Command Palette
Search for a command to run...
ELF:嵌入式语言流
ELF:嵌入式语言流
Keya Hu Linlu Qiu Yiyang Lu Hanhong Zhao Tianhong Li Yoon Kim Jacob Andreas Kaiming He
摘要
扩散模型与基于流的模型已成为生成连续数据(例如图像和视频领域)的事实标准。它们的成功也引发了业界将它们应用于语言建模领域的日益增长的兴趣。与图像领域的对应模型不同,当前主流的扩散语言模型(DLMs)主要基于离散 token 进行操作。在本文中,我们证明了只需对离散域进行极少量适配,即可使连续 DLMs 变得高效有效。我们提出了嵌入式语言流(Embedded Language Flows, ELF),这是一类基于连续时间流匹配(Flow Matching)、在连续嵌入空间中运行的扩散模型。与现有的 DLMs 不同,ELF 在直至最终时间步之前主要停留在连续嵌入空间内,仅在最后通过一个共享权重的网络映射到离散 token。这种建模方式使得可以直接移植图像域扩散模型中的既定技术(例如无分类器引导,Classifier-Free Guidance, CFG)。实验表明,ELF 显著优于领先的离散和连续 DLMs,以更少的采样步骤实现了更优的生成质量。这些结果表明,ELF 为实现有效的连续 DLMs 提供了一条极具前景的途径。
一句话总结
作者提出了 Embedded Language Flows (ELF),这是一类基于连续时间流匹配 (Flow Matching) 在连续嵌入空间运行的扩散模型,仅在最后时间步映射到离散 tokens,促进了如无条件引导等图像域技术的应用,并以更优的生成质量和更少的采样步数显著优于领先的离散和连续扩散语言模型 (DLMs)。
核心贡献
- 该工作引入了 Embedded Language Flows (ELF),这是一类基于连续时间流匹配在连续嵌入空间运行的扩散模型。
- 该架构主要保持在连续嵌入空间内,直到最后时间步才通过共享权重网络映射到离散 tokens,以支持如无条件引导等技术。
- 实验表明,ELF 通过以更少的采样步数实现更优的生成质量,显著优于领先的离散和连续扩散语言模型。
引言
