Command Palette
Search for a command to run...
LLaVA-UHD v4:是什么构成了多模态大语言模型中高效的视觉编码?
LLaVA-UHD v4:是什么构成了多模态大语言模型中高效的视觉编码?
Kechen Fang Yihua Qin Chongyi Wang Wenshuo Ma Tianyu Yu Yuan Yao
摘要
视觉编码构成了多模态大语言模型(MLLMs)中的一大计算瓶颈,尤其是在处理高分辨率图像输入时。主流做法通常采用全局编码,随后进行基于 ViT 的压缩。全局编码会产生海量的 token 序列,而基于 ViT 的后置压缩则需在任何 token 缩减发生之前,承担 ViT 完整的二次方注意力计算成本。在本研究中,我们从编码策略和视觉 token 压缩两个维度重新审视了这一惯例。首先,受控实验表明,基于分块(slice-based)的编码在各项基准测试中均优于全局编码,这表明通过分块视图保留局部细节,对于细粒度感知而言,比应用全局注意力更为有益。其次,我们引入了基于 ViT 内部的早期压缩(intra-ViT early compression),即在浅层 ViT 层减少 token 数量,从而在保持下游性能的同时,大幅降低视觉编码所需的浮点运算次数(FLOPs)。通过将基于 ViT 内部的压缩整合到基于分块的编码框架中,我们提出了 LLaVA-UHD v4。这是一种针对高分辨率输入设计的高效且计算量可控的视觉编码方案。在涵盖文档理解、OCR(光学字符识别)和通用 VQA 的多样化基准测试中,LLaVA-UHD v4 在匹配甚至超越基线性能的同时,将视觉编码的 FLOPs 降低了 55.8%。
一句话总结
作者提出了 LLaVA-UHD v4,一种专为高分辨率输入设计的多模态大语言模型高效且计算可控的视觉编码方案。该方案集成了基于切片编码与 ViT 内部早期压缩,将视觉编码 FLOPs 降低 55.8%,同时在文档理解、OCR 和通用 VQA 基准测试中匹配或超越基线性能。
核心贡献
- 受控实验表明,基于切片编码通过切片视图保留局部细节,在基准测试中优于全局编码。这一发现表明,对于细粒度感知,切片视图比应用全局注意力更有利。
- 论文引入了一种新颖的参数重用 ViT 内部早期压缩模块,减少了浅层 ViT 层的 tokens。该技术大幅降低了视觉编码 FLOPs,同时保持下游性能。
