Command Palette
Search for a command to run...
TMAS:通过多智能体协同扩展测试时计算
TMAS:通过多智能体协同扩展测试时计算
George Wu Nan Jing Qing Yi Chuan Hao Ming Yang Feng Chang Yuan Wei Jian Yang Ran Tao Bryan Dai
摘要
测试时扩展(Test-time scaling)已成为通过推理阶段分配额外计算资源以提升大语言模型推理能力的一种有效范式。近期的结构化方法通过组织跨多条轨迹、多轮细化以及基于验证的反馈推理过程,进一步推动了该范式的发展。然而,现有的结构化测试时扩展方法要么平行推理轨迹间的协同较弱,要么依赖于包含噪声的历史信息,且缺乏对信息保留与复用策略的显式决策,从而限制了其在探索(exploration)与利用(exploitation)之间进行平衡的能力。在本工作中,我们提出了 TMAS,一种通过多 Agent 协同实现测试时计算扩展的框架。TMAS 将推理过程组织为多个专用 Agent 之间的协作过程,实现了跨 Agent、跨轨迹以及细化迭代的结构化信息流动。为支持有效的跨轨迹协作,TMAS 引入了分层记忆机制:经验库(experience bank)用于复用低层次的可靠中间结论和本地反馈,而指南库(guideline bank)则记录先前探索过的高级策略,以引导后续 rollout 避免冗余的推理模式。此外,我们针对 TMAS 设计了一种混合奖励强化学习方案,该方案共同维护基础推理能力、提升经验利用率,并鼓励探索超出先前尝试过的解决方案策略的新路径。在具有挑战性的推理基准测试上进行的广泛实验表明,TMAS 实现了比现有测试时扩展基线更强的迭代扩展效果,而混合奖励训练进一步提升了各迭代轮次中扩展的有效性和稳定性。代码和数据已开源,详见 https://github.com/george-QF/TMAS-code。
一句话总结
本文提出 TMAS,一种多 Agent 协同框架。该框架通过在推理轨迹中协调专用 Agent 来扩展大语言模型推理的测试时计算,并采用分层经验库与指导库,显式保留可靠的中间结论与高层策略,从而在迭代优化过程中平衡探索与利用。
核心贡献
- 本文提出 TMAS,一种通过多 Agent 协同扩展测试时计算的框架,该框架显式地组织了 Agent、推理轨迹与迭代之间的信息流。该框架引入分层记忆机制,利用经验库复用可靠的底层信号,并利用指导库记录用于平衡利用与探索的高层策略。
- 一种定制化的混合奖励强化学习方案优化了三个互补目标:保留基础推理能力、提升经验利用率,以及鼓励探索超出以往尝试的策略。该训练设计使模型能够有效利用协同记忆结构,同时在迭代优化过程中保持充分的探索。