基于扩散和流的模型主导了图像和视频等领域的连续数据生成,但由于性能顾虑,语言建模已很大程度上转向离散方法。以往的连续扩散语言模型往往难以处理每步离散化损失,或需要单独的解码器将潜在表示映射回 tokens。作者引入了 Embedded Language Flows (ELF),利用连续时间流匹配主要在连续嵌入空间内运行。该设计将离散化延迟到最后时间步,无需显式解码器,并允许采用如无条件引导等图像域技术。实证结果显示,ELF 优于领先的离散和连续模型,同时需要更少的采样步数和显著更少的训练数据。
数据集
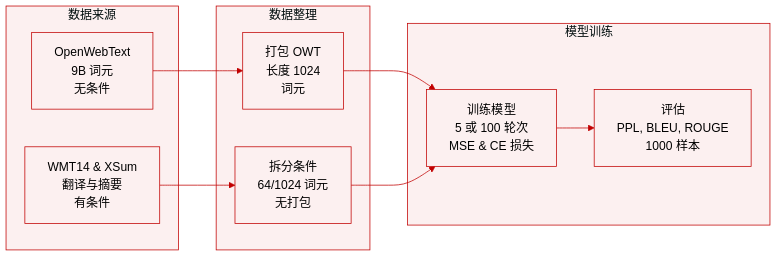
- 数据集构成与来源: 作者利用 OpenWebText 进行无条件生成任务,并依赖 WMT14 德译英和 XSum 进行条件机器翻译和摘要。
- 关键子集详情: OpenWebText 包含约 90 亿 tokens。WMT14 数据集包含 1.44 亿总目标 tokens,最大序列长度为 128。XSum 包含 600 万总目标 tokens,序列长度为 1088。
- 训练与使用: 无条件序列打包至长度 1024 并训练 5 个轮次。条件数据作为序列到序列任务处理,不打包,训练 100 个轮次。训练目标结合 80% 步数的 MSE 损失和剩余 20% 步数的 CE 损失。
- 处理策略: 条件任务强制特定的长度划分。机器翻译为条件和目标各分配 64 个 tokens。摘要使用 1024 个 tokens 作为条件,64 个作为目标。无条件生成的评估涉及创建 1,000 个样本以评估困惑度和熵。
方法
作者引入了 Embedded Language Flows (ELF),这是一种主要在连续嵌入空间执行去噪的连续扩散语言模型。该方法仅在最后一步将干净嵌入转换回离散 tokens,使模型能够利用连续扩散技术,同时保持离散输出。
参考展示从噪声到离散 tokens 轨迹的框架图:

该过程首先将离散 tokens s=[s1,…,sL] 映射到连续嵌入空间 x,通常使用如 T5 的预训练编码器。模型随后使用流匹配学习从噪声 ϵ 到数据 x 的流路径。噪声潜在变量由线性插值定义:zt=tx+(1−t)ϵ,其中 t∈[0,1]。ELF 不直接预测速度场,而是采用 x 预测参数化,其中网络输出对干净嵌入 xθ(zt,t) 的预测。
参考训练和采样流程的概述:
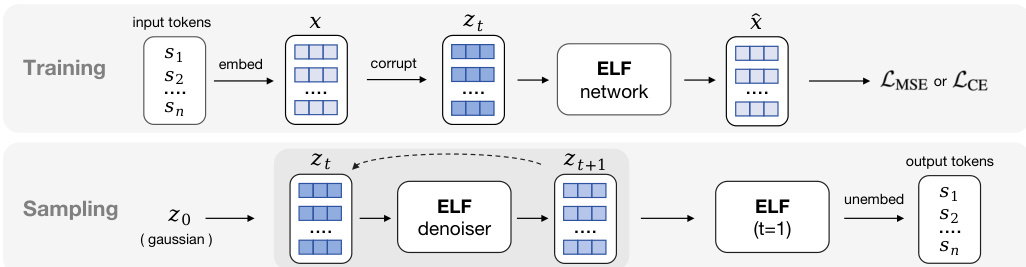
