Command Palette
Search for a command to run...
SlimQwen:探索大型混合专家(MoE)模型预训练中的剪枝与知识蒸馏
SlimQwen:探索大型混合专家(MoE)模型预训练中的剪枝与知识蒸馏
Shengkun Tang Zekun Wang Bo Zheng Liangyu Wang Rui Men Siqi Zhang Xiulong Yuan Zihan Qiu Zhiqiang Shen Dayiheng Liu
摘要
结构化剪枝和知识蒸馏(KD)是压缩大语言模型的典型技术,但在预训练规模下如何应用这些技术,尤其是针对最新的高混合专家(MoE)模型,目前尚不明确。在本研究中,我们系统地探讨了大规模预训练中的 MoE 压缩问题,重点关注三个关键问题:剪枝是否能比从头训练提供更好的初始化效果,专家压缩的选择如何在持续训练后影响最终模型,以及哪种训练策略最为有效。我们的主要发现如下:首先,在深度、宽度和专家压缩方面,对预训练的 MoE 进行剪枝始终优于在相同训练预算下从头开始训练目标架构。其次,不同的单次专家压缩方法在大规模持续预训练后会收敛到相似的最终性能。受此启发,我们提出了一种简单的部分保留专家合并策略,该策略在大多数基准测试中提升了下游性能。第三,将 KD 与语言建模损失结合的效果优于单独使用 KD,特别是在知识密集型任务上表现更佳。我们进一步提出了多标记预测(MTP)蒸馏方法,这种方法带来了持续的性能提升。
一句话总结
SlimQwen 系统性地研究了大规模混合专家模型预训练中的剪枝与蒸馏,证明了对预训练模型进行剪枝优于从头训练,引入了部分保留专家合并策略,并结合知识蒸馏与语言建模损失以及多 token 预测蒸馏,以提升各种基准测试上的下游性能。
核心贡献
- 在深度、宽度和专家维度上,对预训练 MoE 模型进行结构化剪枝提供了比从头训练更强的初始化,预算相同。这通过将 Qwen3-Next-80A3B 压缩为 23A2B 模型得到证明。
- 引入了一种部分保留专家合并策略,以提升包括通用推理、数学和编程在内的各种基准测试上的下游性能。该方法的动机是观察到不同的单次专家压缩方法在大规模持续预训练后收敛到相似的最终性能。
- 多 token 预测蒸馏通过监督多个未来 token 扩展了标准的下一 token 蒸馏。将此方法与语言建模损失相结合可带来一致的提升,特别是在知识密集型任务上。
引言
混合专家架构主导了大型语言模型的扩展,但其预训练和推理成本仍然高昂。虽然结构化剪枝和知识蒸馏能有效压缩稠密模型,但在预训练规模上将这些技术应用于 MoE 系统会在专家处理方面带来独特的挑战。先前的研究通常评估单次压缩,未考虑大规模持续预训练期间的性能恢复。作者系统性地研究了 MoE 压缩,发现剪枝预训练模型提供了优于从头训练的初始化。他们提出了一种部分保留专家合并策略和多 token 预测蒸馏以增强下游性能。此外,该研究表明渐进式剪枝计划比单次方法产生更好的优化轨迹,使得在保留竞争性基准测试结果的同时压缩 Qwen3 模型成为可能。
