Command Palette
Search for a command to run...
delta-mem:大型语言模型的高效在线记忆机制
delta-mem:大型语言模型的高效在线记忆机制
Jingdi Lei Di Zhang Junxian Li Weida Wang Kaixuan Fan Xiang Liu Qihan Liu Xiaoteng Ma Baian Chen Soujanya Poria
摘要
大型语言模型(LLM)在长期助手(Long-term Assistants)和智能体(Agent)系统中,对历史信息的积累与复用需求日益增长。单纯扩大 Context Window 不仅成本高昂,且往往无法确保上下文被有效利用。为此,我们提出了 δ-mem,这是一种轻量级记忆机制,旨在通过引入紧凑的联想记忆在线状态(Online State of Associative Memory),增强冻结的(Frozen)全注意力(Full-Attention)骨干网络。δ-mem 利用 Delta-rule 学习将历史信息压缩为固定大小的状态矩阵,并在生成过程中利用该状态的读取结果(Readout),对骨干网络的注意力计算生成低秩修正(Low-rank Corrections)。仅凭借 8×8 的在线记忆状态,δ-mem 的平均得分即可达到冻结骨干网络的 1.10 倍,以及最强非 δ-mem 记忆基线的 1.15 倍。在重度依赖记忆能力的 Benchmark 上,其提升更为显著:在 MEMORYAGENTBENCH 上达到 1.31 倍,在 LCoMo 上达到 1.20 倍,同时很大程度上保留了通用能力。这些结果表明,通过与注意力计算直接耦合的紧凑在线状态,即可实现有效的记忆功能,而无需进行全量微调(Full Fine-tuning)、骨干网络替换或显式的上下文扩展。
一句话总结
作者提出了 δ-mem,一种轻量级记忆机制,通过 delta-rule 学习更新 8 × 8 在线关联状态,为冻结的全注意力主干网络增强低秩注意力计算校正,将平均分数提升至冻结主干网络的 1.10 倍和最强非 δ-mem 记忆基线的 1.15 倍,同时在 MEMORYAGENTBENCH 上达到 1.31 倍,在 LCoMo 上达到 1.20 倍,无需全量微调、主干网络替换或显式上下文扩展,在很大程度上保留了通用能力。
核心贡献
