Command Palette
Search for a command to run...
揭露策略内蒸馏的真相:其有益之处、有害之处及原因分析
揭露策略内蒸馏的真相:其有益之处、有害之处及原因分析
Mohammadreza Armandpour Fatih Ilhan David Harrison Ajay Jaiswal Duc N.M Hoang Farash Faghri Yizhe Zhang Minsik Cho Mehrdad Farajtabar
摘要
在线策略蒸馏(On-policy distillation)为推理模型的训练提供了密集的、逐 token 的监督信号;然而,目前尚不清楚在哪些条件下该信号有益,而在哪些条件下则有害。应当使用哪种教师模型?在自蒸馏(self-distillation)场景下,又应以何种特定的上下文作为监督信号?这种最佳选择是否随 token 的不同而变化?目前,回答这些问题通常需要耗费高昂的计算成本进行训练实验,且其聚合性能指标掩盖了单 token 层面的动态变化。为此,我们引入了一种免训练的(training-free)诊断框架,其粒度达到最高分辨率:即针对每个 token、每个问题以及每个教师模型进行分析。我们定义了一种理想的逐节点梯度(per-node gradient),该梯度表示能使学生模型成功概率最大化提升的参数更新方向。随后,我们开发了一种可扩展的目标 rollout 算法,用于高效估算该梯度,即使面对包含长链条中间思维过程的复杂场景亦能适用。梯度对齐得分(gradient alignment score)定义为理想梯度与任意给定蒸馏梯度之间的余弦相似度,用于量化特定配置在多大程度上近似于理想信号。在多种自蒸馏设置及外部教师模型的实验范围内,我们观察到:在不正确的 rollout(即生成错误结果的路径)上,蒸馏引导信号与理想信号的对齐程度显著高于在正确 rollout 上;在正确情况下,学生模型本身表现良好,而教师的信号往往趋于噪声化。此外,我们发现最优的蒸馏上下文取决于学生模型的能力与目标任务,且并不存在一种普遍有效的单一配置。这些发现表明,在蒸馏过程中应采用针对特定任务、特定 token 的诊断性分析。
一句话总结
作者介绍了一个无需训练的框架,用于推理模型中的同策略蒸馏,该框架推导出理想的每个节点梯度,并采用可扩展的针对性 rollout 算法对其进行估计,利用梯度对齐分数揭示蒸馏指导在错误的 rollout 上对齐更强,且最佳上下文取决于学生容量和任务,从而推动了针对每个任务和每个 token 的蒸馏诊断分析。