训练期间,模型最小化去噪分支中预测速度与目标速度之间的均方误差 (MSE)。对于最后解码步骤 (t=1),网络在“解码”模式下运行,通过去嵌入矩阵投影预测的嵌入,以计算与真实 tokens 的交叉熵损失。这允许单个共享权重网络处理中间去噪和最终离散化。
参考说明输入预处理的详细训练流程:
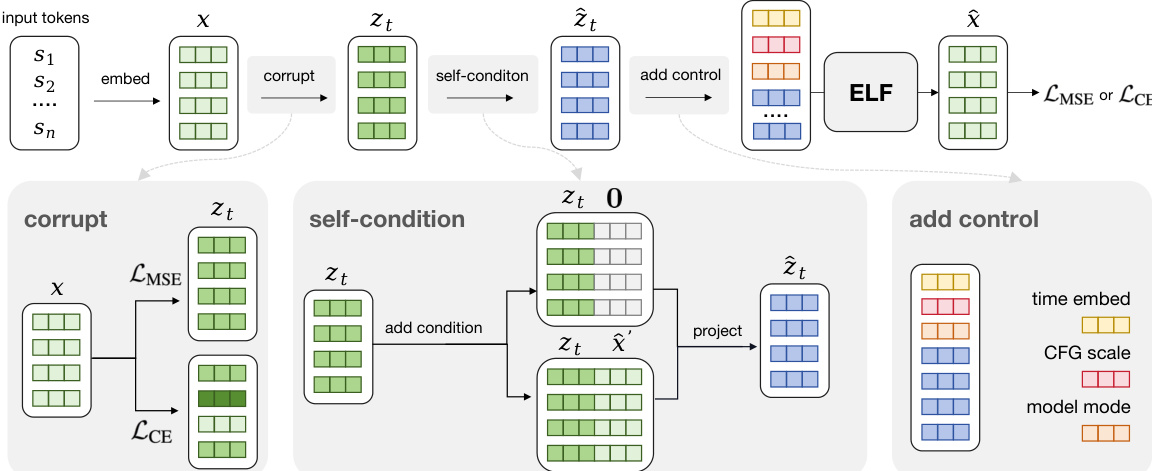
如详细训练图所示,输入嵌入在进入 ELF 网络之前经历三个关键预处理步骤。首先,“损坏”模块向干净嵌入添加噪声以创建 zt。其次,“自条件”模块将空向量或先前预测 x^′ 连接到噪声嵌入,然后将其投影回原始维度。最后,“添加控制”模块前置编码时间步、CFG 尺度和模型模式(去噪或解码)的控制 tokens。这种上下文条件策略避免了如 adaLN-Zero 等单独条件模块的参数开销。
在推理期间,ELF 通过求解流速度定义的常微分方程 (ODE) 迭代地将噪声样本转换为干净嵌入。从高斯噪声 z0 开始,模型在时间步 t∈[0,1] 上更新潜在状态。在最后一步 t=1,模型切换到解码模式,通过 argmax 操作将连续表示去嵌入为离散 tokens。作者还支持受 SDE 启发的采样器,在每一步注入少量噪声以模拟随机动力学。
实验
实验在无条件生成和条件任务上评估 ELF,对比离散和连续扩散语言模型。消融实验表明,预训练上下文嵌入、共享权重解码和随机采样优化了质量 - 多样性权衡,而模型扩展一致地提高了性能。系统级比较显示,ELF 在推理和数据效率方面优于基线,包括无需额外训练阶段的蒸馏变体。此外,ELF 在条件任务上优于自回归和扩散模型,生成的文本流畅且与输入上下文语义对齐。
作者将提出的模型与多种自回归和基于扩散的基线在机器翻译和摘要任务上进行比较。结果表明,该模型在所有评估指标上均取得优越性能,在翻译质量和摘要忠实度方面均优于竞争方法。尽管该模型的参数量与几个基线相当或更小,但仍保持了高性能。与所有列出的基线相比,该模型在 WMT14 德译英翻译上取得了最佳性能。它在 XSum 摘要任务的所有 ROUGE 指标上均获得最高分。该模型以与许多竞争架构相当或更小的参数量提供了顶级结果。
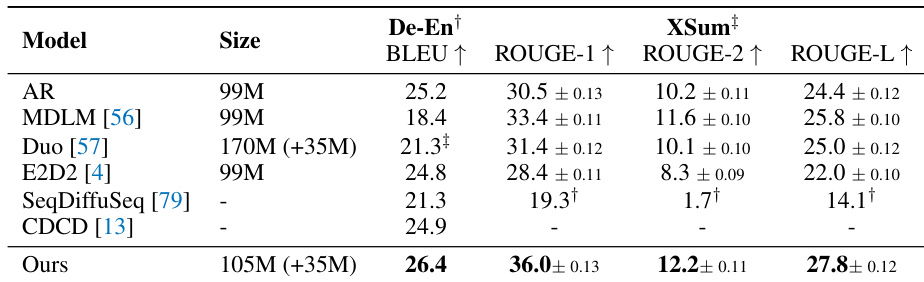
