Command Palette
Search for a command to run...
用于样本高效连续控制的去偏模型表示
用于样本高效连续控制的去偏模型表示
Jiafei Lyu Zichuan Lin Scott Fujimoto Kai Yang Yangkun Chen Saiyong Yang Zongqing Lu Deheng Ye
摘要
基于模型的表示法最近作为一种有前景的框架脱颖而出,该框架将潜在动态信息嵌入到表示中,以用于下游的离策略演员-评论家学习。它隐式地结合了无模型和基于模型方法的优势,同时避免了与基于模型方法相关的训练成本。然而,现有的基于模型的表示方法可能无法捕捉到关于相关变量的足够信息,并且可能会过度拟合回放缓冲区中的早期经验。这会导致表示和演员-评论家学习中的偏差,从而导致性能下降。为了解决这个问题,我们提出了去偏的基于模型的Q学习表示法,即DR.Q算法。DR.Q显式地最大化当前状态-动作对表示与下一状态表示之间的互信息,同时最小化它们的偏差,并使用衰减优先经验回放采样转移。我们在多个连续控制基准测试中对DR.Q进行了评估,使用一组超参数,结果表明DR.Q可以匹配或超越最近的强基线,有时甚至大幅超越它们。我们的代码可在https://github.com/dmksjfl/DR.Q获取。
一句话总结
DR.Q 是一种用于样本高效连续控制的去偏基于模型的表示框架。该框架显式最大化当前状态-动作表示与下一状态表示之间的互信息,同时最小化二者偏差,并采用衰减优先经验回放以缓解早期经验过拟合问题。最终,该方法仅使用单一超参数配置,即可在多种连续控制基准测试中达到或超越强基线性能。