方法
作者利用混合注意力混合专家(MoE)架构作为其压缩框架的基础。基础模型称为 Qwen3-Next,由 L 层组成,其中每个块集成了门控 DeltaNet 或门控注意力模块以及 MoE 模块。MoE 模块包含 nrouted 个路由专家和 nshared 个共享专家。每个专家实现为 SwiGLU MLP,定义为:
Expert(x)=(SiLU(xW1e)⊙(xW2e))W3e其中 W1e,W2e∈Rd×dff 且 W3e∈Rdff×d。路由器为路由专家生成 top-k 门控分数,而单独的门控处理共享专家。最终 MoE 输出组合了这些贡献:
MoE(x)=e=1∑nroutedze(x)Experte(x) + s=1∑nsharedzs(x)Experts(x)为了减小模型规模,作者引入了跨三个维度的结构化剪枝:深度、宽度和专家。深度剪枝涉及直接移除模型的最后 N 层。宽度剪枝通过校准数据集上的激活统计量估计重要性来减少隐藏维度。第 k 个隐藏维度的重要性计算如下:
Inorm(k)=[L∑i=0LMean(RMSNorm(X))]k专家压缩采用频率、软 logit 和路由器加权专家激活(REAP)等指标来量化专家重要性。为了平衡知识保留和整合,提出了一种部分保留合并策略。该方法保留重要性分数最高的目标专家的一半保持完整,而剩余的目标专家通过将丢弃的专家合并到选定的基础中构建。合并过程公式化为:
E~i=Ii+Im(i)IiEi+Ii+Im(i)Im(i)Em(i)结构化剪枝的整体框架及随后的渐进式蒸馏流程如下所示:

在结构压缩之后,作者采用多 token 预测(MTP)蒸馏策略来恢复性能。MTP 模块预测不同深度 k 的未来 token。对于第 i 个输入 token,深度 k 处的表示通过结合前一深度表示与未来 token ti+k 的嵌入来计算:
hik=Mk[RMSNorm(hik−1);RMSNorm(Emb(ti+k))]训练目标结合了标准语言建模、知识蒸馏及其 MTP 变体。总损失函数使用超参数 λ 和 β 平衡这些组件:
L=(1−λ)LLM+λLKD+β((1−λ)LMTP−LM+λLMTP−KD)为了减轻激进压缩期间的知识损失,利用了渐进式剪枝和蒸馏计划。该过程将结构剪枝与固定 token 蒸馏阶段交错进行。作者评估了三种具体计划:深度优先,优先在宽度缩减之前进行层缩减;宽度优先,首先减少隐藏维度;以及联合,在初始阶段同时减少深度和宽度的一半,然后在第二阶段完成缩减。
实验
实验评估了压缩混合 MoE 架构在各种基准测试上的表现,以验证剪枝初始化和专家压缩策略的有效性。结果表明,与随机初始化相比,剪枝提供了更好的起点,加速了收敛,而渐进式压缩和部分专家保留通过保留更多预训练知识,始终优于单次方法。此外,结合多 token 预测蒸馏与标准语言建模损失增强了骨干性能和推测解码效率。