下表和文本比较了 ELF 与各种基线离散和连续扩散语言模型的训练效率,突出了数据使用的显著差异。虽然基线方法通常需要超过 5000 亿有效训练 tokens 且经常利用额外的蒸馏阶段,但 ELF 仅用约 450 亿 tokens 的更小训练预算就取得了结果。这表明提出的模型比先前方法具有显著更高的数据效率。ELF 使用约 450 亿有效训练 tokens,比基线模型所需的 5000 亿 tokens 少约一个数量级。基线方法通常结合蒸馏训练阶段,增加了其总 tokens 消耗,而 ELF 仅依赖基础训练。效率比率表明,基线训练预算比用于提出模型的预算大十倍以上。
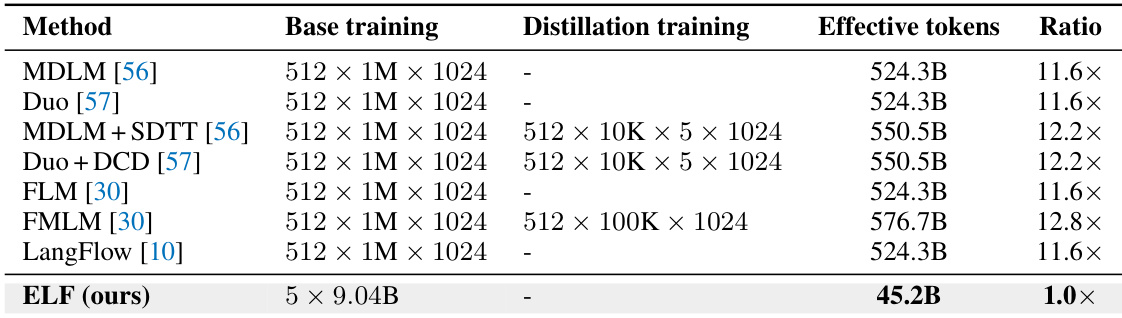
作者分析了无条件引导和采样策略对三个模型规模下生成困惑度和熵权衡的影响。结果表明,SDE 采样通过实现更低的困惑度始终优于 ODE 采样,而增加引导尺度通常会以降低多样性为代价减少困惑度。此外,扩大模型尺寸改善了整体质量 - 多样性前沿。增加无条件引导尺度会降低生成困惑度,但会降低熵。与 ODE 采样相比,SDE 采样始终实现更低的生成困惑度。更大的模型尺寸改善了生成困惑度 - 熵前沿。
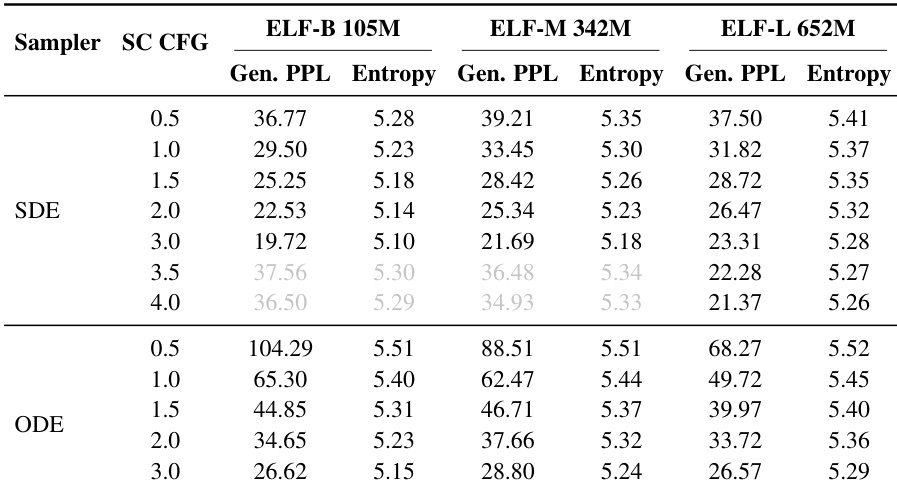
作者评估了三个模型规模 ELF-B、ELF-M 和 ELF-L,以分析不同参数量下的扩展行为。结果表明,增加模型尺寸一致地改善了生成困惑度 - 熵前沿,较大的模型在相似的多样性水平下实现了更好的质量。最大模型变体配置为 6.52 亿参数,而最小模型使用 1.05 亿。模型深度和隐藏层大小在三个变体中逐渐增加。随着模型尺寸增加,训练轮次略有减少,最大模型需要的轮次较少。

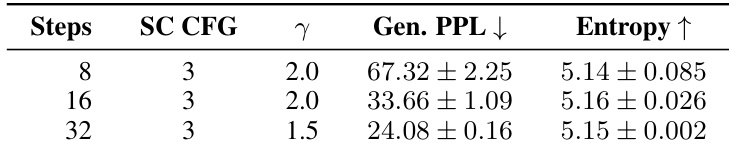
作者使用自条件 CFG 尺度为 3 的 SDE 采样评估采样步数对无条件生成质量的影响。结果表明,将步数从 8 增加到 32 显著降低了生成困惑度,证明了样本质量的改善。在此过程中,熵保持稳定,表明模型在采样预算变化的情况下仍保持一致的多样性。增加采样步数显著降低了生成困惑度。熵在不同步数预算下保持稳定。该实验比较了 8、16 和 32 步,并调整了噪声注入尺度。
作者将提出的模型与机器翻译和摘要任务上的自回归和扩散基线进行评估,以具有竞争力的参数量展示了优越性能。效率分析显示,该模型所需的训练 tokens 远少于通常依赖蒸馏的先前方法。对采样策略和模型扩展的进一步研究表明,随机微分方程采样和更大的架构在不损害多样性的情况下持续提高了生成质量。