- 在具有挑战性的推理基准上进行的广泛实验表明,与现有的测试时扩展基线相比,TMAS 实现了更强的迭代扩展性能。结果进一步表明,混合奖励方案提升了各优化轮次中的扩展效果与稳定性。
引言
测试时扩展通过在推理阶段分配额外计算来提升大语言模型的推理能力,这一能力已成为解决复杂分析任务的关键。尽管近期取得进展,但现有的结构化方法要么对并行推理轨迹的协调较弱,要么依赖未经过滤的历史数据,这无法有效平衡探索与利用,且常会传播噪声信号。本文利用名为 TMAS 的多 Agent 协同框架,将推理重构为一种协同的迭代过程。研究者引入分层记忆库,分别保留可靠的中间结论与高层探索策略,同时采用自定义的混合奖励强化学习方案训练模型,使其能够高效复用共享经验并探索多样化的求解路径。
数据集
- 数据集构成与来源: 本文通过结合开源强化学习数据集(DAPO 与 Skywork-OR1)以及两个数学推理基准(IMO-AnswerBench 与 HLE-Math-100)构建冷启动训练池。
- 子集细节与过滤: 训练数据被组织为三个特定任务子集:1.6K 实例用于经验利用,0.6K 用于新策略探索,2.2K 用于标准正确性奖励。在评估阶段,使用 Qwen3-4B-Thinking-2507 对原始包含 400 道题的 IMO-AnswerBench 进行过滤,仅保留在八次独立推理运行中正确求解次数少于两次的 50 道题目。HLE-Math-100 数据集直接采用 RSE 发布版本,未作修改。
- 训练使用与上下文处理: 为匹配混合强化学习目标,研究团队使用 DeepSeek-V3.2 作为教师模型,对每道题目模拟迭代推理过程。他们生成多轮 rollout 历史,并将这些轨迹提炼为历史上下文、经验库与指导库。该提炼过程生成上下文感知的训练样本,用于在强化学习微调前初始化模型。
- 评估与元数据设置: 在评估过程中,DeepSeek-V3.2 充当 LLM-as-Judge,用于验证生成答案与参考答案之间的数学等价性。针对每个答案运行四次独立评判,应用严格等价规则(忽略格式差异,仅关注最终结果),并通过平均所有评判运行的成功率来计算最终的 Pass@1 准确率。
方法
TMAS 框架通过迭代推理协调多 Agent 协作以扩展测试时计算,将并行探索与顺序利用相融合。整体系统以迭代流水线形式运行,在每次迭代中并行生成多条求解轨迹,随后进行验证、总结,并用于更新两个互补的记忆库。该过程实现了跨迭代的协同优化与非冗余探索。
在每次迭代中,系统以问题 Q 为起点,并利用两个记忆库:经验库 Et−1 存储低层、特定于轨迹的推理信号(如已验证的中间结论与避错启发式规则),指导库 Gt−1 保存来自先前探索的高层求解策略与结构洞察。这些记忆库对求解生成过程施加条件约束,在利用已验证知识与探索新路径之间取得平衡。