核心贡献
- 该论文介绍了一个在每个 token 分辨率下运行的无需训练的诊断框架,推导出理想的每个节点梯度,并开发了一种可扩展的针对性 rollout 算法以进行高效估计。定义了一个梯度对齐分数,用于量化特定蒸馏配置在多大程度上近似该理想信号。
- 在各种自蒸馏设置和外部教师模型上的实证分析表明,与正确的 rollout 相比,蒸馏指导在错误的 rollout 上与理想信号的对齐程度显著更高。研究结果进一步表明,最佳蒸馏上下文取决于学生模型的容量和目标任务,表明不存在单一普遍有效的配置。
- 该工作通过显示奖励和蒸馏目标通过梯度分解共享相同的局部结构,为蒸馏现象提供了机制性解释。这种统一使得能够在 token 粒度上进行直接离线比较,而无需额外的训练或模型。
引言
同策略蒸馏已成为推理模型的标准后训练技术,因为它提供了密集的每个 token 监督,补充了稀疏的强化学习奖励。尽管其实用性很强,但从业者仍面临教师选择和上下文设计方面的未决挑战,因为现有的评估依赖于昂贵的训练运行,其中聚合指标掩盖了 token 级动态。作者介绍了一个无需训练的诊断框架,以 finest 粒度评估教师指导质量。他们基于成功概率推导出理想的每个节点梯度,并开发了一种可扩展的针对性 rollout 算法以高效估计它,从而能够量化梯度对齐分数以识别有益配置,而无需执行额外训练。
方法
作者提出了一个框架,通过测量蒸馏梯度与从任务成功推导出的理想梯度之间的对齐来评估教师指导的质量。该方法解决了区分推理关键分歧与教师输出中的风格变化的挑战。整体过程涉及估计成功概率、计算教师梯度并测量它们之间的对齐。
请参阅框架图以了解三步计算的概述。
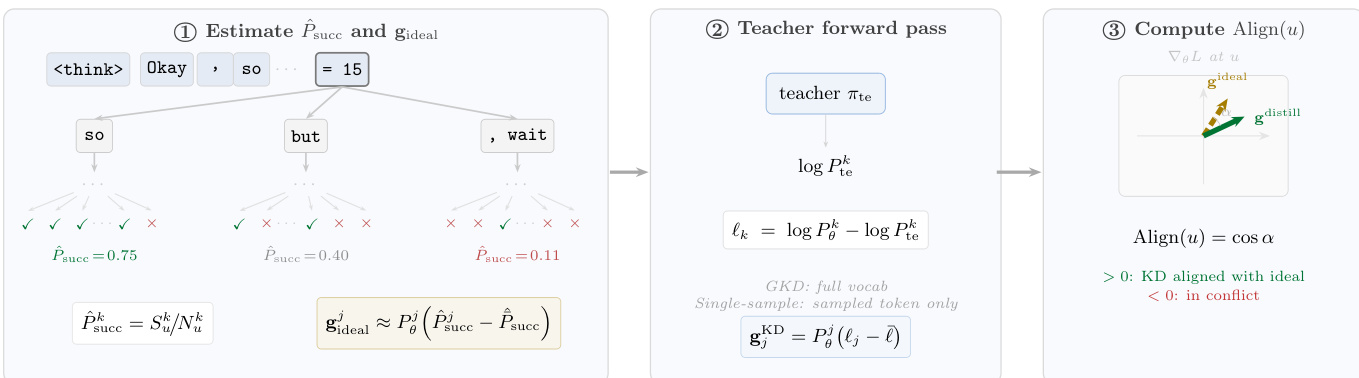
估计成功概率和理想梯度 该过程首先将生成分解为树结构。给定从学生策略 πθ 采样的 G 个轨迹,每个节点 u 代表一个 token 位置。通过观察在节点 u 选择特定 token k 后哪些 rollout 到达正确答案,作者估计经验成功概率 P^succk。这使得他们能够定义一个理想梯度 gideal,指向最大化正确结果概率的 token。
教师前向传播和蒸馏梯度 接下来,该方法计算蒸馏算法产生的梯度。对于广义知识蒸馏 (GKD),损失最小化学生和教师分布之间的前向 KL 散度。节点 u 处 token j 的所得梯度形式为:
gjKD=Pθj(ℓj−ℓˉ)其中 ℓk=logPθk−logPtek 是每个 token 的对数比率。单样本估计器和 MiniLLM 适用类似形式,允许统一比较。
计算对齐分数 最后,框架计算对齐分数 Align(u),作为理想梯度和蒸馏梯度之间的余弦相似度:
Align(u)=cos(guideal,guD)正分数表示教师推动学生走向成功的 token,而负分数意味着指导是有害的。
可扩展性和 rollout 生成 为了高效计算这些估计,作者采用针对性 rollout 而非穷举采样。他们将生成分为指数增长的深度窗口,并优先处理具有高 GKD 梯度幅度或大概率差异的 token。此分析所需的学生 rollout 使用特定的提示策略生成。这些包括带有正确响应的标准演示、包含正确和错误示例的提示以阻止模仿错误,以及总结的演示以压缩推理路径。

此设置确保生成树富含足够的样本,以可靠地估计 P^succk,即使对于较少见的 token,从而使对齐分析能够扩展到长推理轨迹。
实验
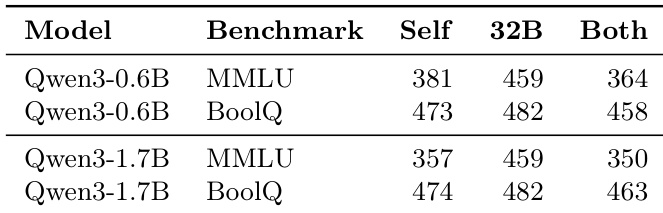
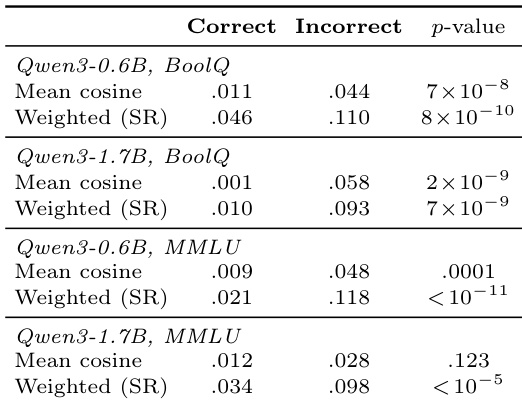
实验评估了 Qwen3 学生模型与各种教师配置在包括 BoolQ、MMLU 和 AIME 的推理基准上的梯度对齐。研究发现,蒸馏信号在错误的推理路径上始终更有效,教师在错误路径上提供更强的指导以引导学生远离失败。最佳教师选择严重取决于学生容量和任务难度,因为自蒸馏更利于较小模型,而外部教师更利于较大模型。这些结果表明不存在通用蒸馏配方,因为有效的上下文设计必须与学生学习理解所提供信号的能力相一致。
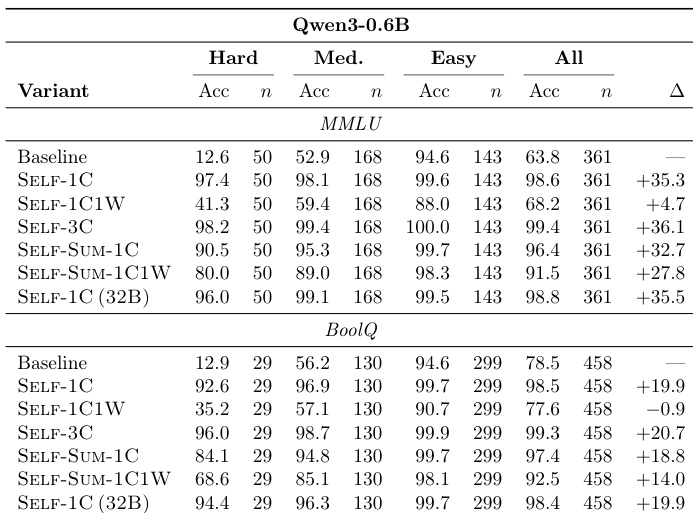
该表格比较了学生模型不同上下文配置的有效性,包括自生成演示、来自更大模型的总结,以及结合正确和错误示例。结果显示,仅使用正确演示通常比包含错误示例产生更好的结果。此外,来自更大模型的总结往往能提高性能,特别是对于 MMLU 基准上的较大学生模型。包含错误演示始终导致比仅正确上下文更低的性能。由较大模型生成的总结提供性能提升,特别是对于 MMLU 上的 1.7B 学生。对于两种学生规模,在 BoolQ 基准上,较大模型总结的优势不太显著。