核心贡献
- 提出 DR.Q,一种用于离策略 Q 学习的去偏基于模型的表示框架,有效缓解现有基于动力学方法中固有的表示偏差与早期经验过拟合问题。
- 该算法显式最大化当前状态-动作表示与下一状态表示之间的互信息,同时最小化二者偏差,并采用衰减优先经验回放机制以平衡样本价值与时间新鲜度。
- 在多项连续控制基准测试中的评估表明,该框架仅凭单一固定超参数配置即可稳定达到或超越近期强基线,部分场景下的性能提升幅度显著。
引言
基于模型的表示学习已成为离策略强化学习中极具潜力的框架,通过将潜在环境动力学嵌入特征表示来提升样本效率,同时避免完整基于模型规划带来的高昂训练成本。然而,先前的方法通常仅最小化表示偏差并依赖标准经验回放,这未能最大化状态-动作特征与下一状态特征之间的互信息,且会因过度拟合早期经验而引入首因偏差。为克服这些挑战,作者引入 DR.Q 算法,该算法在最小化偏差的同时显式最大化互信息,以确保表示能够捕捉更丰富的任务相关信息。此外,作者提出一种衰减优先经验回放策略,通过降低旧转移数据的权重并优先采样高价值新样本,最终在连续控制基准测试中实现更稳定高效的 Actor-Critic 学习。
数据集
作者围绕三大连续控制基准套件构建评估体系,具体如下:
- 构成与来源: 该框架整合了 Gym MuJoCo v4、DMC 套件与 HumanoidBench,以覆盖标准移动、不同复杂度操作任务以及高维人形机器人任务。