- 论文提出了 LLaVA-UHD v4,一种将 ViT 内部压缩集成到基于切片框架中的高效视觉编码方案。在文档理解、OCR 和通用 VQA 基准测试上的实验显示,视觉编码 FLOPs 减少了 55.8%,同时匹配或超越基线性能。
引言
多模态大语言模型越来越依赖高分辨率输入进行细粒度感知,然而标准的全局编码范式随着图像面积增长产生了二次计算瓶颈。现有的效率解决方案通常在视觉编码器完成繁重计算后应用 token 压缩,而尝试在内部压缩 tokens 往往会破坏预训练的视觉表示。作者挑战了全局编码惯例,证明了基于切片的策略在不产生二次开销的情况下提供了更优越的细节保留。此外,他们引入了一种参数重用的早期压缩器,插入到视觉编码器的浅层中,利用相邻预训练权重初始化以保持表示稳定性。该方法赋能 LLaVA-UHD v4,使其能够在编码器内部进行激进的 token 减少,从而实现显著加速,同时保持竞争性准确率。
方法
作者提出了 LLaVA-UHD v4,一种旨在解决多模态大语言模型中高分辨率输入相关计算瓶颈的视觉编码方案。该架构从根本上从主流的全局编码范式转变为基于切片的方法,结合 ViT 内部早期压缩。
如下图所示:
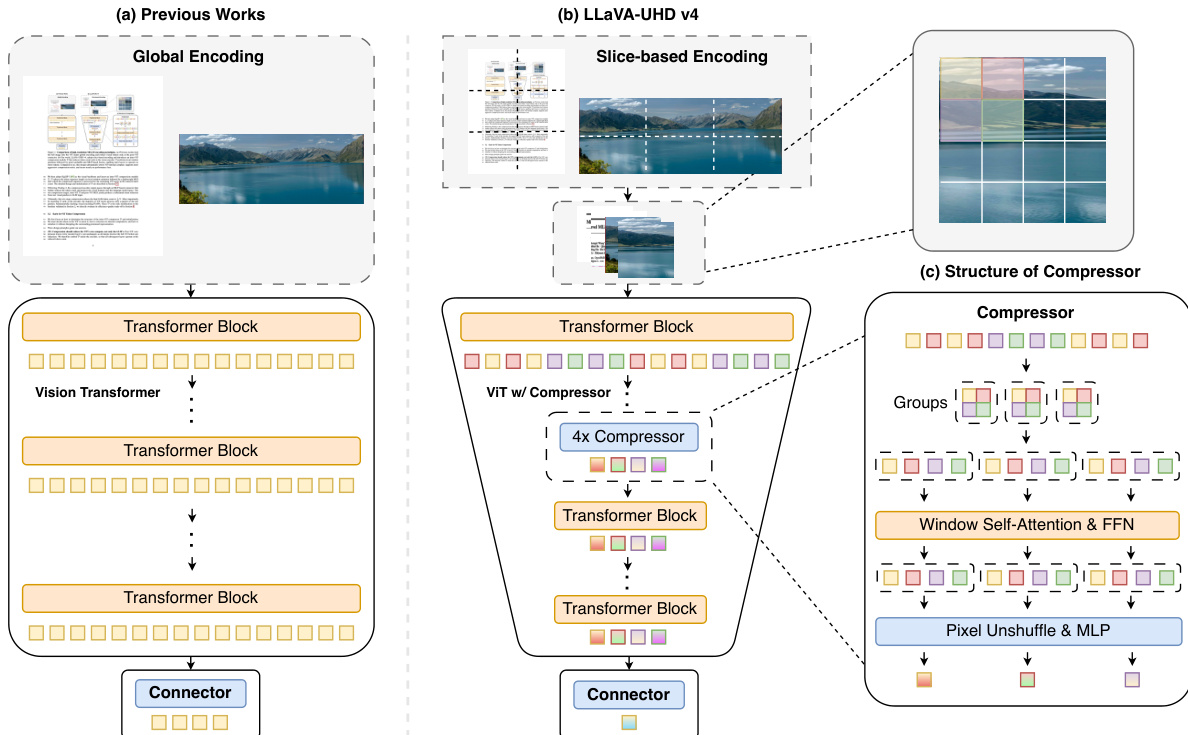
该框架首先将输入图像分解为低分辨率缩略图和由宽高比感知策略选择的一组高分辨率切片。与之前在全局处理整个图像后再进行 token 减少的工作不同,LLaVA-UHD v4 沿序列维度重新缩放并连接这些视图。这使得 Vision Transformer (ViT) 能够在单次前向传播中处理它们,同时保留每个视图的注意力局部性。
一个关键创新是集成了 ViT 内部早期压缩模块,记为 D。该模块直接插入 ViT 主干网络,具体在层 k=6 之后,以便在更深层处理数据之前减少 token 序列长度。这一设计选择遵循压缩应减少 ViT 自身计算量而非仅减少下游 LLM 负载的原则。通过早期减少 token 数量,大多数 ViT 层在显著更小的序列上运行,大幅削减视觉编码 FLOPs。
压缩器 D 的内部结构由两个主要阶段组成。首先,将窗口注意力算子 WinAttn2×2 应用于输入 token 序列 Xk。该注意力限制在非重叠的 2×2 窗口内,确保每个 token 仅与其三个空间邻居交互以丰富局部上下文。其次,跟随一个下采样与融合块。2×2 PixelUnshuffle 操作将中间表示 Y 重塑为 Z∈RN/4×4d。最后,MLP 将这些连接通道融合回原始维度 d,生成压缩序列 X。