- δ-mem 通过紧凑的在线关联记忆状态增强冻结的全注意力主干网络,将过去信息压缩为固定大小的状态矩阵。该状态通过 delta-rule 学习进行更新,无需全量微调、主干网络替换或显式上下文扩展即可维护历史信息。
- 在生成过程中,该方法查询在线状态以提取上下文相关信号,这些信号转化为骨干网络注意力组件的低秩校正。这种配置允许关联记忆直接参与前向计算,同时保持骨干网络冻结。
- 在重记忆基准测试上的评估显示,8 × 8 在线记忆状态将平均分数提升至冻结主干网络的 1.10 倍,并在 MEMORYAGENTBENCH 上达到 1.31 倍。这些结果证明了有效的记忆实现,无需依赖扩展显式上下文或重型外部检索模块。
引言
大型语言模型在长期助手和 agent 系统中面临重大挑战,需要在扩展交互过程中积累和重用历史信息。简单地扩展上下文窗口计算成本高昂,且常导致上下文退化,而现有的记忆机制存在检索噪声、集成复杂或表示静态等问题。为了解决这些问题,作者提出了 delta-mem,一种轻量级机制,通过紧凑的在线关联记忆状态增强冻结的全注意力主干网络。该系统将过去信息压缩为通过 delta-rule 学习更新的固定大小矩阵,并将低秩校正直接应用于主干网络的注意力计算。这种方法在重记忆基准测试上实现了卓越性能,无需全量微调或显式上下文扩展。
方法
作者引入了 δ-mem,这是一种旨在通过紧凑的在线关联记忆状态增强冻结全注意力主干网络的记忆机制。该方法使得历史信息的动态维护能够直接与主干网络的注意力计算耦合。整体框架通过从前一状态读取关联记忆信号,利用这些信号引导注意力,随后将当前信息写入状态来运行。这允许模型在不更新主干网络参数的情况下将历史压缩为演变状态。参考框架图以获取此设计的视觉概述,该图突出了 LLM 主干网络与 δ-Mem 模块之间的交互。
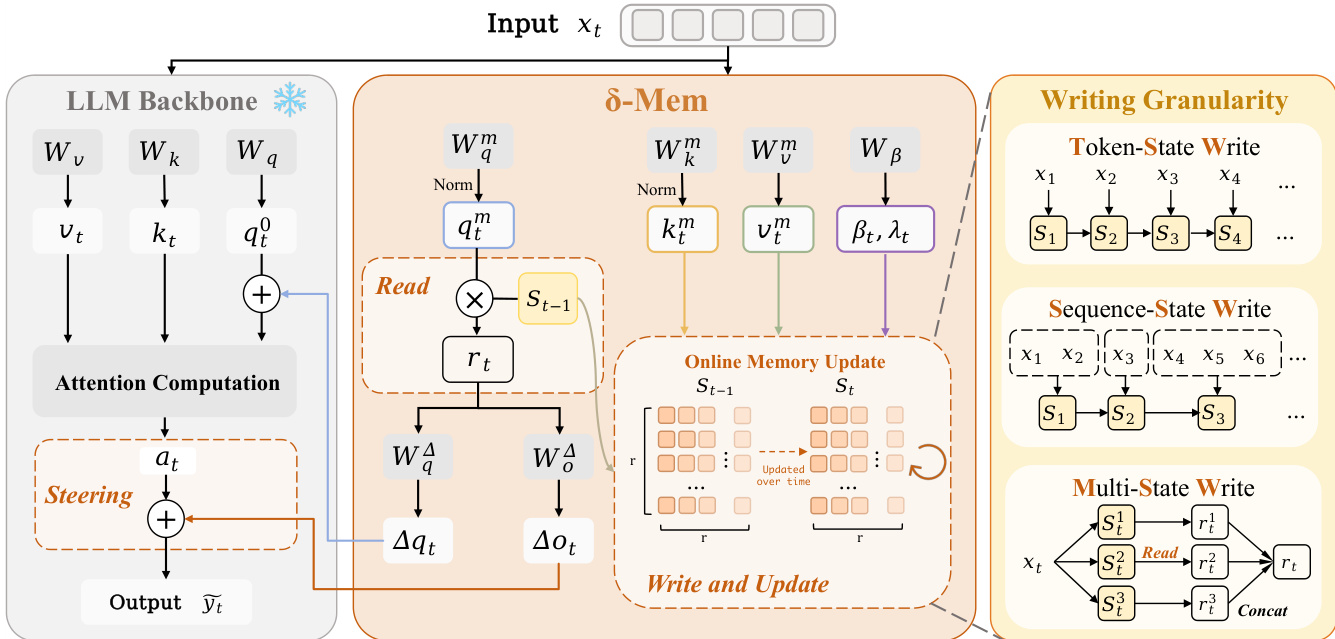
为了形成在线状态,该方法将当前位置的隐藏状态 xt 投影到低维关联记忆空间。这产生查询、键和值向量 qtm,ktm,vtm∈Rr。查询和键向量经过 L2 归一化,以减轻长序列递归期间由尺度漂移引起的状态不稳定性。此外,写入和保留门 βt 和 λt 由当前隐藏状态确定,以允许对状态更新进行维度级调整。
在写入新信息之前,系统从前一状态 St−1 读取。读取向量 rt=St−1qtm 提供与标准注意力互补的连续关联记忆信号。这些信号通过两个轻量级线性映射引导注意力计算。读取信号被投影为查询侧校正 Δqt 和输出侧校正 Δot。查询侧校正添加到冻结主干网络的原始查询中,输出侧校正添加到注意力操作之后。这种低秩校正允许同一组参数在不同历史下产生不同的引导效果。