推理过程的核心由五个专用 Agent 驱动。求解 Agent Asol 并行生成 N 个候选求解轨迹 {ct,i}i=1N。该生成过程遵循 ϵ-贪婪策略:以 1−ϵ 的概率利用先前的 rollout 与经验,从 Asol(Q,Rt−1,Et−1) 中采样;以 ϵ 的概率探索新方向,从 Asol(Q,Gt−1) 中采样,并受指导库中高层策略的引导。该机制直接协调了探索与利用。
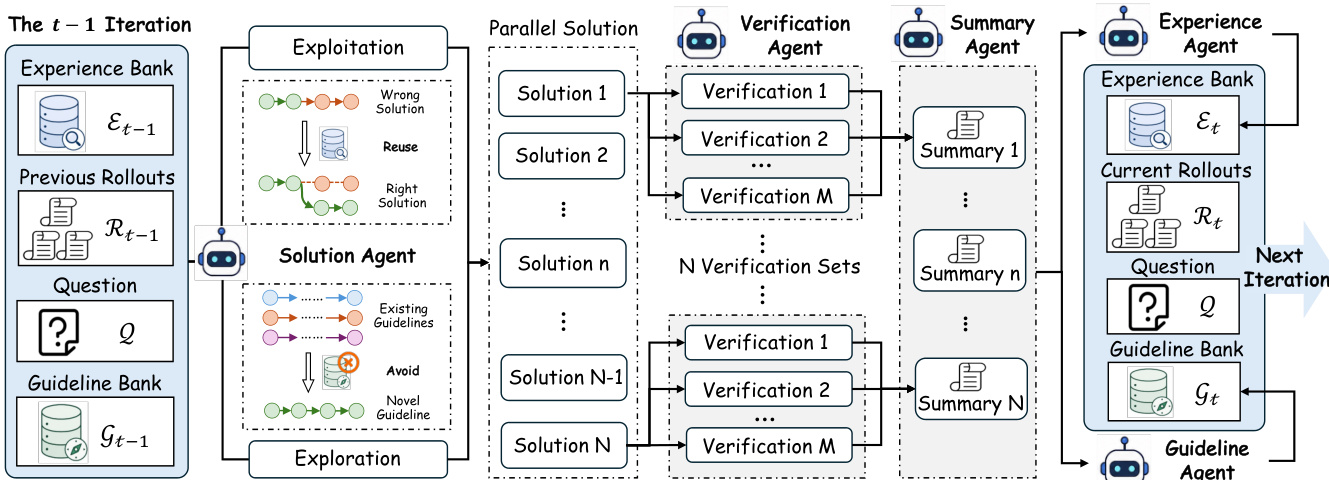
如图所示,每个候选答案 ct,i 随后由 M 个验证 Agent 独立验证,生成验证集 Vt,i。验证输出提供每步的分析反馈与评分。一个总结 Agent 将这些结果聚合为简洁的 rollout 级摘要 st,i,突出已验证的推理过程并识别逻辑缺陷。所有 rollouts 的集合 Rt={(ct,i,st,i)}i=1N 作为记忆更新阶段的输入。

两个并行的记忆更新 Agent 在 Rt 上运行。经验 Agent Aexp 提取可复用的底层模式(如共享的中间步骤与常见错误陷阱),以更新经验库 Et。指导 Agent Aguide 抽象 rollout 过程中尝试的高层求解方法,以更新指导库 Gt。这种分层记忆结构充当通信基础,使专用 Agent 能够共享局部证据并传播全局策略,从而将独立的并行轨迹转化为协同的迭代推理过程。更新后的记忆库将延续至下一次迭代,约束求解 Agent 的后续动作。
实验
在具有挑战性的数学推理基准上,与成熟的测试时扩展基线方法相比,主要实验验证了 TMAS 在维持迭代性能增益方面的优越能力,且未出现竞争方法中的性能停滞现象。组件消融实验与敏感性分析进一步验证了战略指导与历史经验的互补作用,同时证实适度的探索与验证预算能在发现与利用之间实现最优平衡。补充研究表明,混合奖励强化学习稳定了早期进展并缓解了后期性能退化,但也揭示出生成与验证之间的能力共享边界最终限制了在最难题型上的扩展效果。
本文在两个推理基准上评估 TMAS,证明其相比基线方法实现了更强的迭代扩展能力。结果显示,TMAS 随着优化轮次的增加持续改进,在后期迭代中优于其他方法。提出的混合奖励强化学习显著提升了性能,尤其在后期阶段,并缩小了不同规模基础模型之间的性能差距。TMAS 展现出卓越的迭代扩展能力,随着优化轮次增加持续改进,并在后期达到最佳性能。混合奖励强化学习训练大幅增强了 TMAS 的扩展能力,带来持续的性能提升并缩小了不同模型尺寸间的差距。经验模块与指导模块的协同至关重要,移除任一项均会导致性能下降,其中指导模块助力早期进展,经验模块支持后期优化。