- 子集规范:
- Gym MuJoCo 包含五个广泛使用的带向量观测的移动环境。
- DMC 套件包含 28 个本体感知任务,划分为 DMC-Easy(21 个任务)与 DMC-Hard(四个狗形任务与三个类人任务)。视觉变体将前三次观测堆叠并调整分辨率至 84×84 RGB 帧。
- HumanoidBench 包含 28 个 Unitree H1 移动任务,分为 14 个无灵巧手环境与 14 个集成灵巧手环境。
- 使用与处理: 作者仅将这些环境用于算法评估而非训练。所有基准测试均运行一百万个环境步长,DMC 与 HumanoidBench 通过动作重复次数为二来实现该步长。累积回报分数采用随机策略基线进行归一化,并结合 TD3 参考分数或任务成功阈值,以确保跨环境聚合的一致性。
- 额外处理细节: 作者通过记录各环境的随机回报与参考成功分数构建元数据。观测处理针对视觉任务进行帧堆叠与尺寸调整,本体感知任务则保留原始向量输入。DMC 与 HumanoidBench 统一应用动作重复机制,以使其有效展开步长与 MuJoCo 直接运行的一百万步评估保持一致。
方法
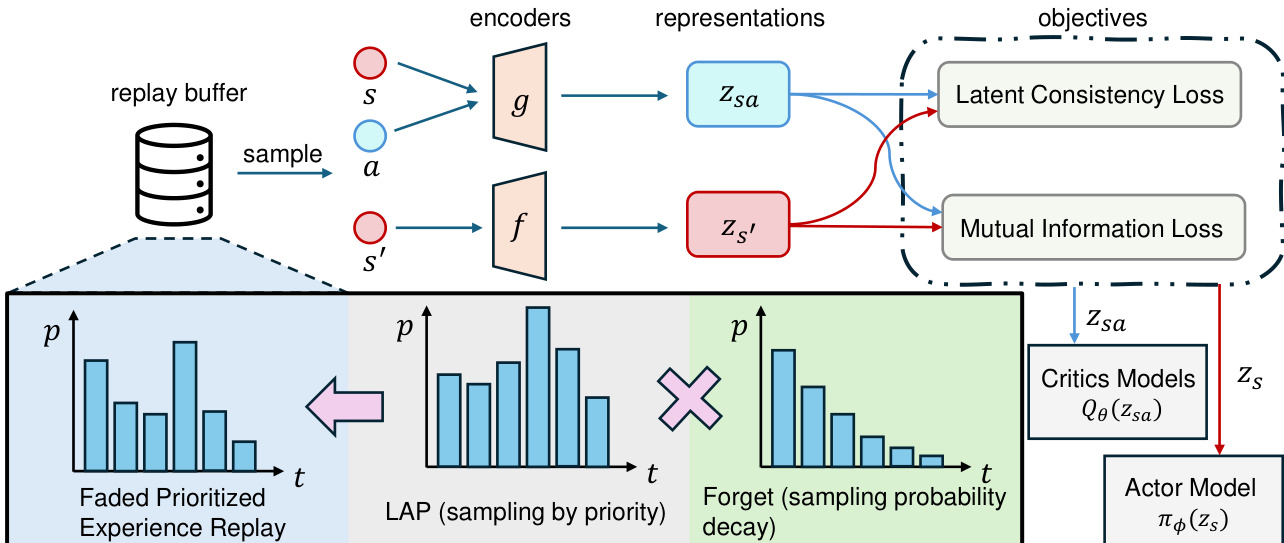
DR.Q 算法运行于一个两阶段框架内,该框架将基于模型的表示学习与下游策略及价值函数优化解耦。整体架构如图所示,起始于一个存储转移数据 (s,a,r,s′,d) 的回放缓冲区。这些转移数据通过衰减优先经验回放机制进行采样,该机制结合基于 TD 误差的优先级与旧转移数据采样概率的指数衰减,确保在聚焦近期高误差经验的同时避免对过时数据的过拟合。
