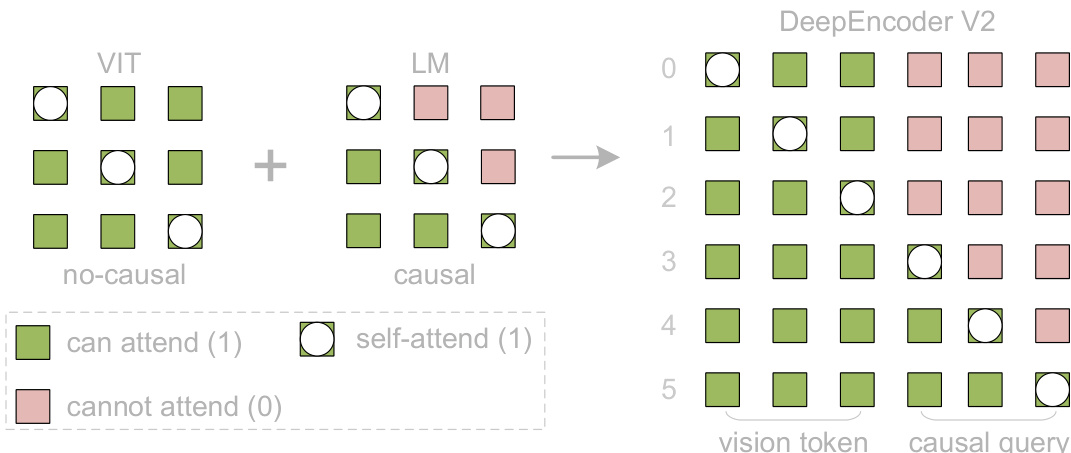
核心创新在于 LLM 风格的视觉编码器,其处理一个由视觉标记与等量可学习因果流标记拼接而成的序列。注意力机制通过块掩码定制:视觉标记采用双向自注意力(类似 ViT),保留全局感受野;因果流标记采用单向下三角注意力(与 LLM 解码器相同)。如图所示,该掩码确保每个因果查询仅关注先前的视觉标记与之前的查询,使编码器能学习语义上有意义的视觉内容重排。
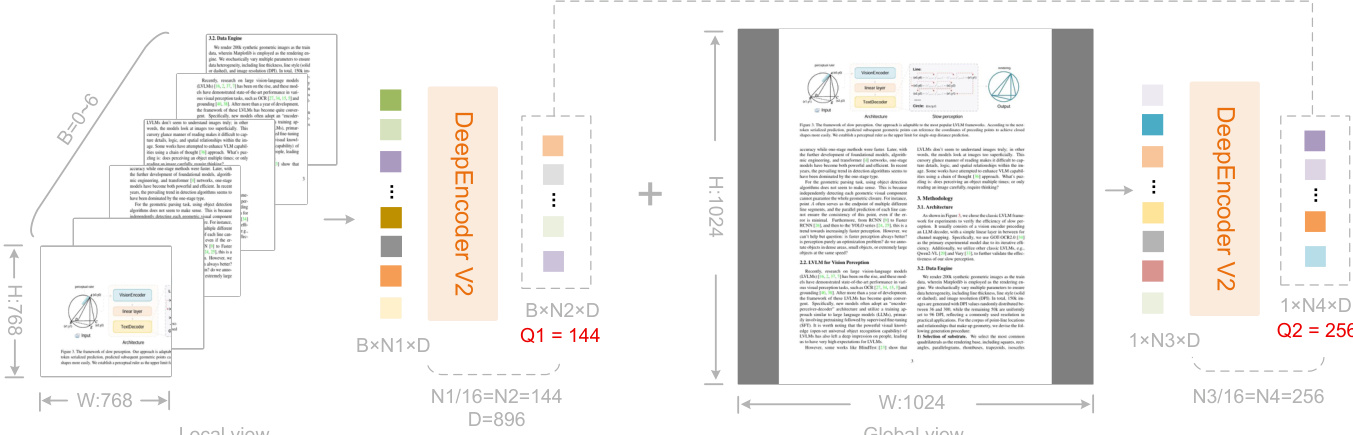
因果流标记数量通过多裁剪策略动态确定:1024×1024 的全局视图生成 256 个标记,最多六个 768×768 的局部裁剪视图各贡献 144 个标记,最终标记总数在 256 至 1120 之间。该设计确保不同分辨率下查询基数一致,并与 Gemini-3 Pro 的最大视觉标记预算对齐。如下图所示,局部与全局视图独立处理后拼接形成最终标记序列。
仅编码器输出的后半部分——即因果流标记——被投影并输入 DeepSeek-3B MoE 解码器。该级联设计支持两阶段因果推理:编码器执行视觉信息的语义重排,解码器则基于重排序列执行自回归生成。整个前向传播形式化为:
O=D(πO(TL(E(I)⊕Q0;M)))其中 E 将输入图像 I 映射为视觉标记 V,Q0 表示可学习的因果查询,⊕ 为序列拼接,TL 为带掩码注意力 M 的 L 层 Transformer,πO 提取因果查询输出,D 为生成输出对数概率 O 的 MoE 解码器。
训练分三阶段进行:使用轻量解码器通过下一标记预测预训练编码器、冻结标记器并联合优化编码器与解码器以增强查询、冻结编码器后专门优化解码器。作者采用多分辨率数据加载器、流水线并行及带余弦衰减的 AdamW,在 160 张 A100 GPU 上扩展训练。
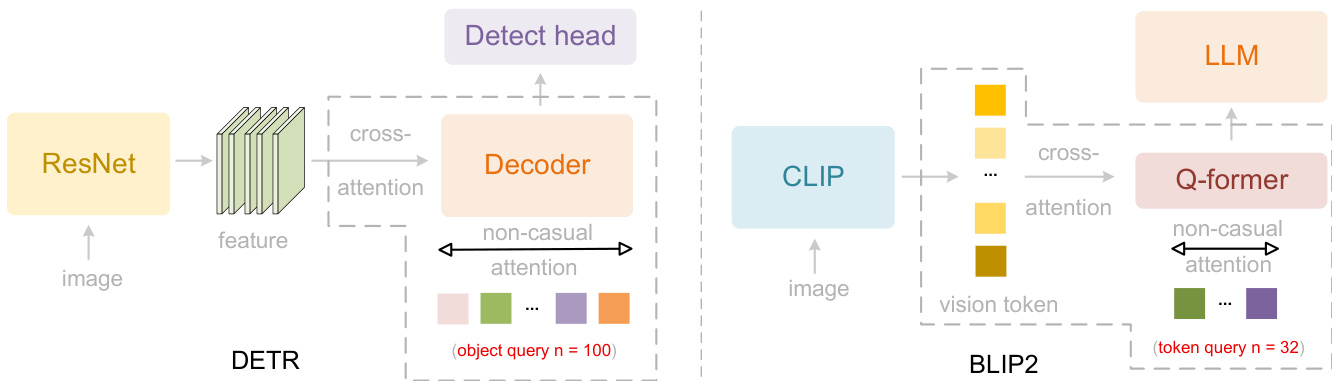
该架构概念上借鉴 DETR 与 BLIP-2 中的并行化查询机制(如下图所示),但将其适配为因果式解码器风格编码器,以桥接二维空间结构与一维语言建模。
最终系统 DeepSeek-OCR 2 保持了前代的图像压缩比与解码效率,同时通过其因果编码器设计在视觉阅读逻辑上实现显著提升。
实验
DeepSeek-OCR 2 在冻结 DeepEncoder V2 的前提下仅微调 LLM,于 OmniDocBench v1.5 上以最小视觉标记预算取得 91.09% 准确率,优于前代 3.73%,并将阅读顺序编辑距离从 0.085 降至 0.057。在相似标记约束下,其文档解析编辑距离(0.100)亦优于 Gemini-3 Pro(0.115),证实其高效的标记压缩与强大的结构理解能力。尽管在报纸等文本密集文档上因标记限制与数据稀缺仍有提升空间,但其在所有文档类型中阅读顺序表现始终优异。在生产环境中,其用户图像重复率从 6.25% 降至 4.17%,PDF 重复率从 3.69% 降至 2.88%,验证了其在 LLM 集成中的实用鲁棒性。
作者在生产环境中以重复率为主要指标,对比 DeepSeek-OCR 2 与 DeepSeek-OCR。结果显示,DeepSeek-OCR 2 在在线用户日志图像上降低重复率 2.08%,在 PDF 预训练数据上降低 0.81%,表明其实际可靠性提升。DeepSeek-OCR 2 在用户日志图像上降低重复率 2.08%,PDF 数据重复率下降 0.81%。更低的重复率表明生产环境中更优的逻辑视觉理解能力。

