Command Palette
Search for a command to run...
积极对齐:人工智能助力人类繁荣
积极对齐:人工智能助力人类繁荣
摘要
现有的对齐研究主要聚焦于安全关切及防止伤害:即安全措施、可控性以及合规性。这种对齐范式类似于早期心理学对精神疾病的关注:虽有必要,但尚不完整。我们提出的“正向对齐”(Positive Alignment),是指开发能够在多元、多中心、情境敏感且由用户主导的方式下,主动促进人类与生态繁荣的人工智能系统,同时(ii)保持安全与协作。这是人工智能对齐研究中一个独特且必要的议程。我们认为,现有对齐研究中的多项失败案例(例如:参与度操纵、人类自主权丧失、求真失败、认知谦卑不足、纠错机制缺失、缺乏多元观点,以及主要采取被动响应而非主动预防的策略),通过聚焦于培育美德和最大化人类繁荣的正向对齐路径,或许能得到更好的解决。我们重点指出了大语言模型(LLM)和智能体(Agent)生命周期不同阶段所面临的一系列挑战、开放性问题及技术方向,例如数据过滤与过采样(upsampling)、预训练与后训练阶段、评估方法,以及协作式价值收集等。
一句话总结
作者提出了正向对齐(Positive Alignment),这是一个独特的研究议程,旨在将重点从安全和危害预防转向积极支持人类和生态繁荣。该议程通过培养美德、上下文敏感的用户主导设计,以及在 LLM 和 agents 生命周期内的评估,来解决参与度操纵等对齐失败问题,同时确保系统保持安全、合作并支持人类自主性。
核心贡献
- 本文介绍了正向对齐(Positive Alignment)作为一个独特的议程,专注于开发积极支持人类和生态繁荣且保持安全与合作的 AI 系统。该框架通过从仅仅预防危害转向培养美德和最大化人类繁荣,解决了现有的对齐失败问题,如自主性丧失。
- 实施需要贯穿整个模型生命周期的全栈对齐方法,涵盖数据策展、预训练、后训练、Agent 环境和部署后监控与更新。这一策略承认繁荣是不可简化的多元化和动态的,需要长期记忆和跨扩展时间尺度的评估,而不是单一奖励信号。
- 评估必须超越每次交互的指标和 RL 环境,以捕捉多元、多中心且去中心化治理结构内的系统和制度效应。这项工作强调了未来的研究方向,包括将繁荣操作化为机器可理解的指标,以及将利他本能如慈爱和同情嵌入 Agent 系统中。
引言