采样的转移数据经过两个主要编码器处理:状态编码器 f 与状态-动作编码器 g。状态编码器将原始状态 s 映射为潜在状态表示 zs=f(s),状态-动作编码器则接收状态表示 zs 与动作 a,生成状态-动作表示 zsa=g(zs,a)。该状态-动作表示随后被线性 MDP 预测器用于预测下一状态表示 z^s′ 与奖励 r^。下一状态表示 z~s′ 源自目标状态编码器网络,该网络会定期更新以维持稳定性。编码器训练目标由三个部分组成:奖励损失、潜在动力学一致性损失与互信息损失。奖励损失通过对奖励的双热编码计算交叉熵得出。潜在动力学一致性损失最小化预测值 z^s′ 与目标值 z~s′ 之间的均方误差。互信息损失作为核心创新点,通过 InfoNCE 损失实现,旨在最大化 zsa 与 z~s′ 之间的互信息,确保表示不仅在数值上接近,且在信息量上更为丰富。
实验
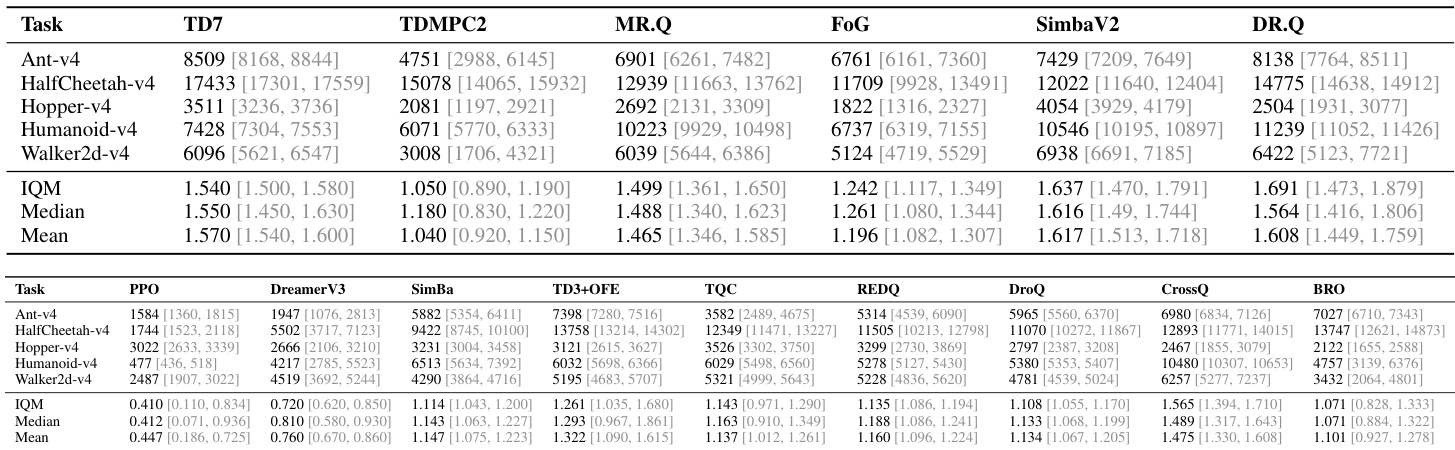
DR.Q 的评估涵盖 MuJoCo、DMC 套件与 HumanoidBench 基准测试中的 73 项任务,采用单一固定超参数配置以测试其相对于主流无模型与基于模型基线的泛化能力。主实验表明,该方法在多种连续控制领域中稳定实现更优的样本效率与渐近性能,尤其在高维与视觉任务中表现突出。消融实验进一步验证了其核心架构设计,结果显示 InfoNCE 与潜在动力学目标能够生成结构化更强、鲁棒性更高的状态表示,而衰减优先经验回放策略可有效优先采样近期高误差转移数据,避免过度依赖过时数据。综合来看,这些发现证实 DR.Q 为复杂强化学习环境中的表示学习提供了一个高效且通用的框架。