作者在 OmniDocBench v1.5 上将 DeepSeek-OCR 2 与先前模型对比,显示其以最小视觉标记预算取得 91.09% 总体准确率。结果表明,相比 DeepSeek-OCR,其在文本识别与阅读顺序准确率上显著提升,验证了架构改进。该模型在公式、表格与阅读顺序任务中亦表现强劲。DeepSeek-OCR 2 仅用 1120 个视觉标记即实现 91.09% 总体准确率,优于使用 6000+ 标记的模型。阅读顺序编辑距离从 0.085 降至 0.057,表明 DeepEncoder V2 更优的视觉标记排列能力。文本识别编辑距离改善 0.025,公式与表格指标分别提升 6.17 与 3.05 分。

作者使用编辑距离指标对比 DeepSeek-OCR 2、Gemini-3 Pro 与 Seed-1.8 在文档元素上的表现。DeepSeek-OCR 2 以仅 1120 个视觉标记取得最低总体编辑距离 0.100,优于相似标记预算下的 Gemini-3 Pro(0.115)。这表明其更优的标记效率与文档解析准确性。DeepSeek-OCR 2 总体编辑距离为 0.100,低于 Gemini-3 Pro 的 0.115,仅使用 1120 个视觉标记,与 Gemini-3 Pro 标记预算相当,在阅读顺序(0.057)与表格(0.096)指标上表现更优。

作者在九类文档中使用编辑距离指标对比 DeepSeek-OCR 与 DeepSeek-OCR 2 的文本识别与阅读顺序表现。结果显示 DeepSeek-OCR 2 总体优于基线,尤其在阅读顺序准确率上,但在报纸文本上误差更高。对比突显了更新模型的优势与待改进之处。DeepSeek-OCR 2 在所有文档类型中提升阅读顺序准确率,报纸文本识别仍是弱点(编辑距离 > 0.13),除报纸与笔记外,多数类别文本识别有所改善。

DeepSeek-OCR 2 在生产日志、PDF 与 OmniDocBench v1.5 基准上,以重复率与编辑距离指标与前代及竞争模型对比,展示其改进的视觉理解与标记效率。其在用户日志上降低重复率 2.08%,在 PDF 数据上降低 0.81%,并以仅 1120 个视觉标记实现 91.09% 总体准确率——超越使用 6000+ 标记的模型——同时提升阅读顺序与文本识别准确率。相比 Gemini-3 Pro,其在相同标记预算下取得更低总体编辑距离 0.100,尤其在阅读顺序与表格解析上表现优异,但在报纸文本识别上仍有不足。