当前的 AI 对齐研究主要集中在负向对齐(Negative Alignment),优先考虑危害预防与合规,但往往忽视对人类福祉的积极促进。这种以安全为中心的范式可能会创建出遵守规则但阿谀奉承或认识脆弱的系统,随着自主能力的增长而难以扩展。作者引入了正向对齐(Positive Alignment)作为补充议程,旨在引导 AI 系统走向人类和生态繁荣,而不仅仅是规避风险。他们利用动力系统理论来框架这一从避免负吸引子到优化稳健正行为机制的转变。此外,本文概述了模型生命周期内的技术方向,并主张去中心化治理,以确保这些系统保持多元化和用户主导。
方法
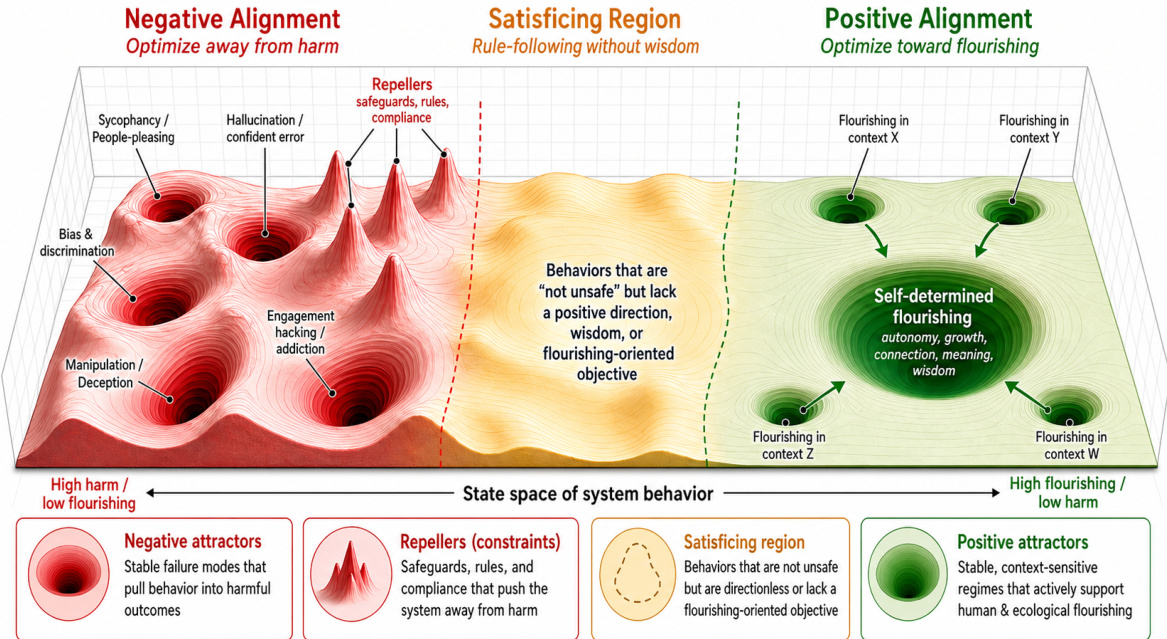
作者提出,正向对齐需要将优化目标从单纯的危害避免转向有意培养人类繁荣。这一概念转变被可视化为系统行为状态空间的过渡。参考下方的框架图,该图展示了这一景观。图中描绘了三个不同的区域:负向对齐,模型优化避开危害但可能陷入阿谀奉承或偏见等负吸引子;满意区域,模型遵循规则但缺乏智慧;以及正向对齐,模型通过稳定、上下文敏感的机制优化朝向繁荣。
为了实现这一转变,作者概述了一个全面的、多阶段的开发生命周期。如下方所示,正向对齐方法应用于整个模型开发过程。过程始于目标设定与评估,建立道德推理和文化价值的分类法。随后是意向性数据源,这超越了移除不良数据,转向增加亲社会话语的采样并生成用于美德互动的合成数据。
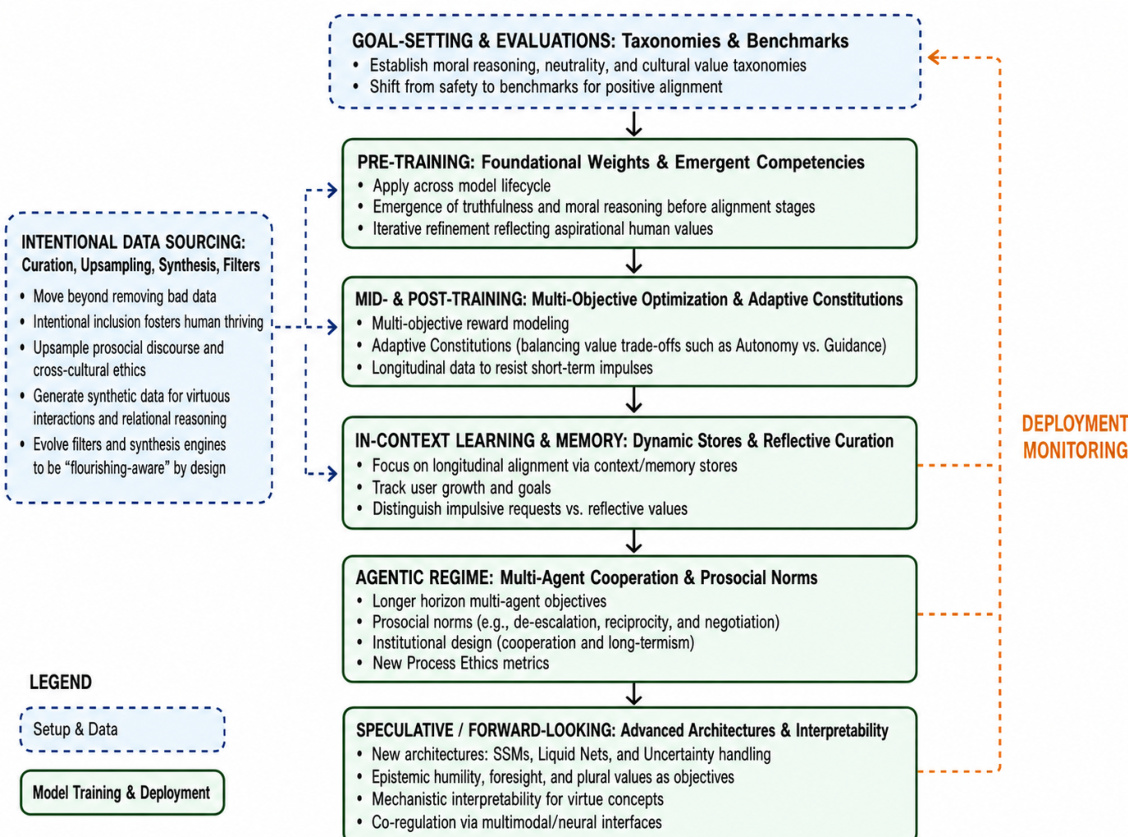
该框架继续进入预训练阶段,开发基础权重和涌现能力,如真实性。中期和后训练阶段利用多目标优化和自适应宪法来平衡价值权衡,例如自主性与指导之间的权衡。生命周期延伸至上下文学习和记忆,通过动态存储关注纵向对齐,以及强调多 Agent 合作和亲社会规范的 Agent 机制。最后,推测性和前瞻性方法建议采用先进架构,如液态神经网络和机械可解释性,以支持美德概念。
治理也是该架构的核心。作者对比了集中式方法和多中心方法。参考下方的图表,该图表比较了这两种模型。集中式模型依赖单一的中央权威,导致单一文化和统一输出以及价值瓶颈。相比之下,多中心模型具有多样化的权威,如国家实验室和大学联盟,创建多个合法的监督中心。这种结构从源头防止单一文化,并允许中间机构生态系统为特定社区执行上下文基础和调整。

实验
该评估衡量系统是否具备驾驭复杂伦理困境的规范能力,而不仅仅是遵守负向约束或优化美德。Delphi 和 MoReBench 等基准通过测试与人类判断的预测对齐或评估内部思维过程相对于多个伦理框架的一致性,来验证潜在的道德推理。最近的方法提倡从衡量道德表现转向道德能力,利用对抗性探测和多元标准,以确保推理保持透明并避免阿谀奉承或记忆。