作者评估了剪枝 MoE 模型的各种训练损失配置,以确定持续预训练的有效方案。结果表明,与单独使用蒸馏相比,结合下一 token 预测知识蒸馏与语言建模损失提高了知识密集型基准测试的性能。此外,整合多 token 预测知识蒸馏带来了一致的收益,综合目标在主要基准测试上取得了强劲结果。结合知识蒸馏与语言建模损失在知识基准测试上优于纯蒸馏。纳入多 token 预测知识蒸馏导致各种评估任务上的性能一致提升。完整训练目标在 MMLU 基准测试上实现了所测试配置中的最高性能。

该研究调查了与随机初始化相比,剪枝是否为大规模预训练中的 MoE 模型提供了更好的初始化。结果表明,使用知识蒸馏初始化的剪枝模型始终优于随机初始化和使用标准语言建模损失的剪枝模型,跨越多个基准测试。这种方法允许紧凑模型恢复教师模型性能的很大一部分,验证了结构化剪枝在保留任务关键权重方面的有效性。结合知识蒸馏的剪枝初始化在所有评估的基准测试上显著优于随机初始化。带有蒸馏的剪枝模型在学生配置中实现了最高的平均分,最接近教师模型的性能。使用知识蒸馏与剪枝模型产生的结果优于对相同剪枝架构应用标准语言建模损失。

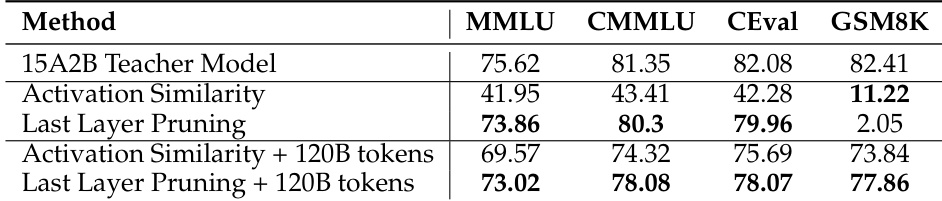
作者比较了 MoE 模型的剪枝策略,具体为激活相似性与最后一层剪枝,均在 120B tokens 训练前后。结果表明,最后一层剪枝提供了比激活相似性更强的初始化,即使不重新训练也能保留通用知识能力。此外,训练剪枝模型使其能够恢复数学推理技能并达到接近原始教师模型的性能水平。最后一层剪枝在剪枝后立即保留强大的通用知识性能,而激活相似性导致分数显著下降。使用 120B tokens 重新训练剪枝模型成功恢复了在剪枝阶段几乎丧失的数学推理能力。使用蒸馏训练的最终剪枝模型在所有评估的基准测试上实现了与较大教师模型相当的结果。
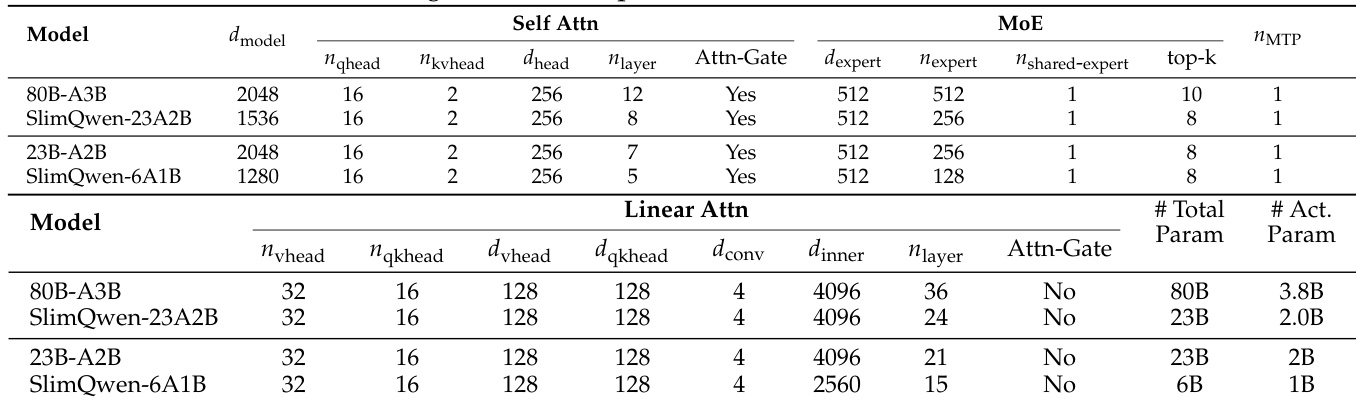
该表展示了基础模型及其相应剪枝 SlimQwen 变体的架构规范,说明了模型压缩的结构化方法。剪枝配置通过减少注意力层的深度和减少混合专家模块中的专家数量来实现效率。与基础对应模型相比,剪枝模型在总参数和活跃参数方面均表现出显著下降。结构压缩涉及减少 Self-Attention 和 Linear Attention 组件的层数。通过减少专家总数和每个 token 的活跃专家数量来降低专家容量。
作者比较了一阶段剪枝与渐进式剪枝策略,以优化压缩模型的训练。结果表明,渐进式方法在各种基准测试上始终优于一阶段基线。具有特定两阶段 token 计划的深度优先策略实现了最佳整体性能。渐进式剪枝策略在各种基准测试上始终优于一阶段基线。具有两阶段 token 计划的深度优先策略实现了最佳整体性能。增加训练阶段的粒度并未在标准两阶段方法之上提供额外的性能收益。

作者评估了训练损失配置、初始化方法和剪枝计划,以优化压缩混合专家模型。结果表明,结合知识蒸馏与语言建模损失并利用剪枝初始化,显著优于标准基线和随机初始化。此外,最后一层剪枝比激活相似性更好地保留通用知识,渐进式剪枝策略比一阶段方法产生更优越的结果,使紧凑模型能够在主要基准测试上恢复教师级性能。