在注意力计算之后,该方法使用维度级门控 delta-rule 将当前信息写入在线状态。更新过程涉及保留前一状态,沿当前键方向移除旧预测分量,并将新值写入同一方向。这确保记忆状态通过受控遗忘的误差校正进行更新,而不是不加选择地累积新的外积。
该框架还探索了不同的写入粒度以适应各种交互模式。作者考察了三种策略:Token-State Write (TSW),它在每个 token 位置更新状态以实现细粒度信息;Sequence-State Write (SSW),它在消息段内平均隐藏状态以减少冗余写入;以及 Multi-State Write (MSW),它将记忆分解为多个并行子状态,以减少事实任务进度等不同类型信息之间的相互干扰。
最后,δ-mem 使用标准的监督微调 (SFT) 损失进行训练。在训练期间,上下文 token 首先写入在线状态以生成 SC。冻结的主干网络随后仅接收查询和响应 token,而存储的状态引导注意力。损失计算为响应 token 上的自回归交叉熵,优化可训练的 δ-mem 参数,同时保持主干网络参数冻结。
实验
评估在通用推理和重记忆基准测试上,使用各种 LLM 主干网络,将 delta-mem 与文本、参数和外部通道记忆基线进行了评估。结果表明,delta-mem 通过利用在线状态稳健地保留历史信息,始终优于竞争方法,即使在无需显式重放的情况下也能有效恢复上下文。消融研究进一步证实,在所有层以及查询和输出分支中注入记忆信号可产生最佳性能,而效率测试显示,与更重的替代方案相比,内存和参数开销可忽略不计。
作者分析将记忆校正注入不同注意力头的影响,以确定记忆集成的最佳接口。结果表明,虽然仅输出分支是最有效的单一配置,但组合多个头可产生更优性能,完整集合实现了最高的总体分数。在单头变体中,输出分支表现最佳,显著优于键分支。组合所有头的完整配置实现了最高的总体平均分数,并在 HotpotQA 上表现最佳。组合查询和输出头在重记忆基准测试上提供了强有力的结果,为完整配置提供了有竞争力的替代方案。
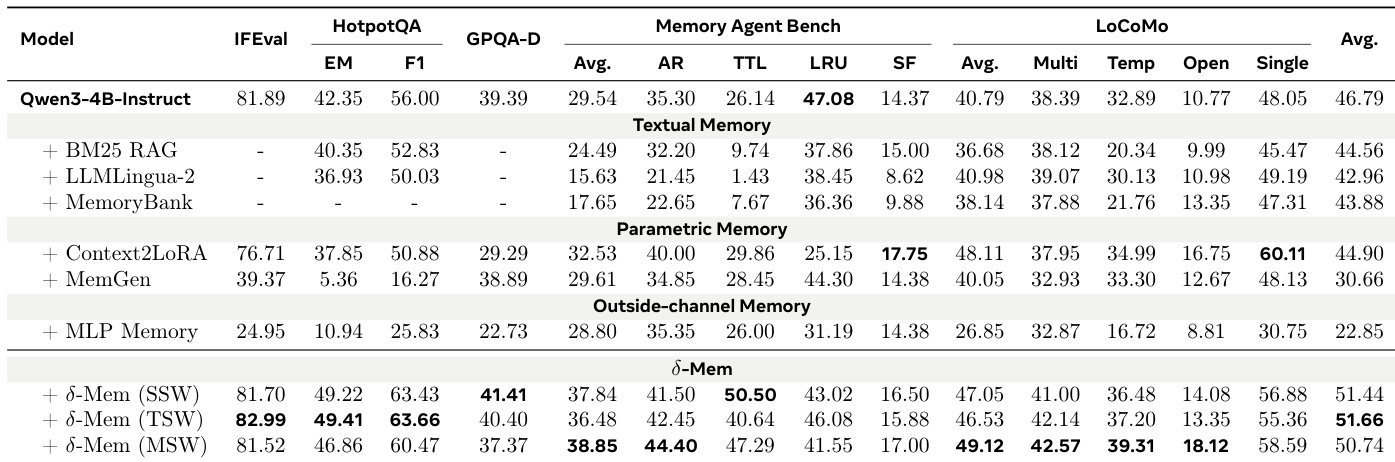