作者使用归一化性能指标,在多项连续控制基准测试(包括 MuJoCo、DMC 与 HumanoidBench)中将 DR.Q 与一系列强基线方法进行对比。结果表明,DR.Q 稳定优于或持平于领先方法,尤其在挑战性任务中表现显著,相较于 MR.Q 与 SimBaV2 取得明显提升。分析过程包含消融实验,凸显了 InfoNCE 损失与衰减优先经验回放等关键组件的重要性。DR.Q 在多项基准测试中均优于 MR.Q 与 SimBaV2 等强基线,尤其在复杂任务中优势明显。InfoNCE 损失与衰减 PER 采样策略对 DR.Q 的性能至关重要,移除任一组件均会导致性能显著下降。可视化结果及对冗余状态输入鲁棒性的提升表明,DR.Q 学习到的状态表示比 MR.Q 更具结构性与信息量。
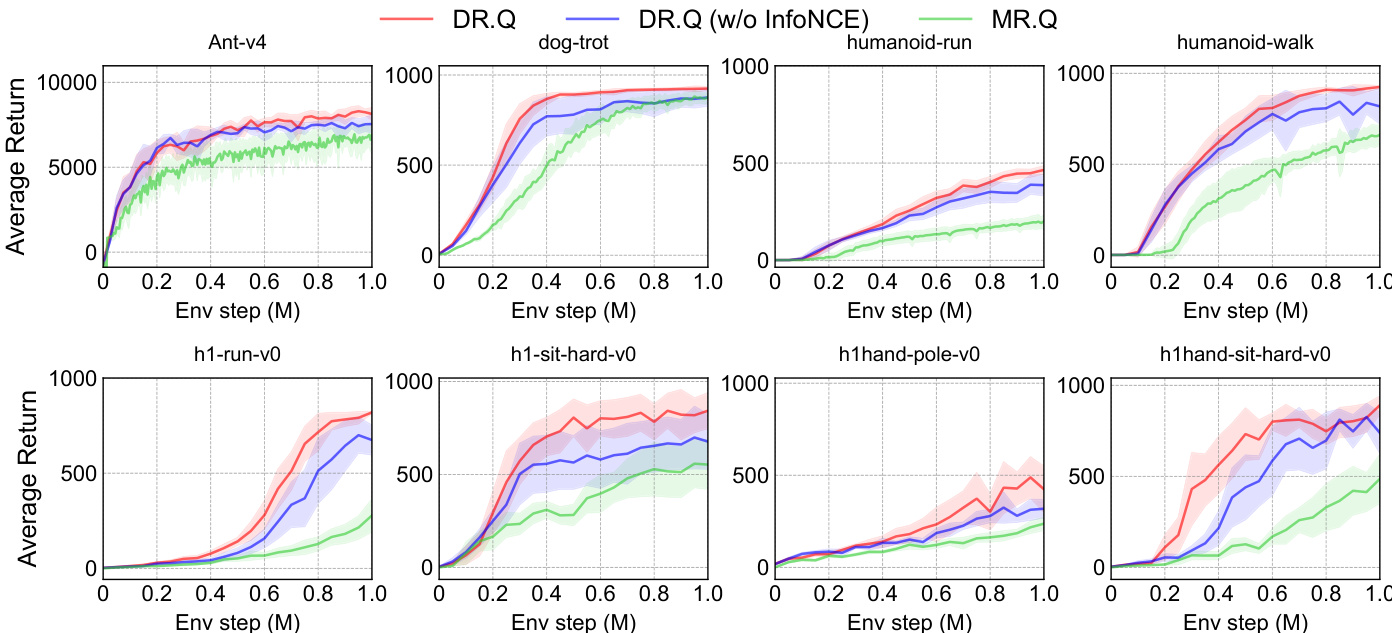
作者将 DR.Q 与其变体及基线方法在多项连续控制任务中进行对比,证明 DR.Q 在挑战性任务上实现了更高的平均回报与更优的样本效率。结果表明,移除 InfoNCE 损失或衰减 PER 采样策略等关键组件会导致性能下降,印证了其对稳健学习的重要性。DR.Q 在多样化任务中持续优于 MR.Q 与 SimBaV2 等基线,尤其在高维与复杂环境中表现突出。InfoNCE 损失对学习有效表示至关重要,尤其适用于包含冗余信息(如涉及灵巧手)的任务。衰减 PER 通过优先采样近期高影响力经验并降低过时数据的影响,有效提升了样本效率。