为确保插入此新模块不会破坏 ViT 的预训练表示流形,作者采用参数重用初始化策略。并非随机初始化,D 使用前一层 ViT 层 k 的权重进行初始化。具体而言,注意力投影和 LayerNorm 直接复制,而 MLP 权重构建为模仿独立应用于窗口内每个 patch 的原始前馈网络后取平均值。权重矩阵定义为:
W1=BlockDiag(F1(k),F1(k),F1(k),F1(k)),W2=λ1[F2(k)∣F2(k)∣F2(k)∣F2(k)].此初始化允许微调从预训练流形上或附近开始,避免从头恢复的需求。
在 ViT 内部压缩之后,编码的视觉特征通过 ViT 后 MLP 连接器。该阶段进一步减少 token 数量并将特征投影到语言模型空间。ViT 内部压缩器与 ViT 后连接器的组合实现了端到端 16× 的 token 数量减少。
训练过程遵循四阶段配方以优化模型。首先,在大规模图像 - 文本对上执行视觉 - 语言对齐,仅更新投影器和新的压缩器 D。其次,通过 OCR、文档和图表数据进行知识注入,仅解冻 ViT。第三,在图像 - 文本序列上进行交错训练,促进多图像和长上下文推理。最后,在多样化的通用 VQA、数学和对话任务混合集上应用监督指令微调,以完善模型能力。
实验
针对高分辨率 MLLM 的受控实验表明,基于切片编码通过保留局部性始终优于全局编码,而空间融合 MLP 连接器通过维持显式空间对应关系,证明优于基于查询的采样器。此外,将压缩移至 ViT 管道内部,利用局部窗口注意力和中间层深度的权重重用,在不过度牺牲准确率的情况下大幅降低了计算成本。这些发现共同确立了一种更高效的架构,平衡了视觉编码质量与计算节省。
作者评估了各种 ViT 内部压缩设计,以确定如何在编码器内部有效减少视觉 tokens。结果表明,简单的合并策略(如平均池化或标准 MLP)通常表现不佳或与 ViT 后基线相当,而结合局部窗口注意力和权重重用的设计产生更优越的性能。具体而言,将窗口注意力与重用的 MLP 投影器结合实现了最高的平均准确率,表明保留局部上下文并与预训练权重对齐对于有效早期压缩至关重要。Win-Attn w/ Reused MLP 方法实现了最高平均分,优于 ViT 后基线。诸如 Pixel-Unshuffle MLP 和平均池化等朴素压缩策略通常产生较低或与基线相当的结果。结合窗口注意力的方法往往优于交叉注意力变体和简单 MLP 投影。
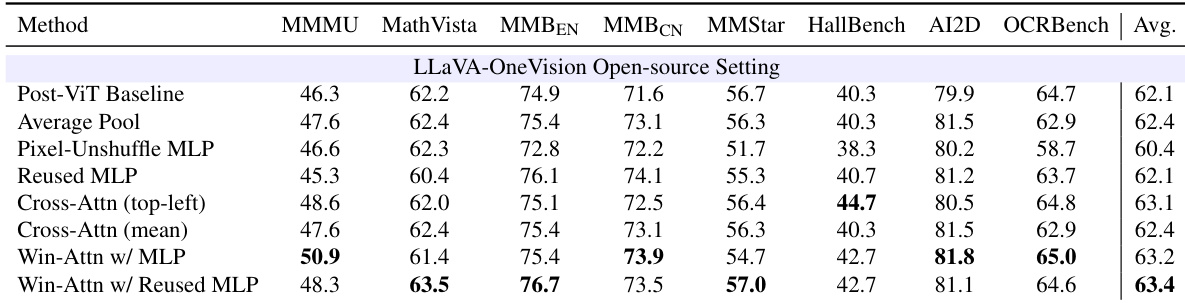