分析显示,在各种模型规模和数据集上,梯度对齐在错误的推理路径上始终比正确路径更强。这表明当教师引导学生远离失败轨迹时,教师的蒸馏信号最有益,而正确路径已经与最优方向具有足够的对齐。值得注意的是,加权余弦指标以高统计显著性确认了这一趋势,即使在平均余弦差异不显著的设置中也是如此。在所有设置中,错误路径表现出比正确路径显著更高的梯度对齐。加权余弦指标显示,即使平均余弦差距可忽略不计,错误路径优势也具有强统计显著性。教师的梯度信号在失败轨迹上比在成功轨迹上更接近奖励方向。
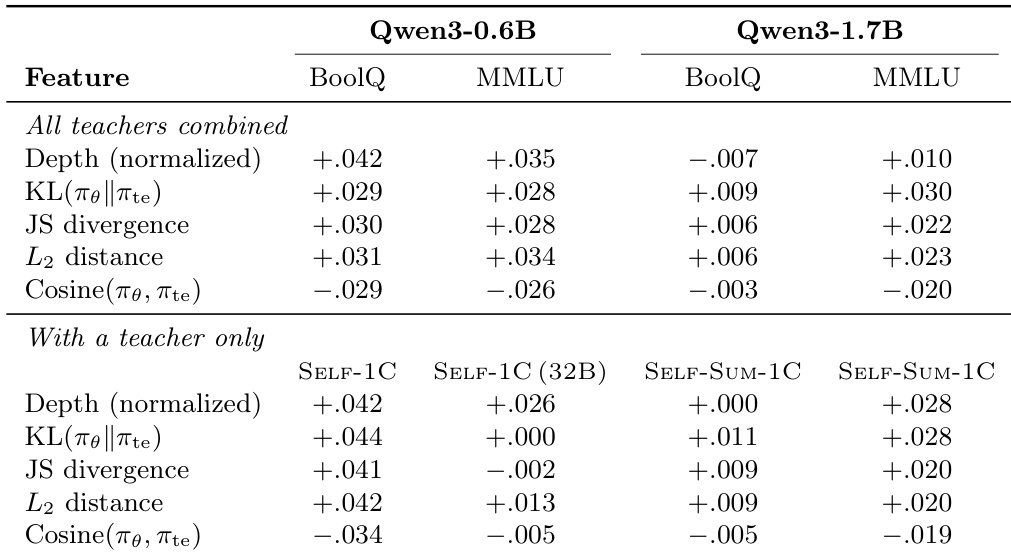
该研究调查了教师 - 学生分布差异与梯度对齐之间的关系,跨越不同的模型规模。研究发现,教师和学生分布之间的更大差异始终与更高的梯度对齐相关,而高相似性预测较低的对齐。此外,推理深度与对齐之间的正趋势在较小模型中比在较大模型中更明显。包括 KL 和 L2 距离在内的散度指标在所有设置中始终与梯度对齐呈正相关。由余弦相似度测量的分布相似性与对齐呈负相关,意味着当模型一致时信号用处较少。归一化深度与对齐之间的相关性对于较小的学生模型比对于较大模型更强。
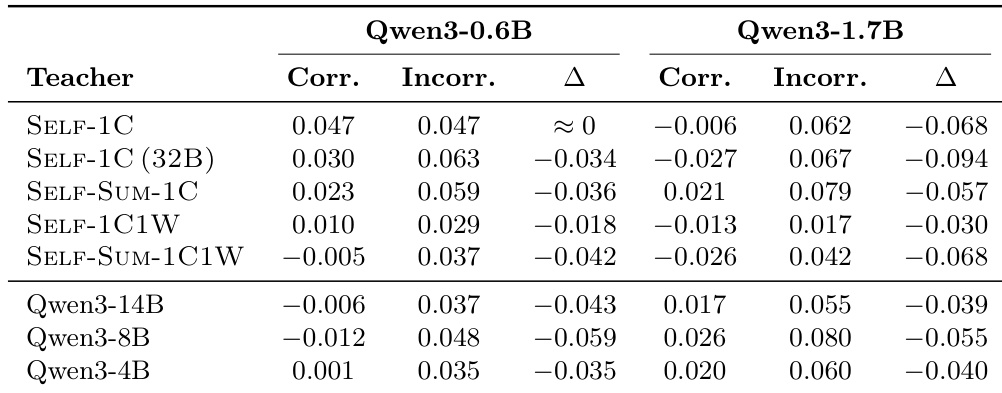
该表格比较了各种教师配置在两个学生模型规模上的梯度对齐指标。结果表明,自蒸馏方法通常为较小的 0.6B 学生产生更高的对齐,而外部教师对较大的 1.7B 学生更有效。此外,在大多数设置中,对齐在错误的推理路径上始终比在正确的路径上更强。自蒸馏方法为 0.6B 学生产生更高的对齐,而外部教师为 1.7B 学生表现更好。对于几乎所有教师配置,梯度对齐在错误路径上始终比在正确路径上更高。包含错误演示的配置通常显示比仅使用正确演示的配置更低的对齐分数。
作者评估了不同上下文演示策略对 Qwen3-0.6B 模型在 MMLU 和 BoolQ 基准上性能的影响。结果表明,提供正确解决方案作为上下文会导致准确率大幅提高,而将错误示例与正确示例一起包含会显著降低性能。提供正确解决方案作为上下文在所有难度级别上导致显著的准确率改进。与仅正确变体相比,始终将错误演示与正确示例一起包含会降低性能。总结的正确演示和来自较大模型的示例产生与原始正确演示相当的性能。
该研究评估了不同规模的学生 - 教师模型的上下文配置和梯度对齐动态。实验表明,提供正确演示或来自更大模型的总结可增强性能,而包含错误示例始终降低准确率。此外,梯度对齐在错误的推理路径上显著更强,并与更大的分布散度相关,表明教师信号在纠正错误时最有用,而自蒸馏比外部教师更利于较小模型。