本文在两个推理基准上评估 TMAS,将其性能与多种基线方法对比,并分析其迭代扩展行为。结果表明,TMAS 随着优化轮次增加持续改进,在使用混合奖励强化学习训练方法时尤其能达到最佳后期性能。消融研究显示,指导模块与经验模块均对迭代增益有独特贡献,完整系统表现优于缺失任一组件的变体。与基线方法相比,TMAS 展现出更强的迭代扩展能力,并随优化轮次增加持续改进。混合奖励强化学习显著增强了迭代扩展效果,带来更优性能并缩小了大小模型间的差距。TMAS 中的指导与经验模块提供互补收益,各自在不同优化阶段对性能提升做出独特贡献。

本文在两个推理基准上评估 TMAS,证明其相比基线方法具有更优的迭代扩展能力。结果显示,TMAS 随着优化轮次增加持续改进,并取得最佳后期性能。提出的混合奖励强化学习显著增强了迭代扩展效果,尤其通过提升小模型性能并缓解后期迭代中的性能退化来实现。与基线相比,TMAS 展现出更强的迭代扩展能力,随优化轮次增加持续改进并达到最佳后期性能。混合奖励强化学习大幅放大了迭代扩展效果,在所有阶段提升性能并缓解后期退化。混合强化学习的整合缩小了大小模型间的性能差距,使小模型能够通过更高效的迭代测试时计算逼近大模型性能。

本文在两个推理基准上评估 TMAS,证明其相比基线方法实现了更优的迭代扩展效果。结果显示,TMAS 随着优化轮次增加持续改进,在后期迭代中优于其他方法。混合奖励强化学习的整合显著提升了性能,尤其在后期迭代中,并缩小了大小基础模型间的性能差距。TMAS 展现出更强的迭代扩展能力,在其他方法陷入停滞时仍能随优化轮次增加持续改进。混合奖励强化学习增强了 TMAS 性能,尤其在后期迭代中,并缩小了大小模型间的差距。该模型在迭代过程中保持稳定的增益,表明其有效利用了测试时计算。

本文在两个推理基准上评估 TMAS,证明其相比基线方法实现了更优的性能,尤其在后期迭代中。结果显示,TMAS 保持了强劲的迭代扩展能力,性能随优化轮次增加持续改进,而其他方法则出现停滞或退化。混合奖励强化学习的整合显著增强了模型在多次迭代中维持改进的能力。本文还进行了消融实验,揭示经验模块与指导模块均对系统有效性有独特贡献,两者结合使用效果最佳。与基线相比,TMAS 展现出更强的迭代扩展能力,在各优化轮次中持续改进性能。混合奖励强化学习显著增强了迭代扩展效果,带来持续的性能增益并缓解后期退化。TMAS 中的经验与指导模块提供互补收益,两者结合使用取得最佳整体性能。
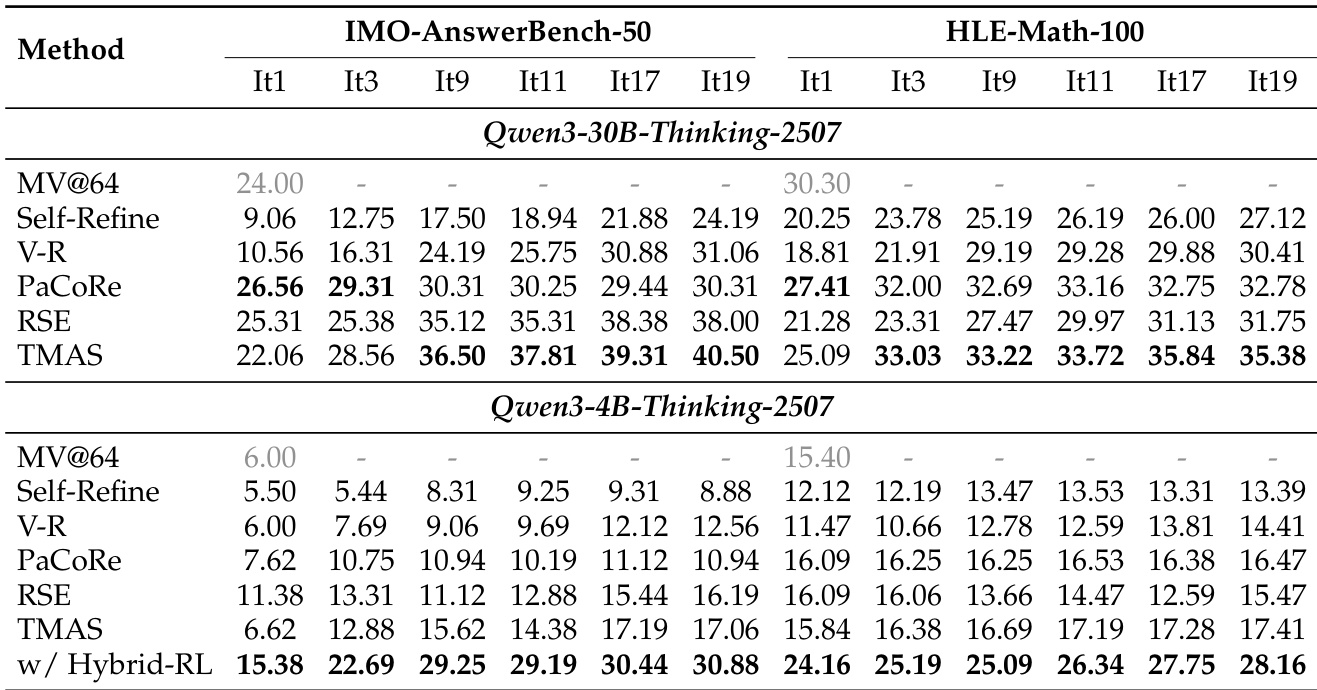
在两个推理基准上的评估验证了 TMAS 相比基线方法的卓越迭代扩展能力,证明其在多轮优化中持续获得性能增益,且未出现竞争方法中的性能停滞现象。混合奖励强化学习的整合显著放大了这些持续改进,同时有效缩小了大小基础模型间的性能差距。消融实验进一步证实了指导模块与经验模块之间不可或缺的协同作用,表明它们的互补贡献推动了最佳的早期引导与后期优化。综合来看,这些发现确立了 TMAS 作为一个稳健框架的地位,该框架高效利用测试时计算,实现了可扩展且持续的推理能力改进。