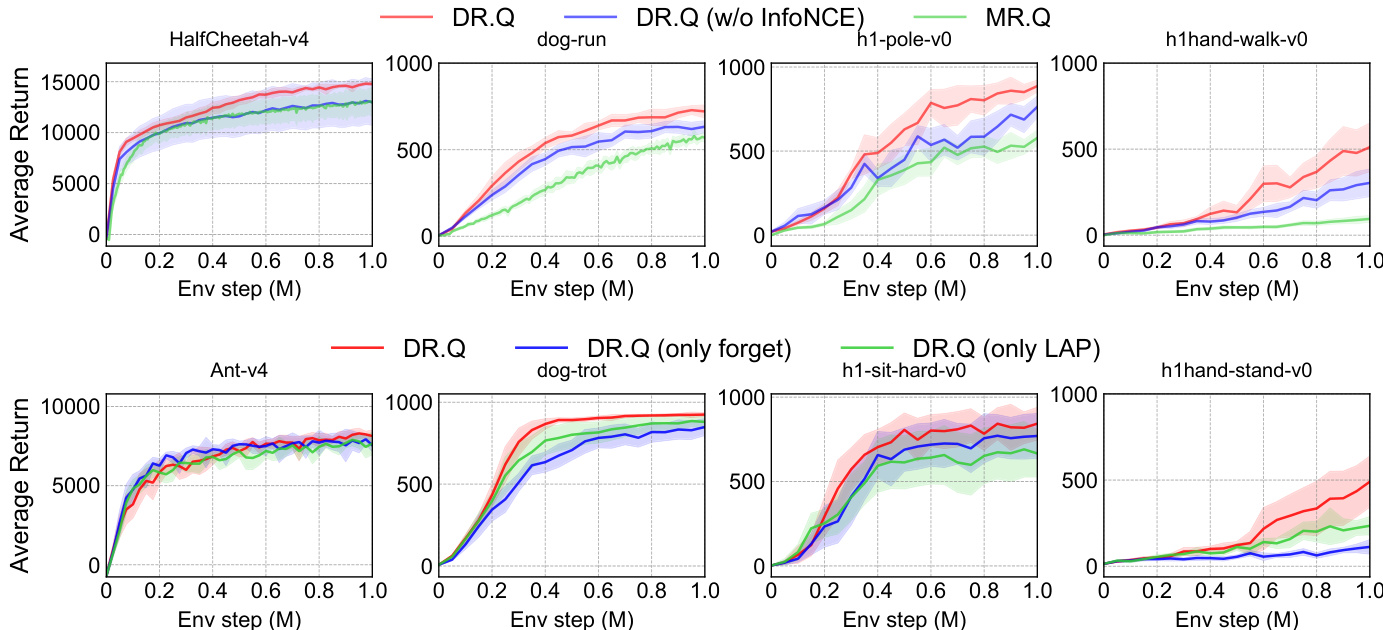
作者开展消融实验以评估 DR.Q 中关键设计选择的影响,包括 InfoNCE 损失与衰减优先经验回放(PER)机制。结果表明,移除 InfoNCE 损失会导致性能下降,尤其在高维任务中更为明显;而在衰减 PER 中省略遗忘机制或 LAP 组件同样会削弱性能与样本效率。完整 DR.Q 模型在所有测试环境中均稳定优于其变体。移除 InfoNCE 损失会显著降低性能,尤其在具有高维状态空间的复杂任务中。结合遗忘机制与 LAP 的衰减 PER 机制对实现最优性能与样本效率不可或缺。DR.Q 在所有评估任务中持续优于其变体,印证了 InfoNCE 损失与衰减 PER 的重要性。
作者将 DR.Q 与 MR.Q、TDMPC2 等多种基线方法在 DMC 套件的多个视觉控制任务中进行对比。结果表明,DR.Q 在大多数任务中实现了更高的平均回报与更快的学习曲线,尤其在 visual-dog-run 与 visual-hopper-stand 任务中表现卓越。DR.Q 在样本效率与最终性能上均稳定优于 MR.Q 与 TDMPC2,印证了其设计选择的有效性。DR.Q 在多数视觉控制任务中的平均回报高于 MR.Q 与 TDMPC2。DR.Q 展现出更快的学习速度与更优的样本效率,尤其在 visual-dog-run 与 visual-hopper-stand 等挑战性任务中。DR.Q 持续优于 MR.Q,表明其额外设计组件的有效性。