作者评估了朴素的 ViT 内部压缩策略与 ViT 后基线,以评估效率与准确率之间的权衡。结果显示,将压缩移至 ViT 内部大幅降低了计算成本,但平均池化和像素洗牌等简单合并方法无法匹配基线的性能。这表明早期 token 减少需要更复杂的设计以保留表示质量。ViT 内部压缩方法实现了比 ViT 后基线显著更低的计算成本。朴素合并策略导致平均准确率与基线相比出现明显下降。Pixel-unshuffle 表现略优于平均池化,但仍劣于 ViT 后基线。

作者评估了使用交叉注意力的 ViT 内部压缩策略与 ViT 后基线。结果表明,内部压缩显著降低了计算成本,同时保持竞争性准确率,左上角查询策略的表现几乎与基线相当。ViT 内部压缩实现了与 ViT 后基线相比 FLOPs 的大幅减少。左上角查询策略在可比于基线的水平上保持准确率。平均查询策略导致相对于左上角方法性能轻微下降。

作者进行了一项稳健性研究,用 MoonViT 替换标准 SigLIP 2 主干,并在 16x 压缩率下测试替代的更高分辨率切片计划。在这些设置中,基于切片编码始终匹配或优于全局编码,随着训练数据规模扩大,性能差距增加。基于切片编码在所有测试的数据规模和配置中实现了比全局编码更高的平均准确率。所提出方法的性能优势在对细粒度识别要求较高的 OCR 密集型基准测试中最为显著。将训练数据量从 8M 增加到 16M 样本进一步放大了基于切片编码相对于基线的优势。
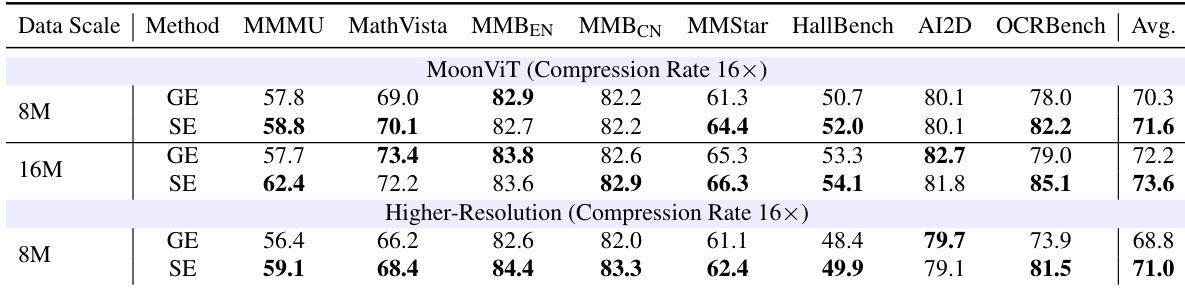
作者评估了基于切片编码相对于全局编码在不同视觉主干和分辨率设置下的稳健性。结果表明,在所有测试配置中,包括 MoonViT 主干在不同数据规模下和更高分辨率切片计划下,基于切片编码始终优于全局编码。使用 MoonViT 主干在不同数据规模下,基于切片编码保持相对于全局编码的性能优势。采用更高分辨率切片计划进一步扩大了有利于基于切片编码的性能差距。基于切片编码的有效性推广到不同的视觉编码器架构和训练数据量。
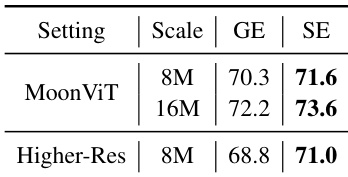
该研究评估了 ViT 内部压缩设计和基于切片编码策略与 ViT 后基线,以平衡效率与准确率。发现表明,朴素合并策略会降低性能,而结合局部窗口注意力和权重重用保留了表示质量以获得更优越的结果。此外,稳健性评估显示,基于切片编码在不同架构和数据规模下始终优于全局编码,随着训练量增加优势增大。