作者在 Qwen3-4B-Instruct 主干网络上评估了提出的记忆机制与各种基线,包括文本检索和参数适配方法。结果表明,提出的方法在通用推理和重记忆基准测试上始终优于所有其他方法,特别是在需要长期保留和检索的任务中。虽然基线方法在特定类别中显示出不一致的提升或局限性,但提出的方法在整体平均性能上显示出稳健的提升。与文本、参数和外部通道记忆基线相比,提出的方法实现了最高的平均性能分数。在 LoCoMo 和 Memory Agent Bench 等重记忆基准测试上观察到显著改进,模型在其中更好地保留和利用信息。提出的方法的变体在指令遵循和多跳推理任务上通常优于基础模型和其他记忆机制。
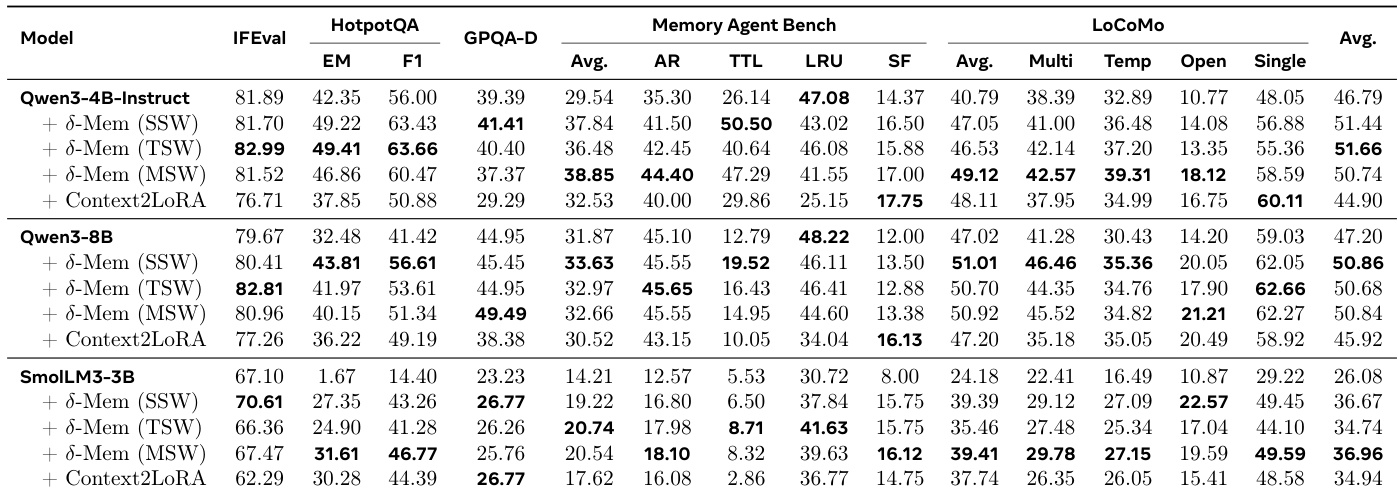
作者在三个主干模型上将 delta-mem 方法与 Context2LoRA 等基线进行了评估。结果表明,delta-mem 始终优于基础模型和 Context2LoRA 基线,在 MemoryAgentBench 和 LoCoMo 等重记忆基准测试上观察到最显著的提升。delta-mem 内部的不同写入策略根据模型容量显示出不同的有效性,TSW 在 4B 模型上表现最佳,而 MSW 在较小的 3B 模型上推动了实质性改进。与基础和 Context2LoRA 基线相比,delta-mem 在所有测试的主干模型上实现了最高的平均分数。与通用推理任务相比,在 MemoryAgentBench 和 LoCoMo 等重记忆基准测试上性能提升最为明显。最佳写入策略因模型大小而异,TSW 在 Qwen3-4B-Instruct 上领先,而 MSW 为 SmolLM3-3B 提供了最大的提升。
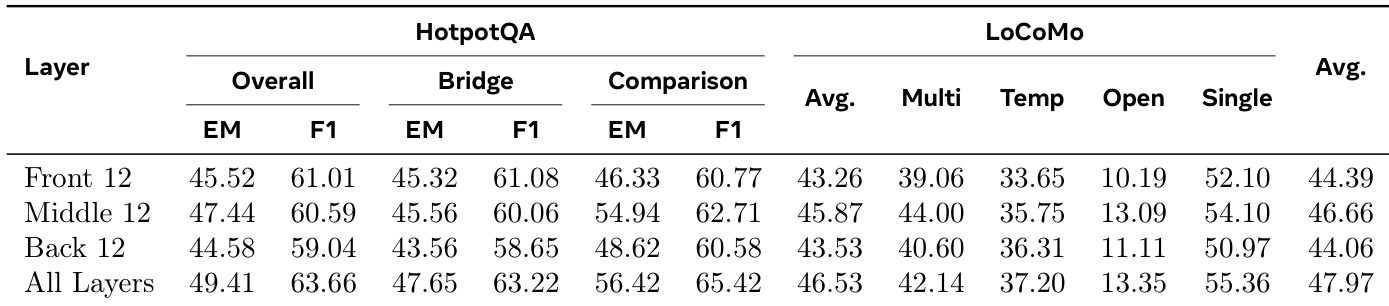
作者评估了记忆校正在不同模型层中的插入深度,以确定最佳放置位置。结果表明,将该机制应用于所有层在 HotpotQA 和 LoCoMo 基准测试上均实现了最强性能。在部分配置中,中间层比前端或后端层提供了更有效的记忆注入接口。将记忆校正应用于所有层实现了最佳总体平均分数和 HotpotQA 分数。中间层配置在平均性能上优于前端和后端层变体。与全深度或中间层策略相比,前端和后端层注入导致分数较低。
作者通过分析注意力头和模型层中的注入点来评估记忆集成的最佳接口,发现利用所有组件可产生最强性能。与文本和参数基线的比较研究表明,提出的方法始终优于现有方法,特别是在需要长期保留的任务中。此外,在不同主干模型上的测试证实了稳健的改进,特定的写入策略根据模型容量证明更有效。