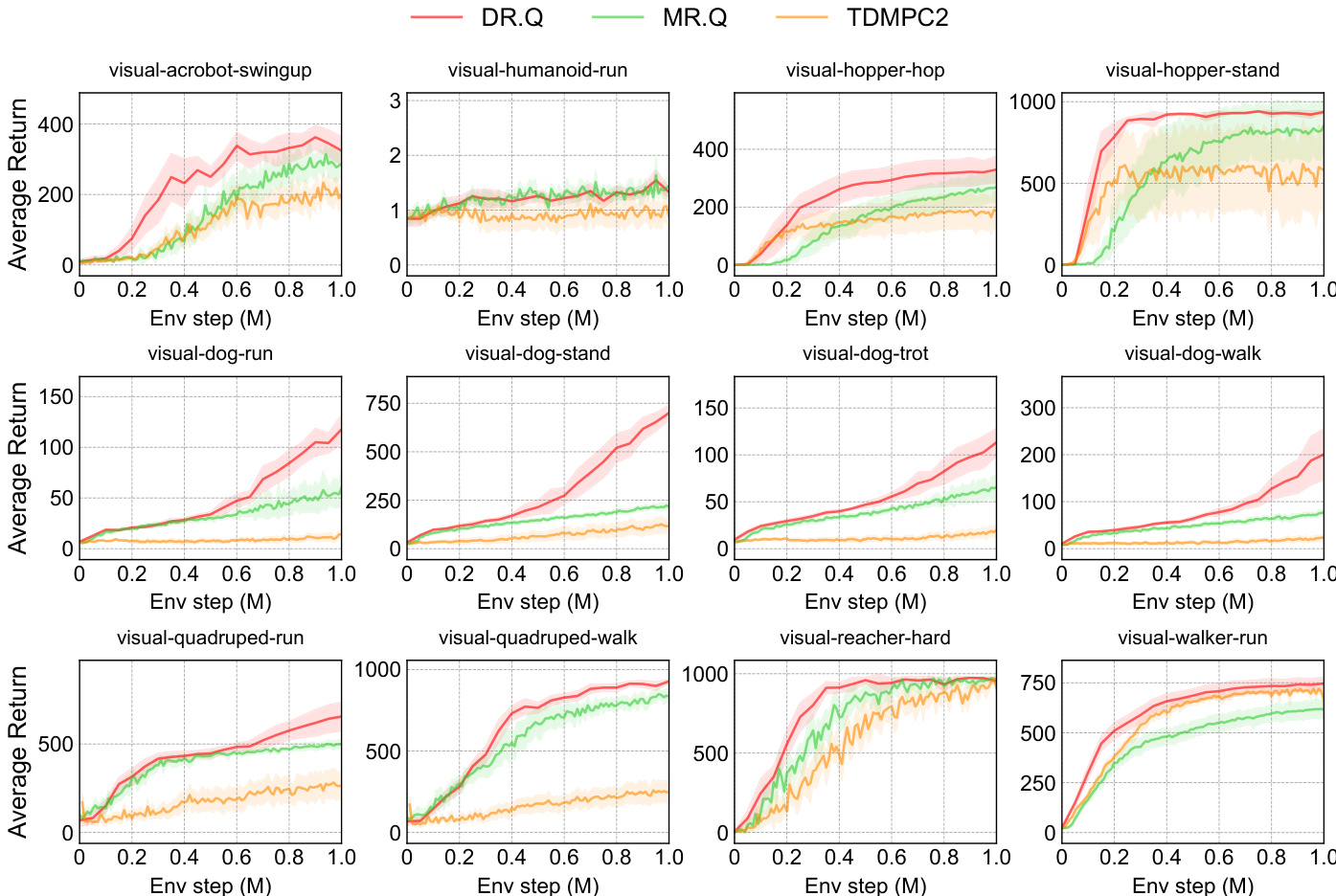
作者将 DR.Q 在多项连续控制基准测试中进行评估,并将其性能与一系列无模型及基于模型基线进行对比。结果表明,DR.Q 稳定达到或超越领先方法性能,尤其在挑战性任务中表现突出,并展现出更优的样本效率。消融实验验证了 InfoNCE 损失与衰减优先经验回放等 DR.Q 关键组件的有效性。DR.Q 在多样化连续控制任务(包括高维状态空间任务)中均取得具有竞争力或更优的性能,相较于强基线优势明显。InfoNCE 损失与衰减优先经验回放是核心组件,移除二者会导致挑战性任务中的性能显著下降。DR.Q 的样本效率优于多种基线,在复杂环境中常大幅领先。
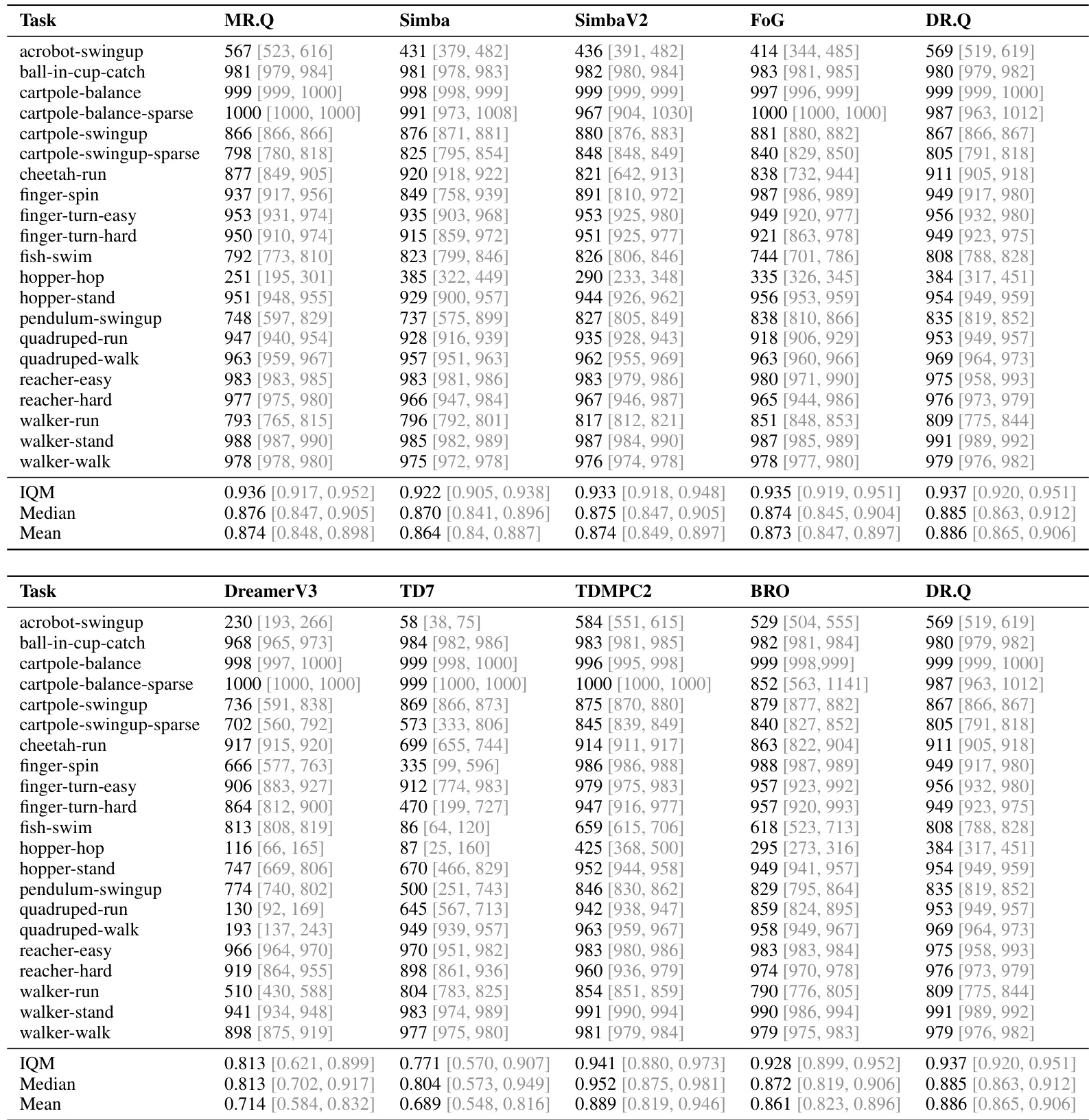
作者将 DR.Q 与多种无模型及基于模型基线在多项连续与视觉控制基准测试(包括 MuJoCo、DMC 与 HumanoidBench)中进行评估。主实验表明,该方法在任务性能与样本效率上稳定达到或超越领先方法,尤其在复杂与高维环境中表现突出。消融实验进一步验证了 InfoNCE 损失与衰减优先经验回放是至关重要的设计选择,移除任一组件均会显著损害学习稳定性与表示质量。总体而言,研究结果证实 DR.Q 能够成功学习结构化状态表示,并在处理冗余环境信息时保持稳健的学习动态。